0. Background
When the server side needs to support user experience across multiple front-end devices, it often faces the situation where existing APIs are tightly coupled with a certain end's UI.
For example, APIs designed for PC pages need to support mobile devices, but it's found that existing interfaces from design to implementation are strongly related to desktop UI display requirements, unable to simply adapt to mobile display requirements.
I. Current Situation
When one back-end API layer serves multiple front-ends (PC, mobile, etc.), it generally supports one end first, then adds more features to support other ends.
It's tempting to design a single back-end API to support all clients with a reusable API.
If multiple front-end UIs require similar APIs, this approach has no problems (slightly enhancing existing APIs can support another front-end experience), but mobile UI experience is usually different from PC.
Valuable services support many variations in clients, such as mobile versus web and different forms of web interface.
For example:
-
Small screen space, less data can be displayed
-
Establishing multiple connections increases power consumption, data aggregation on the front-end is costly
-
Interaction methods differ greatly, back-end APIs need to support different features. For example, PC fills forms, mobile scans QR codes...
Therefore, mobile usually requires:
-
Different (or fewer) API calls, such as aggregation
-
Display different (or less) data
Additionally, one back-end API usually needs to support multiple front-end applications. At this point, a single back-end may become a bottleneck for version iteration because each version involves huge workload (integrating N front-end applications). This leads to a large independent back-end team responsible for providing APIs to multiple front-end teams, then each front-end team needs to communicate changes with that team, while that team needs to balance priority of requirements from multiple front-end teams... subsequently facing problems like inefficient cross-team collaboration, difficult resource coordination, etc.
II. Origin of BFF
Due to all the above, we no longer hope for one large back-end to uniformly provide API support for multi-end experiences, but instead give each user experience a corresponding back-end (one backend per user experience), called Backend For Frontend (BFF), translated as user experience adaptation layer.
Consequently it's often best to define different back-end services for each kind of front-end client.
Conceptually, split each front-end application into two parts: client application and server-side part (BFF). Among them, BFF is oriented to specific user experience, responsible for implementation and maintenance by the front-end team implementing that part of UI (i.e., UI and corresponding BFF are responsible by the same team).
These back ends should be developed by teams aligned with each front end to ensure that each back end properly meets the needs of its client.
Advantages of the same team include:
-
Easier to define or adjust APIs according to UI
-
Simplifies release process for client and server (fewer dependencies)
-
One BFF focuses on only one UI, smaller and more flexible
From a service perspective, BFF actually limits the number of consumers (referring to front-end applications) supported by a single service, thereby making them easier to use (more aligned with front-end needs) and change, and helping teams developing front-end applications retain more autonomy:
The simple act of limiting the number of consumers they support makes them much easier to work with and change, and helps teams developing customer-facing applications retain more autonomy.
III. Specific Implementation
Requiring BFF and user experience to be one-to-one means splitting one large back-end into multiple small back-ends.
Granularity
Since splitting is needed, what should be the basis for division? To what degree of granularity?
It's not hard to think of 3 splitting methods:
-
User Experience Level (UI Level): Each UI interaction corresponds to one BFF, for example, 1 for PC, 3 for mobile (for example, if small-screen phones, medium-screen phones, and large-screen phones have very different UI interactions, it's necessary to split into 3 BFFs)
-
Device Level: Each front-end device corresponds to one BFF, such as PC, Android, iOS, watches, car systems, etc.
-
Team Level: Each front-end team corresponds to one BFF, divided according to existing organizational structure
It's recommended to split at user experience level, because if device-level splitting has similar UI across multiple devices, interfaces are likely directly reusable, no need to split, and organizational structure can be flexibly adjusted, should not restrict technical solutions.
Connecting Downstream Services (Microservices)
Each BFF needs to connect to multiple downstream services, so there are inevitably several problems:
-
How to connect to multiple downstream services with different technology stacks?
-
How to manage and combine these calls?
-
When a certain call fails, how to ensure availability?
Unified RPC protocol can smooth out differences in downstream service technology stacks; for asynchronous call management, event mechanisms like RxJava, Finagle can simplify these asynchronous process controls; availability issues when partial calls fail can be resolved through fault tolerance at BFF layer, while front-end ensures acceptable incomplete response content.
Reuse Issues
After splitting, redundant code easily arises between multiple BFFs, especially some common back-end logic (such as authorization, authentication, rate limiting, etc.)
To eliminate code redundancy between BFFs, generally two approaches are used:
-
Either merge multiple BFFs into one
-
Or add an Edge API service layer above BFF
Merging multiple BFFs returns to the original problem, because we split for flexibility, then merge for reusability... wasted effort. Another option is to add an gateway service (Edge API service) layer, put common logic there, letting BFF focus on business logic:
It validates and authenticates incoming requests; it enforces rate limits to protect the platform from undue load, and it routes requests to the appropriate upstream services. Factoring these high-level features into the edge service is a huge win for platform simplicity.
Returning to the reuse problem itself, we want to eliminate redundancy without causing tight coupling between BFFs due to extracting reusable code, so there's a compromise attitude: tolerate redundancy between BFFs, eliminate redundancy within single BFF. That is, allow a certain degree of redundancy between BFFs.
Of course, the premise of reuse is that multiple BFFs have the same technology stack, then identify redundant parts and refactor them. Specifically, when reaching the stage of extracting common parts, there are several options:
-
Extract common library
-
Extract as independent service
-
Sink to downstream services
But common libraries are usually the main source of coupling, for example, common logic for calling downstream services can cause coupling between BFFs. The independent service approach is relatively better, can further conceptualize new services into domain models. Similarly, common logic can also be sunk to downstream services, turning peer downstream services into a dependent tree structure.
No matter how to solve the reuse problem, it should only be done when reuse is necessary, general principle is:
Creating an abstraction when you're about to implement something for the 3rd time.
IV. Application Scenarios
Compared to mobile devices, PC devices have good enough performance, so can we directly call multiple downstream services (cost not very high), bypassing BFF?
Actually, compared to downstream services directly facing front-end applications, the significance of BFF lies in being suitable for implementing:
-
Server-side templates
-
Data aggregation (merging multiple interface calls), orchestration (formatting to what front-end wants), trimming (removing information front-end doesn't need)
-
Caching results of aggregated calls
-
Providing specific features for a certain UI experience (such as mobile)
-
APIs for third-party use, facilitating maintenance of logic added due to third-party restrictions
Because BFF is a layer above downstream services, and refined to user experience granularity, it's more flexible than downstream services, especially suitable for differentiated scenarios like providing custom APIs for third parties.
V. Industry Practice
According to BFF concept, split the large back-end by front-end experience, as shown below:
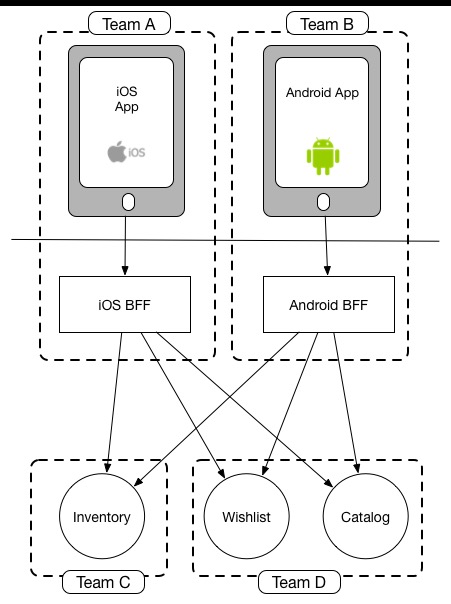
In specific practice, BFF is usually not as shown in the diagram, main changes include:
-
Split BFF by business line
-
Add a gateway layer, responsible for implementing routing, authentication, monitoring, rate limiting/circuit breaking, security, etc.
BFF split by business line is more like business microservices built on downstream basic services, except these microservices are developed and maintained by front-end teams corresponding to that business. Broadly, can be understood as finer-grained BFF, i.e., each business corresponds to one BFF (no longer divided by user experience differences).
Gateway layer is responsible for implementing common boundary services, such as authentication, rate limiting, etc., letting BFF focus more on business-related parts:
Front-end Experience
--------------------
^ ^
| |
Gateway
------------
BFF BFF
----- -----
^ ^ ^ ^
/ \ / \
--------------------
Downstream Services
Even more, split the gateway layer to correspond one-to-one with BFF:
Front-end Experience
--------------------
^ ^
| |
Gateway Gateway
----- -----
BFF BFF
----- -----
^ ^ ^ ^
/ \ / \
--------------------
Downstream Services
P.S. Additionally, there are approaches that don't introduce BFF, but only add a forwarding service layer to solve data aggregation, orchestration, trimming, etc., similar to GraphQL, but容易出现 meaningless data pass-through, so generally not fully covered (not all data requests go through forwarding service):
Front-end Experience
--------------------
^ ^
| |
Forwarding Service |
-------- |
^ ^ |
/ \ |
--------------------
Downstream Services
Exploration
In practice, there are mainly 3 exploration directions for BFF:
-
Stability: Ensure BFF reliability, such as through logs, error analysis, monitoring, alerting, etc.
-
Isomorphism: Let BFF and front-end experience use the same technology stack, such as Node-based isomorphic solutions
-
Integration: On one hand provide mock solutions for downstream services, on the other hand allow isomorphic and non-isomorphic applications to coexist
After all, in BFF mode, front-end developers are required to master a certain degree of full-stack knowledge (such as server-side skills, operations, security, etc.), so naturally want to improve development experience through isomorphic or integration solutions, lower the threshold, make technology imperceptible.
Hope more and more developers no longer need to worry about processes, builds, environments, deployments, etc., hope to achieve Techless, let every developer code quietly and happily.
VI. Advantages
Separation of Concerns
The biggest benefit of BFF mode is separation of concerns, downstream services can focus on business domain models, front-end UI focuses on user experience:
Back-end can focus on business domain, think more from domain model perspective, page-view data is left to front-end full-stack engineers to handle. Domain models and page data are two thinking modes, can be well decoupled through BFF, making each more professional and efficient.
From a division of labor perspective:
BFF mode is not only a technical architecture, from a social division of labor perspective, BFF is more of a multi-value-oriented layered architecture, each layer has good space to perform.
Autonomy
From a team perspective, main problems with traditional front-end and back-end separation are:
-
Service scalability and complexity
-
Many-to-one relationship between front-end and back-end teams, because front-end teams inevitably need subdivision (due to technical implementation differences, need specialists)
-
Cross-team collaboration costs, for example, during front-end UI development, back-end APIs may change (exists cross-team communication coordination costs)
In BFF mode, API owner is the front-end team responsible for implementing corresponding user experience, that is, front-end teams own API autonomy, can quickly adjust changes.
Another benefit of front-end and BFF team integration is, can flexibly choose whether to implement on client or service (for example, highly common ones implemented by service, or even for quick release approval can be implemented by service), without needing cross-team coordination.
No comments yet. Be the first to share your thoughts.