Preface
Theoretically, with a reliable load balancing mechanism, we can easily scale 1 server to n servers, however, if these n machines still use the same database, soon the database will become the system's performance bottleneck and reliability bottleneck
So, how to improve database's processing capability?
From a resource perspective, there are only two approaches:
-
Vertical scaling: Improve single machine configuration (hard disk, memory, CPU, etc.), but will similarly encounter single machine performance bottleneck
-
Horizontal scaling: Add machines, expand from single database instance to multiple instances in quantity
Looking at it this way, it seems we just need to add a few databases, sharing traffic from application layer together, and the expansion from single database to multiple databases is complete:
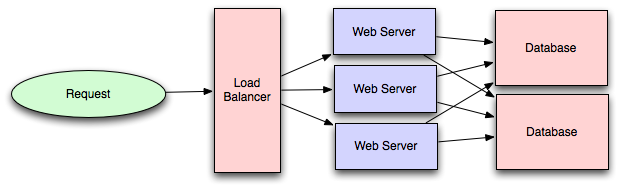
Is it really that simple?
1. Consistency Problem
If the same data exists in multiple copies, then we need to consider how to ensure its consistency
(From Consistency Patterns)
The biggest difference between database and application service is that application service can be stateless (or can extract shared state out, such as putting it in database), while database operations are definitely stateful, when scaling database we must consider data consistency
Specifically, consistency is divided into 3 types, in decreasing order of strictness:
-
Strong consistency: After writing, can read immediately
-
Eventual consistency: After writing, guarantee can eventually read
-
Weak consistency: After writing, may not be able to read
2. Replication
So, expanding from single database to multiple databases, at least requires one data update synchronization mechanism, called Replication:
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
(From Replication (computing))
That is, ensuring information consistency between multiple data copies through replication (write operations). For example, when writing data to database instance A, also need to write the same data to instances B, C, D, etc.
3. Replication Methods
Asynchronous Replication
Specifically, can inform other instances to update data after writing is complete, that is asynchronous replication:
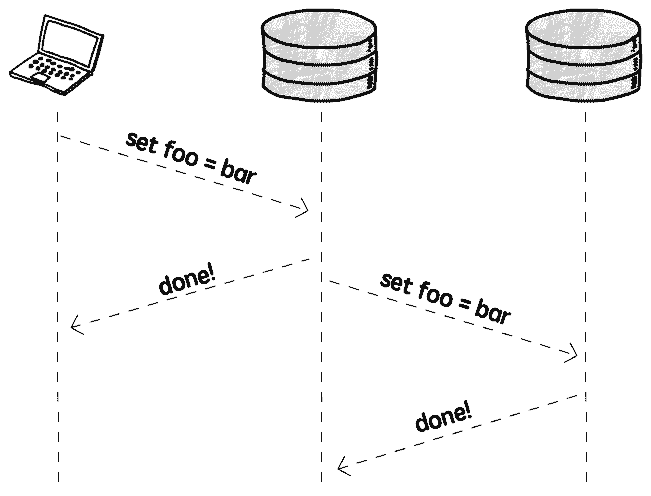
In this mode, client doesn't need to wait for replication operation to complete, no additional performance impact. But the problem is:
-
Risk of data loss
-
Cannot guarantee strong consistency, because there's replication lag
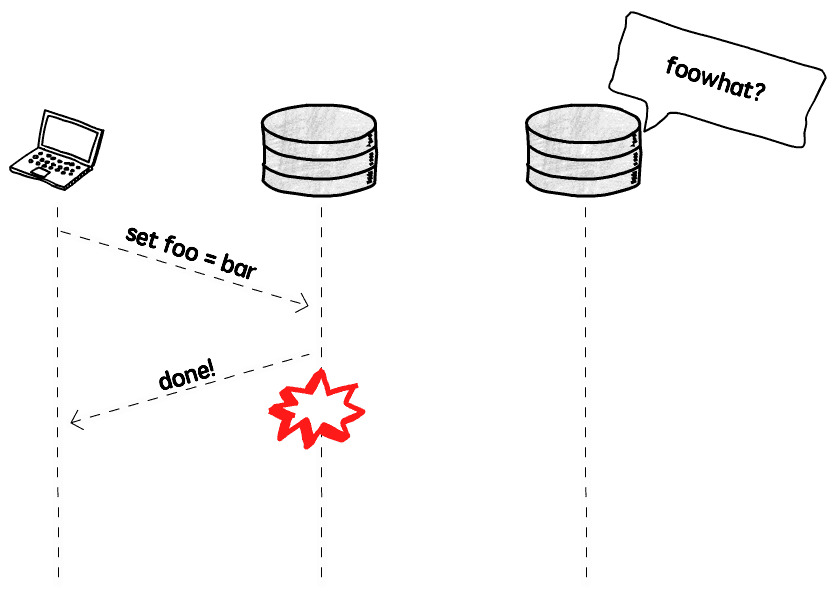
If instance A, after writing, hasn't had time to inform other instances, but goes down itself, data loss will occur:
On the other hand, since replication operation is completed asynchronously, data update is actually lagging:
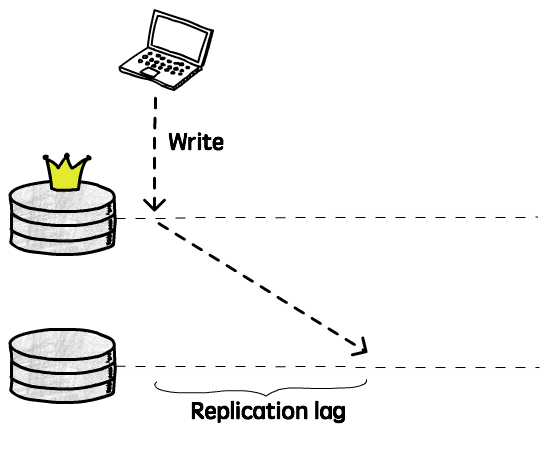
The time difference from when a write operation completes on current instance to when that operation is applied to other instances is called replication lag. During this period, clients reading from other instances still get old data, obviously does not meet strong consistency requirements (can only guarantee eventual consistency)
Synchronous Replication
Wanting to achieve strict consistency requirements, have to consider synchronous replication:
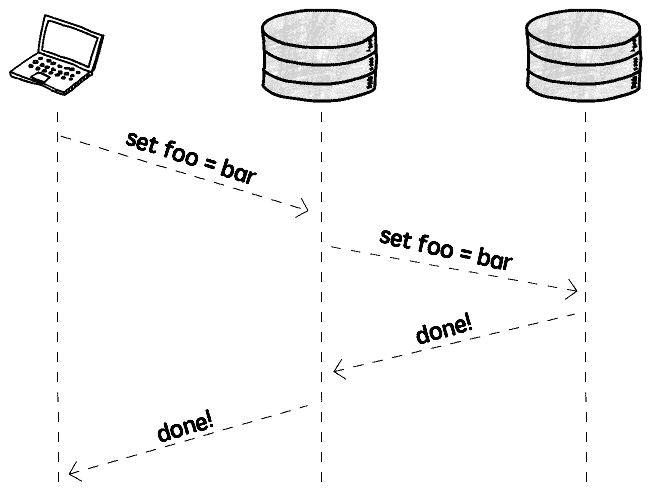
When write operation occurs, immediately synchronize operation to all other instances, only consider write complete after replication is done, to ensure strict consistency
But synchronous replication affects performance and availability, cost is quite high:
-
Performance impact: Need to wait for entire replication process to complete
-
Availability impact: As long as one instance has failure (network, etc.), entire write operation will fail
And the more database instances, the greater these two aspects of impact
Semi-synchronous Replication
Specially, can combine two methods together, called semi-synchronous replication:
Some databases and replication tools allow us to define a number of followers to replicate synchronously, and the others just use the asynchronous approach. This is sometimes called semi-synchronous replication.
That is requiring some database instances to replicate synchronously, rest asynchronously
P.S. PostgreSQL supports this mode
4. Topology Structure
In terms of topology, replication can be divided into 3 categories:
-
Single leader replication
-
Multi leader replication
-
Leaderless replication
Single Leader Replication
That is the most common one-master-multiple-slaves structure:
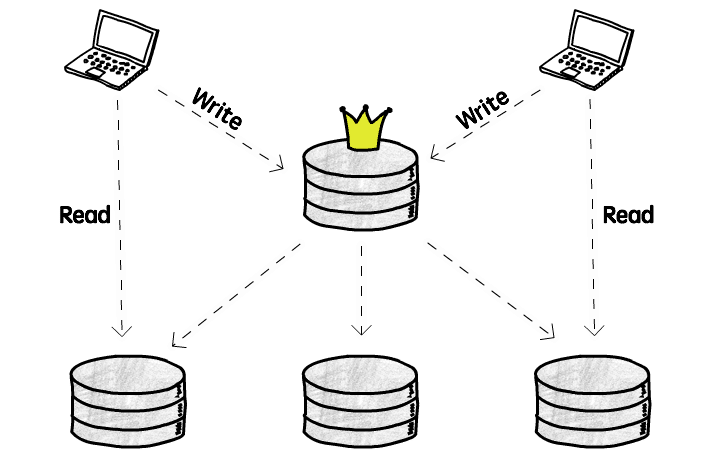
In this structure, write operations (add/delete/modify) only allowed on master database, master database replicates write operations to all other slave databases, slave databases only support read operations (query)
Since all clients write to same database, successfully avoids big trouble of write operation conflicts. But need to note:
-
Write operation pressure is still borne by single database: not suitable for write-intensive applications, but fortunately most applications are read-intensive
-
Latency problem accessing master database: Only one master database, can only be placed in certain geographical location, means initiating write operations (accessing master database) in some regions may have to bear higher latency
Worse situation, if master database goes down, need to immediately select a successor from slave databases, take on master database's responsibilities, ensure this mechanism operates normally
However, this failover strategy is not that easy to implement, difficulties lie in:
-
How to determine master database really went down?
-
How to select new master database?
-
How to route write operations to new master database?
Actually, we cannot distinguish high latency from unavailability, usually consider timeout as unavailable (whether really down or not), then start failover plan, begin selecting new master database
Selecting one is not difficult, key is selected new master database must be recognized by all other slave databases to count (that is Consensus problem), such as pre-determining succession order
After new master database is selected, need to forward all write operations to it, such as adding a distribution layer, to allow routing control
Additionally, if using asynchronous replication, data not yet replicated to other slave databases after old master database recovers may conflict with data written by new master database during downtime, at this point usually adopt LWW (last-write-win) strategy, directly discard old data, but also has risks
Specially, an interesting situation is old master database recovers thinking it's still master database, appears split (Split-brain):
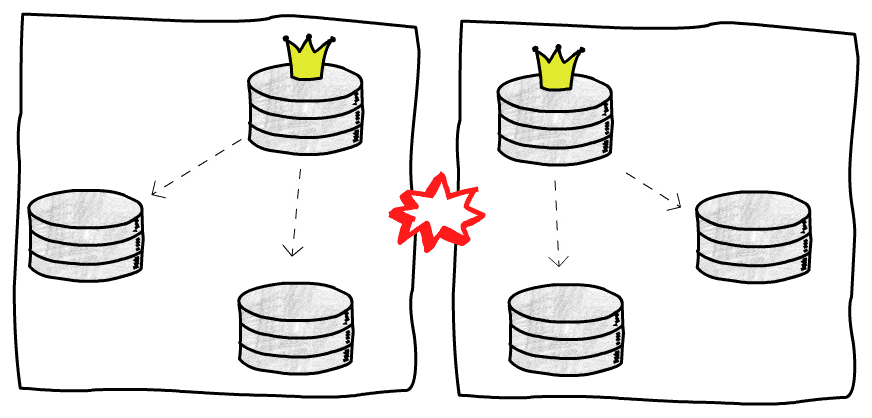
P.S. Network failure can also cause this situation, for example network failure between two clusters, cannot access each other, both think other team is down, so each starts election
Simple handling method is STONITH (Shoot The Other Node In The Head), once discovering multiple master databases exist, directly stop one
Multi Leader Replication
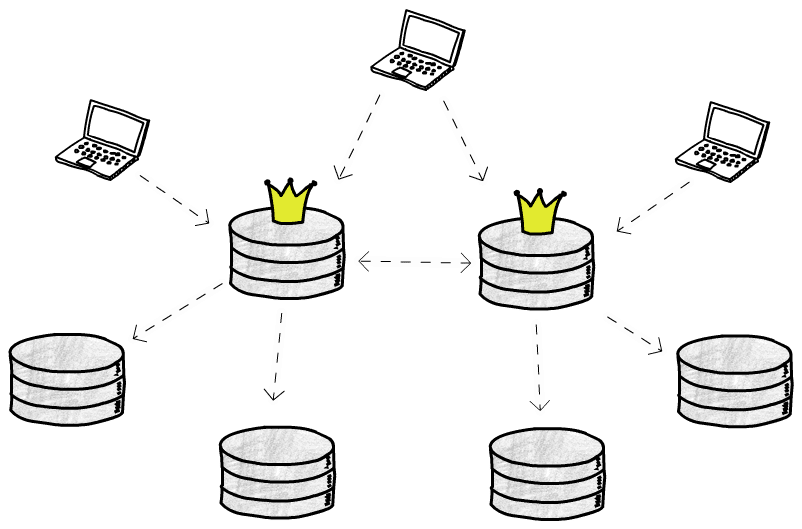
Now have multiple writable master databases, can share write operations, can also deploy in multiple locations, single leader structure's 2 problems are easily solved. However, big trouble appears
Since write operations can simultaneously occur on (asynchronously replicated) multiple databases, we must consider how to resolve write conflicts. Generally there are 3 approaches:
-
Avoid conflicts: Such as storing by content characteristics in separate databases, mutually independent, for example for domestic and foreign two master databases, if can guarantee all write operations to domestic data can land on domestic master database, all write operations to foreign data can land on foreign master database, then no conflicts exist
-
LWW (last-write-win) strategy: Attach timestamp to each write operation, only keep latest version
-
Let user resolve: Record conflicts, application prompts to user, user decides which one to keep
P.S. Some databases (such as CouchDB) support writing all conflict values, and return a series of values when reading
Additionally, another difficult problem under multi leader structure is replicating DDL (Data Definition Language), that is write operations targeting Schema, specifically see DDL replication
Leaderless Replication
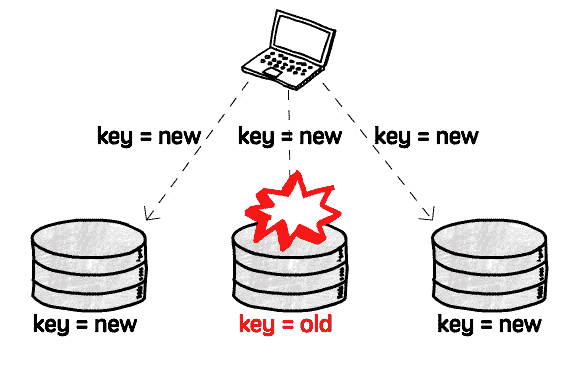
Of course, there's also a structure that doesn't distinguish master database, all databases are readable and writable
Looks like "all-master structure", then predictably, write conflicts will become very common, so we need to adjust strategy, avoid making it "all-master structure":
-
Write: Client writes to multiple databases simultaneously, as long as some succeed consider write complete
-
Read: Client reads from multiple databases simultaneously, each database returns data and its corresponding version number, client decides which one to adopt based on version number
No master database, means don't need to consider failover, single database failure doesn't affect overall, all kinds of troublesome problems of selecting new master database no longer exist
Meanwhile, no master database also means no data synchronization mechanism, old values read cannot be automatically corrected:
So need additional error correction mechanism, client writes new value back when reading old value (called Read repair), or independent process specifically responsible for finding old values and correcting them back
Another key factor is number of target databases for read/write operations, at least how many databases need to write successfully, at least how many databases need to successfully read to guarantee can definitely read new value?
If w databases write successfully, then successfully read r databases' data, then must satisfy w + r > total number of databases
5. Specific Implementation
Specifically, there are 3 ways to copy some data from one database to another:
-
Statement-based replication: Send write operation statements as-is to other databases to execute
-
Write-ahead log shipping replication: Also called physical replication, pass database logs to other databases, recover completely consistent data from logs. For example PostgreSQL's Streaming Replication
-
Row-based replication: Also called logical replication, pass logs specifically used for replication, replicate by row. For example MySQL's Mixed Binary Logging Format
Problem with replicating by statement is, not all statement execution results are deterministic, for example CURRENT_TIME(), RANDOM(), although some databases will replace these values during replication, still cannot guarantee triggers, and user-defined functions have deterministic execution results. On the other hand, also need to ensure transaction operations' atomicity on all databases, either all completed, or all not done at all
Write-ahead log shipping replication can guarantee data completely consistent, but (storage engine-oriented) logs usually cannot be used across database versions, because under different database versions, data's physical storage method may change. And, log shipping is not suitable for multi leader structure, because cannot merge multiple logs into one
And row-based replication is combination of previous two methods, adopts logs specifically used for replication, no longer coupled with storage engine, thus can be used across database versions. Compared to replicating by statement, row-based replication needs to record more information (for example one statement affected 100 rows, need to record all by row)
No comments yet. Be the first to share your thoughts.