Preface
To improve database processing capability, we expanded a single database into multiple databases, and ensured consistency of multiple data copies through update synchronization mechanism (i.e., Replication). In this way, the database scaling problem seems to have been smoothly solved.
However, under the Replication solution, each database holds a complete copy of data, providing create, read, update, delete services based on full data, the performance bottleneck of a single database still exists, and will become a key factor limiting system scalability.
1. Performance Bottleneck of Single Database
Hardware resources of a single machine are limited, so the processing capability of a single database is also limited:
-
Limited capacity: Data volume may be so large that a single database cannot accommodate it
-
Limited performance: Read/write performance of a single database is also affected by data volume, queries/updates become slower and slower
Simply adding machines/databases obviously cannot directly solve the performance problem of a single machine/single database, unless we further break the database boundaries and split a single database into multiple databases (not just replicate multiple copies).
P.S. Theoretically, Web application layer also faces the same problem, but we've never heard of a Web service so large that it cannot be deployed on a single machine. This is because Web services consider responsibility division and decoupling from the initial design, so that each part can be independently deployed and scaled. This has been the case since SOA (Service-Oriented Architecture, including variants like Microservices) 20 years ago.
2. Partitioning
To avoid single database performance becoming a bottleneck for system scalability, we usually split a logical database (or its constituent elements, such as data tables) into separate independent parts. This approach is called Partitioning:
A partition is a division of a logical database or its constituent elements into distinct independent parts.
(From Partition (database)
Just like splitting a monolithic application into a set of small services in microservices architecture, we split a single database into a set of (data scale) smaller databases through partitioning, each handling a portion of data, sharing the traffic together. Main advantages include:
-
Scalability: After splitting single database data into multiple databases, system scalability is no longer limited by single database performance, making "unlimited" scaling of database layer possible
-
Performance: Reduced data volume in single database, faster data operations, even allowing parallel operations across multiple databases
-
Security: Can adopt stronger security controls for (split out) sensitive data
-
Flexibility: Can adopt different monitoring and backup strategies for different databases (such as by data importance) to reduce costs and improve management efficiency. Or select different storage services for different types of data, such as placing large binary content in blob storage, and more complex data can be stored in document databases
-
Availability: Distributing data across multiple baskets can avoid single point of failure, and single database failure only affects a portion of data
Specifically, there are 3 splitting strategies:
-
Horizontal partitioning (also called Sharding): Split by rows, put different rows into different tables
-
Vertical partitioning: Split by columns, put some columns into other tables
-
Functional partitioning (sometimes also called Federation): Split by business functions, put data belonging to the same Bounded Context in the business domain together
Of course, these 3 strategies are not conflicting and can be used in combination.
P.S. For more information about Domain-Driven Design and Bounded Context, see Decentralized Data Management
3. Horizontal Partitioning
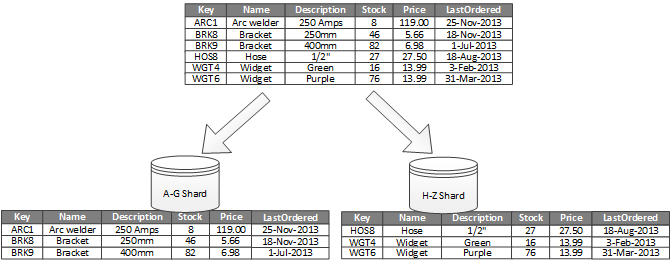
Horizontal partitioning, i.e., Sharding. Each shard is a subset of original data, together constituting the complete dataset:
A database shard is a horizontal partition of data in a database or search engine. Each individual partition (or server) acts as the single source for this subset of data.
(From Shard (database architecture)
Compared with vertical partitioning, the biggest feature of horizontal partitioning is schema remains unchanged:
Each partition is a separate data store, but all partitions have the same schema.
Just like cutting a table horizontally into several pieces, splitting into several small tables, their table structures (fields, etc.) are exactly the same.
This horizontal splitting reduces the data volume that a single database needs to store, and the traffic/operations it needs to carry. On the other hand, it also reduces resource contention, helping to improve performance.
Selection of shard key
In terms of specific operation, the key lies in how to select shard key (by which field's what characteristic to shard), trying to ensure load is evenly distributed across each shard.
Note that even distribution doesn't mean requiring equal data volume for each shard, the focus is on evenly distributing traffic (some shards may have large data volume, but very low access volume).
At the same time, avoid generating "hot spots". For example, partitioning user information by surname initial is actually uneven, because some letters are more common. In this case, partitioning by user ID hash value may be more even.
4. Vertical Partitioning
Another splitting approach is vertical partitioning, splitting some columns (fields) into other tables:
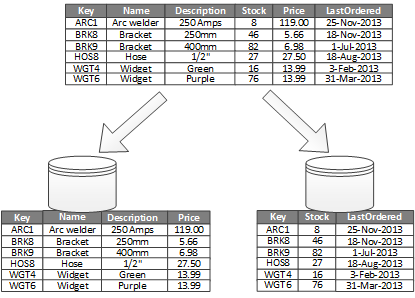
Mostly used to reduce I/O and lower performance costs, for example, separating frequently used fields from infrequently used fields by usage frequency.
Compared with horizontal partitioning, the key advantage of vertical partitioning is splitting information finer, thereby allowing some targeted optimizations, such as splitting out infrequently changing data and putting it in cache, splitting out large binary content like photos for separate storage, or applying targeted security controls to some sensitive data. On the other hand, fine-grained data partitioning can also eliminate some concurrent access and reduce concurrent access volume.
5. Functional Partitioning
In addition, can also split by business functions combined with specific application scenarios:
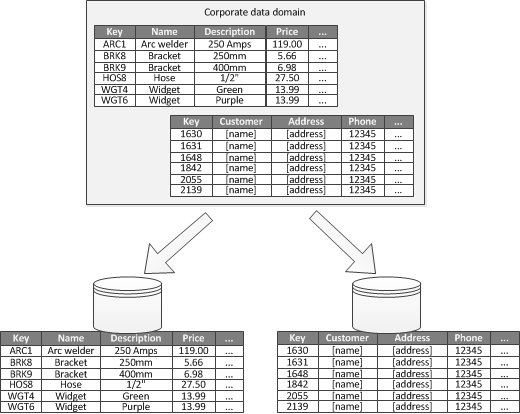
Removing unrelated data (putting closely related data together) helps strengthen data isolation and improve data access performance, such as separating customer information from product inventory information.
6. Cost of Partitioning
Splitting a single database into multiple databases, although able to solve the database scalability problem, also triggers some new problems:
-
Slow join queries: Try to avoid cross-partition joins, or consider parallel queries
-
Slow full table queries: For query operations that need to scan full data, even with parallel optimization it's still slow. Can use vertical partitioning or functional partitioning to locate target partitions and avoid full table queries. As for horizontal partitioning, can maintain a mapping table at application layer to accelerate partition location
-
No support for transaction operations: Hand over transaction operations to application layer for processing
-
Uneven load causing partitioning effect to be greatly reduced: Consider adding monitoring, and regularly adjust based on analysis and prediction
Admittedly, some of these problems don't have very elegant solutions. In practical applications, it's more about trade-offs for specific scenarios.
References
-
[How Sharding Works](https://medium.com/ @jeeyoungk/how-sharding-works-b4dec46b3f6)
No comments yet. Be the first to share your thoughts.