Preface
To solve the scalability problem at the database layer, we have already discussed two solutions:
-
Replication: Scale from single database to multiple databases to carry more requests
-
Partitioning: Split single database (table) into multiple databases (tables), breaking the performance bottleneck of single database
With the support of (multi-machine) multi-database multi-table, surging requests and data volume are no longer problems. However, besides data volume, there is another factor that extremely affects single database performance—the way data is organized
For example, in relational databases, data entities are described using two-dimensional tables (called entity tables):
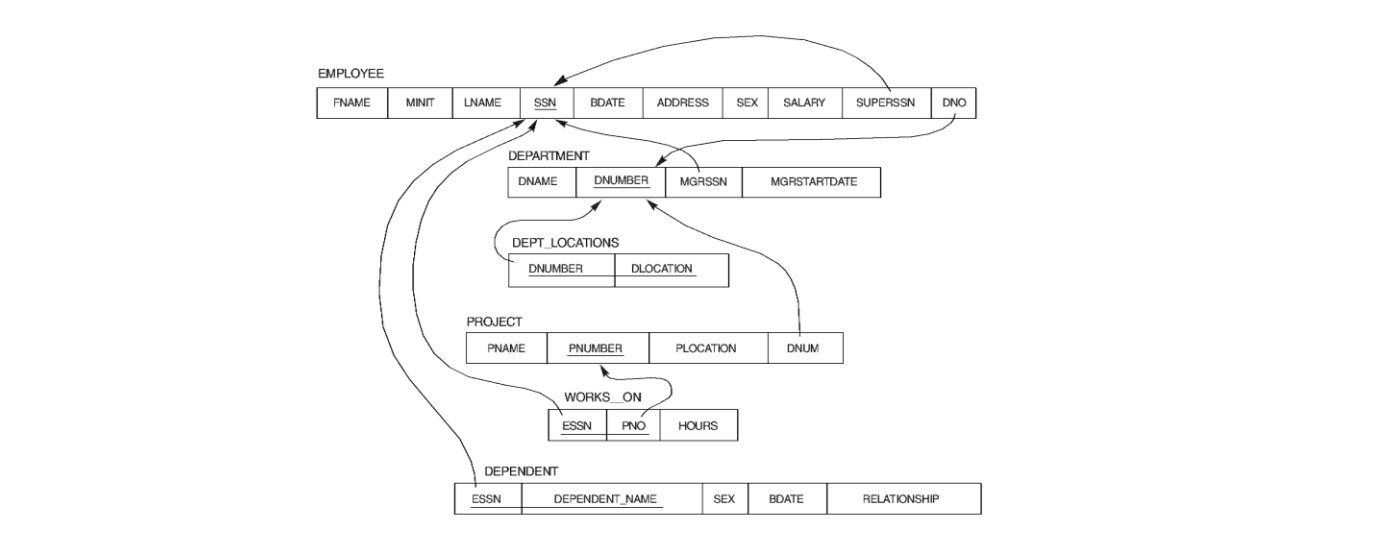
Complex relationships between entities (many-to-many) are also described through two-dimensional tables (called relationship tables):
Therefore, often need to join multiple tables to get target information. The more complex the relationships, the worse the read performance, and ultimately like data volume, it becomes a single database performance bottleneck, constraining the scalability of the database layer
So, for relational databases, is there a way to further improve data read performance?
Yes, (to a certain extent) change the way data is organized, i.e., Denormalization
I. Normalization
Before discussing denormalization, it's necessary to first clarify what normalization is, what are we denormalizing?
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
Normalization (Database normalization) is the process of organizing data models according to a series of Normal forms requirements, with the purpose of reducing data redundancy and improving data integrity
Imagine, if the same information is repeated in multiple rows, and unrelated information is also put together in the same table, it's easy for some abnormal situations to occur:
-
Update anomaly: Only updating a single row will cause logical inconsistency
-
Insert anomaly: Cannot insert only partial information unless leaving other columns empty first
-
Delete anomaly: Deleting partial information may affect other unrelated information
To avoid these abnormal situations, people have proposed some constraint rules, i.e., database design normal forms
II. Database Design Normal Forms
-
1NF: First normal form requires that the value of each field in the data table cannot be further divided
-
2NF: Second normal form On the basis of satisfying 1NF, requires that all non-primary attributes completely depend on their primary key
-
3NF: Third normal form On the basis of satisfying 2NF, requires that all non-primary attributes do not transitively depend on any primary key
P.S. In addition, there are BCNF, 4NF, 5NF, etc., see Normal forms for details
Analogous to the application layer, design normal forms are equivalent to design patterns at the data layer, decoupling data tables, making single table information more cohesive, with clear boundaries and clearer dependencies
We generally call relation schemas that satisfy 3NF as Normalized, which can avoid the insert, update, and delete anomalies mentioned above in most cases. However, while solving these problems, normalization also brings some other problems
III. Disadvantages of Normalization
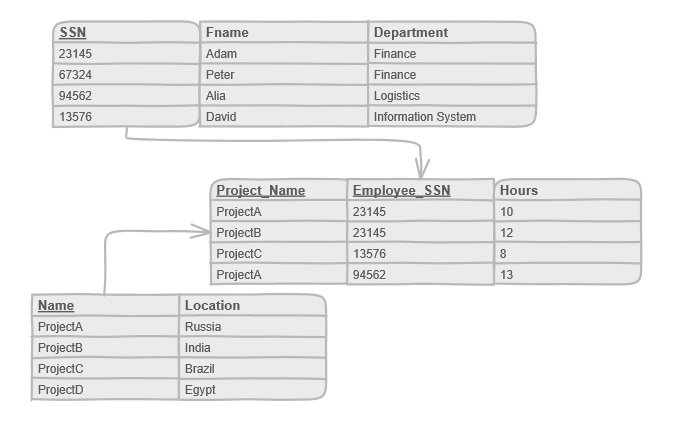
Under the constraints of these design normal forms, related information is stored in different logical tables:
A normalized design will often "store" different but related pieces of information in separate logical tables (called relations).
For example:
[caption id="attachment_2131" align="alignnone" width="625"]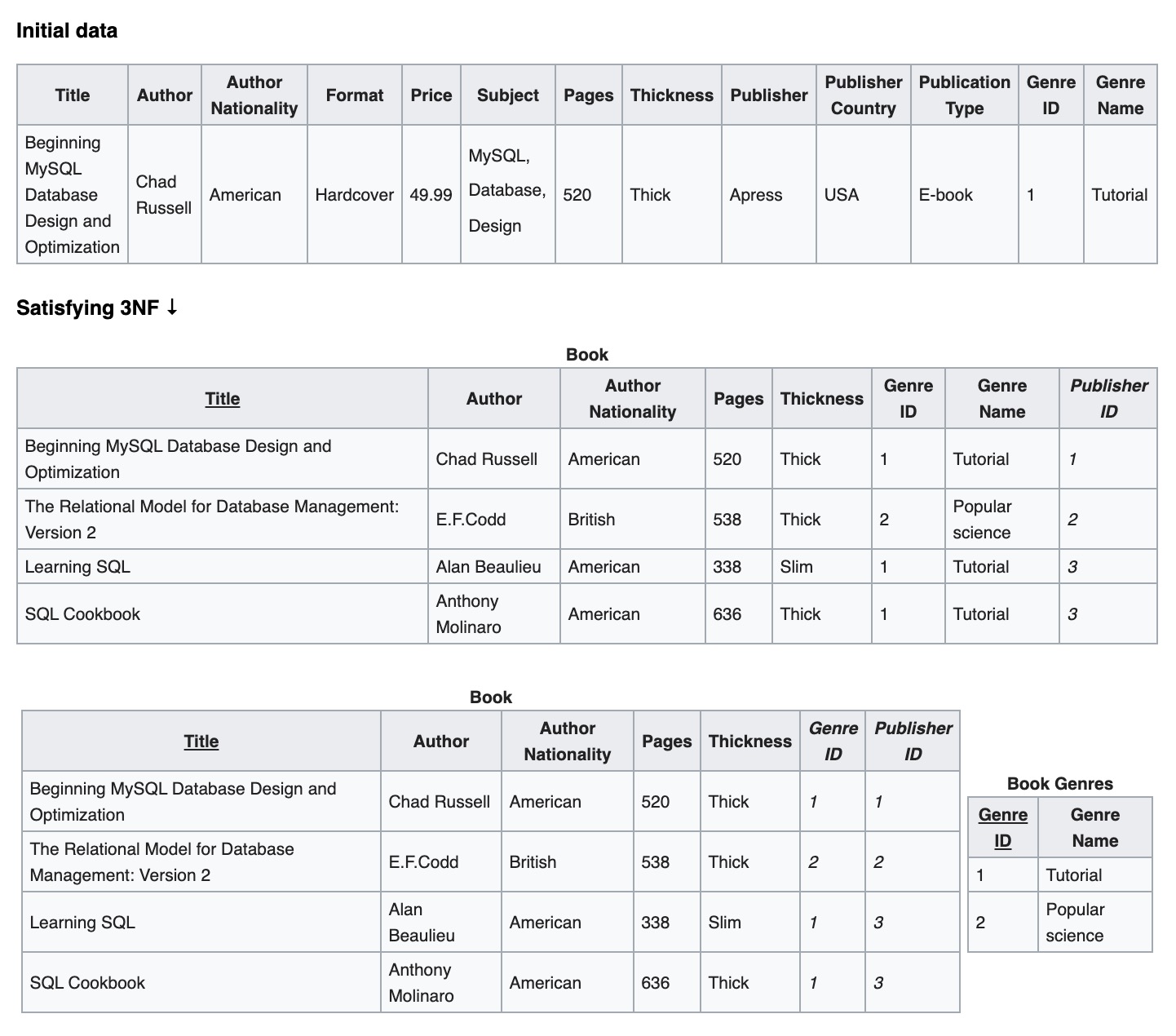 3NF[/caption]
3NF[/caption]
Resulting in often needing to join multiple tables (join operation). The more complex the relationships, the slower the join queries:
If these relations are stored physically as separate disk files, completing a database query that draws information from several relations (a join operation) can be slow. If many relations are joined, it may be prohibitively slow.
So, is there a way to improve query performance?
Yes. Introduce redundancy:
-
Allow DBMS to store additional redundant information, such as indexed views, materialized views, but still follow design normal forms
-
Add redundant data, reduce
joinoperations, break design normal forms (i.e., Denormalization)
IV. Denormalization
So-called denormalization is a performance optimization strategy for databases (relation schemas) that follow design normal forms:
Denormalization is a strategy used on a previously-normalized database to increase performance.
P.S. Note, denormalization does not equal unnormalization (Unnormalized form). Denormalization must occur on the basis of satisfying normal form design. The former is equivalent to first following all rules, then making local adjustments, intentionally breaking some rules, while the latter disregards rules entirely
By adding redundant data or grouping data, sacrificing some write performance in exchange for higher read performance:
In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.
Under the constraints of design normal forms, there is no redundant information in data tables (a certain data is only stored in a certain cell of a certain table). To get certain data may require a series of cross-table queries, thus read operation performance is poor, but write operations are fast, because when updating data only need to modify one place
Denormalization is to break this constraint, put certain data in multiple places, to speed up data retrieval:
The opposite of normalization, denormalization is the process of putting one fact in many places.
Specific Operations
Specifically, common practices include:
-
Store some derived data: Similar to putting computed properties into Redux Store, store results that need frequent repeated calculations. For example, in a one-to-many relationship, store the count of "many" as an attribute of "one"
-
Pre-joined summary tables: Join tables that need frequent
joinin advance -
Use hardcoded values: Directly hardcode constant values (or infrequently changing values) from dependency tables into the current table, thereby avoiding
joinoperations -
Incorporate detail information into main table: For detail tables with small data volume, can put all/partial detail information into the main table to avoid
joinoperations
P.S. For more information about specific practices of denormalization, see When and How You Should Denormalize a Relational Database
V. Cost of Denormalization
But unless necessary, generally not recommended to denormalize, because the cost is high:
-
Lost data integrity guarantee: Breaking normal forms means the update, insert, delete anomaly problems previously solved through normalization will reappear. That is, consistency of redundant data must be guaranteed by DBA themselves, unlike indexed views etc. which are guaranteed by DBMS
-
Sacrificed write speed: Since denormalization introduces redundant data, need to modify multiple places when updating. But most scenarios are read-intensive, slower writes are not a big problem
-
Wasted storage space: Storing unnecessary redundant data naturally wastes some storage space, but space-for-time is generally acceptable (after all, memory, hard disk and other resources have become relatively cheap)
P.S. Generally ensure consistency of redundant data through constraint rules (constraints), but these rules will offset some of the benefits
No comments yet. Be the first to share your thoughts.