Preface
JavaScript string processing seems not difficult, until encountering emoji:
[caption id="attachment_1801" align="alignnone" width="626"]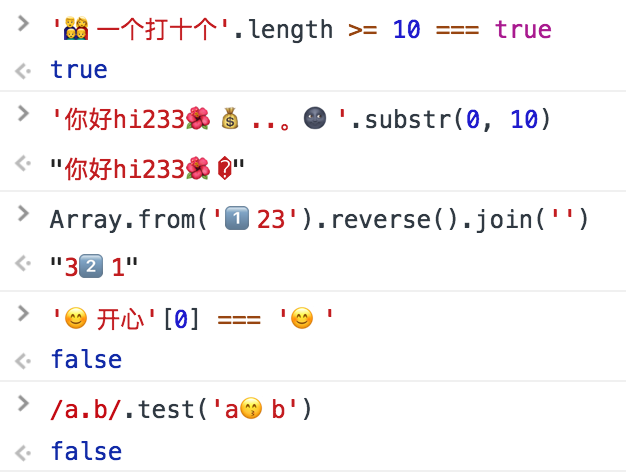 javascript-emoji-issues[/caption]
javascript-emoji-issues[/caption]
?? What happened? What exactly is going on?
Have to start from Unicode encoding...
I. Unicode Encoding
The Unicode codepoint range goes from U+0000 to U+10FFFF which is over 1 million symbols, and these are divided into groups called planes. Each plane is about 65000 characters (16^4). The first plane is the Basic Multilingual Plane (U+0000 through U+FFFF) and contains all the common symbols we use everyday and then some. The rest of the planes require more than 4 hexadecimal digits and are called supplementary planes or astral planes.
That is to say, Unicode supports encoding range from U+0000 to U+10FFFF, can correspond to over 1 million symbols (0x10FFFF === 1114111). These symbols are grouped into 16 planes, so each plane holds 65536 (16^4 === 65536) characters.
Among them, commonly used symbols are placed in the first plane (U+0000 to U+FFFF), so it's called Basic Multilingual Plane (BMP), the codepoint values (codepoint, i.e., Unicode encoding values corresponding to symbols) in the remaining planes are all greater than 4 digits (hexadecimal), called supplementary planes.
P.S. Supplementary planes also have a very impressive name, called astral plane.
I have no idea if there's a good reason for the name "astral plane." Sometimes, I think people come up with these names just to add excitement to their lives.
In addition, the occupancy rate of 65536 positions in the Basic Multilingual Plane is not 100%, some positions are specially left empty for emergencies, such as adding new special meaning symbols, or extensions.
For example, the concept of surrogate pairs in UTF-16, that is, using two 4-digit (hexadecimal) small codepoint values to represent a large codepoint value (greater than 4 digits), which is a kind of mapping from Basic Multilingual Plane to supplementary planes. The reason this can be done is because:
In the Basic Multilingual Plane, the codepoint range from U+D800 to U+DFFF is permanently reserved and not mapped to Unicode characters. UTF-16 uses the reserved 0xD800-0xDFFF range codepoints to encode codepoints of characters in supplementary planes.
II. Unicode in JavaScript
There are 3 representation methods for Unicode characters in JS:
'A' === '\u0041' === '\x41' === '\u{41}'
Among them \x is only used for U+0000 to U+00FF, \u is applicable to any Unicode character (U+0000 to U+10FFFF), but if greater than 4 digits (greater than U+FFFF), need to use curly braces ({}) to wrap the hexadecimal sequence:
The \x can be used for most (but not all) of the Basic Multilingual Plane, specifically U+0000 to U+00FF. The \u can be used for any Unicode characters. The curly braces are required if there are more than 4 hexadecimal digits and optional otherwise.
Note that \u{} escape syntax was defined in ES 2015, called UnicodeEscapeSequence. Previously used two small Unicode to represent a large Unicode, for example:
'' === '\u{1F4A9}'
'' === '\uD83D\uDCA9'
\uD83D\uDCA9 is a surrogate pair, in the form <H,L>, the conversion relationship between the two is as follows:
let C, L, H;
C = 0x1F4A9;
// 公式:大 Unicode 转代理对儿
H = Math.floor((C - 0x10000) / 0x400) + 0xD800;
L = (C - 0x10000) % 0x400 + 0xDC00;
[H, L].map(v => '\\u' + v.toString(16).toUpperCase()).join('')
"\uD83D\uDCA9"
In addition, JS considers a 16-bit unsigned integer value as a character, so an emoji may be considered as multiple characters:
The phrase code unit and the word character will be used to refer to a 16-bit unsigned value used to represent a single 16-bit unit of text.
Unicode character only refers to entities represented by single Unicode scalar values: the components of a combining character sequence are still individual "Unicode characters", even though a user might think of the whole sequence as a single character.
P.S. For JavaScript's Unicode support and ES specification related content, see JavaScript's internal character encoding: UCS-2 or UTF-16?
Unicode in Regular Expressions
Since large Unicode (greater than U+FFFF) is represented by two small Unicode (surrogate pairs) in JS, naturally such regular expressions will be written:
> /[\uD83D\uDCA9-\uD83D\uDE0A]/.test('')
Uncaught SyntaxError: Invalid regular expression: /[\uD83D\uDCA9-\uD83D\uDE0A]/: Range out of order in character class
Error reports cannot recognize such range, so how to describe large Unicode character range with regular expressions?
JS provides u flag to solve this problem:
u Unicode; treat pattern as a sequence of Unicode code points
/[\uD83D\uDCA9-\uD83D\uDE0A]/u.test('')
/[-]/u.test('')
Similarly, . (dot matches any character) wants to match large Unicode in surrogate pair form, also needs to enable u flag:
> /foo.bar/.test('foobar')
false
> /foo.bar/u.test('foobar')
true
P.S. /./u can only match emoji in surrogate pair form, other forms won't work, for example:
> /foo.bar/u.test('foo2??bar')
false
P.S. For more related examples, see Astral ranges in character classes
fromCodePoint and fromCharCode
The difference between String.fromCodePoint and String.fromCharCode is that the former supports a larger range of hexadecimal Unicode encoding, for example:
> String.fromCodePoint(0x1F4A9)
""
> String.fromCharCode(0x1F4A9)
"?"
But fromCodePoint was defined by ES 2015 specification, compatibility is not as good as fromCharCode, for Unicode characters in 0x0000-0xFFFF range of 65536, recommend using fromCharCode.
III. emoji Encoding
Similar to Unicode, emoji is also an encoding rule, also has corresponding specifications, and there are many versions:
Emoji 12.0
Emoji 11.0
Emoji 5.0
Emoji 4.0
Emoji 3.0
Emoji 2.0
Emoji 1.0
Among them 12.0 is planned to be released in 2019, the latest 11.0 was released on 2018-02-07.
Like HTML, CSS specifications, emoji added in new version specifications are not necessarily all implemented, and face worse compatibility problems than HTML, CSS:
-
Specification version: emoji specifications are released frequently, multiple versions coexist
-
Platform differences: In addition to Web browser environment, emoji also depends on platform native support (various screen display devices)
-
Depends on Unicode: emoji is built on Unicode basis, depends on Unicode specifications
For example, copying and pasting from SMS to webpage input box, emoji may not display or become garbled, because native and Web browser supported emoji specification versions or implementation degrees have differences. In addition, Unicode new specifications may conflict with already defined emoji specifications, at this time naturally emoji specifications must yield:
Unicode 12.0 is the new version of the Unicode Standard planned for release in March 2019. See Emoji 12.0 for a more complete list of potential emojis for 2019.
Note: All emojis listed throughout 2018 are candidates only, and subject to change before a final release.
How harsh is the environment emoji faces? As shown in the figure:
[caption id="attachment_1802" align="alignnone" width="625"] emoji-unicode-platform[/caption]
emoji-unicode-platform[/caption]
Back to emoji specification itself, looks like this:
1F600 ; emoji ; L1 ; secondary ; x # V6.1 () GRINNING FACE
1F48F ; emoji ; L1 ; none ; j # V6.0 () KISS
The leftmost is Unicode codepoint value, if successfully recorded into Unicode specification, U+1F48F will correspond to KISS emoji:
> '\u{1F48F}'
""
In addition to this kind of emoji corresponding one-to-one with Unicode, joining the Unicode family, there are several special emoji:
-
variation selector-16: An invisible character (
U+FE0F), indicates that the character before it should be displayed as emoji -
zero width joiner: Zero width joiner, is a zero width space (
U+200D), used to combine multiple emoji into one emoji -
tone modifier: Skin tone modifier, a kind of syntax, can change the skin tone of the previous emoji, syntax format is
<emoji>\ud83c[\udffb-\udfff], that isU+D83Cfollowed by different values indicates different skin tone controls -
keycap: Keycap symbols, keycap style
0-9,#and*, ends withU+20E3 -
unofficial emoji flag: There exist some unconventional national flag emoji, starts with black flag (
U+1F3F4), ends with cancel tag (U+E007F)
For example:
// \ufe0f makes black heart character display as emoji, continuous two is also fine
'???' === '\u2764\ufe0f\ufe0f'
'\u2764\ufe0f' === '??'
'\u2764' === '?'
// Zero width joiner \u200d synthesizes complex emoji, + ?? + + = ?????
'?????' == '\ud83d\udc69\u200d\u2764\ufe0f\u200d\ud83d\udc8b\u200d\ud83d\udc69'
// Skin tone modifier, black baby, white baby
'' === '\ud83d\udc76\ud83c\udfff'
'' === '\ud83d\udc76\ud83c\udffb'
// Keycap style
'#??' === '\u0023\ufe0f\u20e3'
// Unofficial national flag
'' ==='\ud83c\udff4\udb40\udc67\udb40\udc62\udb40\udc73\udb40\udc63\udb40\udc74\udb40\udc7f'
IV. emoji in JavaScript
So in JS, how many Unicode characters does one emoji contain?
> '?'.length
1
> ''.length
2
> '1??'.length
3
> ''.length
4
> '???'.length
11
> ''.length
14
The length of an emoji literal varies from 1 to 14 (there may exist even longer)... So, this situation occurs:
> '???我们是一家人'.slice(0, 1)
"?"
> '???我们是一家人'.substr(0, 2)
""
Expect to截取 the first emoji through slice(0, 1), but got a character that cannot be displayed, even substr(0, 2) split a Man () from a family of 4... What to do?
For some emoji, there's a very simple processing method, Array.from:
> Array.from('').length
1
When converting string to array, keeps surrogate pairs together, so length is correct, but this method is not universal:
> Array.from('???').length
7
P.S. Similarly, bestiejs/punycode.js which supports Unicode encoding conversion also has similar problems:
> punycode.ucs2.decode(' ').length
1
> punycode.ucs2.decode('???').length
7
That is to say, relying solely on JS's native support for Unicode cannot correctly handle strings containing emoji. So, will encounter problems in some scenarios:
-
Form validation character limit
-
Truncating article summary
-
Reversing strings
-
Character-by-character processing
-
Regular expression matching
-
...Other text processing scenarios containing emoji
For example:
> '???一个打十个'.length >= 10 === true
true
> '你好 hi233..。'.substr(0, 10)
"你好 hi233?"
> Array.from('1??23').reverse().join('')
"32??1"
> '开心'[0] === ''
false
> /a.b/.test('ab')
false
P.S. For more problems about Unicode in JavaScript, see JavaScript has a Unicode problem
V. Solution: emoutils.js
To solve the row of problems listed above, can only try to identify emoji, currently (2018/09/15) seems there's no such tool library yet.
Hand-craft one, similar to lexical analysis, character-by-character matching, pick out Unicode combinations that conform to emoji encoding rules, specific see source code below.
Github address: https://github.com/ayqy/emoji-utils
Online Demo (test cases): https://ayqy.github.io/emoji/index.html
API
Provides 6 simple APIs:
// Is it an emoji
isEmoji(str)
// Does it contain emoji
containsEmoji(str)
// String to Unicode array
str2unicodeArray(str)
// Calculate length
length(str)
// Substring truncation
substr(str = '', start = 0, len = Infinity)
// String to array, equivalent to split('')
toArray(str)
Internal unexposed methods include:
// Try to match emoji at the beginning, return '' on failure
matchOneEmoji(str, matched = '')
Defects
However, these utility functions are not 100% reliable, because:
Not all browsers, UIs, etc even render ????? as a single symbol. The code assumes the joiners are used between characters appropriately which could be very problematic.
So, emoutils.js's implementation is based on 3 assumptions:
-
All surrogate pairs are emoji (in fact, some surrogate pairs are not emoji)
-
Skin tone control is valid for all emoji, and only valid for emoji (invalid for ordinary text symbols)
-
Emoji connected by joiner all count as one, regardless of whether they can be synthesized into one emoji in display
For the first assumption, surrogate pair form is not necessarily emoji, may also be plain text, for example:
'\ud835\udc00' === ''
The latter two assumptions will also lead to some badcases, for example (Chrome Console environment):
// Try to create black smiley face, failed
'\ud83d\ude0a\ud83c\udfff' === ''
// Try to artificially synthesize new species, failed
'\u0023\ufe0f\u20e3\u200d\ud83d\ude0a' === '#???'
'\ud83d\ude0a\u200d\ud83d\ude0a' === '?'
These cases will all be identified as 1 emoji, while Chrome Console environment displays 2, because they:
-
Conform to emoji encoding grammar rules
-
But are not necessarily legal emoji
-
Even if legal, current platform may not necessarily support
emoutils.js assumes that satisfying the first point is an independently displayed legal emoji, does not consider emoji specification version and platform support, so there are such badcases. The impact badcases may bring is:
-
isEmoji/containsEmoji()misjudges text characters similar to '' -
length()is less than actually displayed character length -
substr()/toArray()does not match actual expectations
So the character set this tool library can identify is a superset of emoji, with an extra part of text in surrogate pair form, and character sequences that conform to emoji encoding rules but are not defined in emoji specifications. Despite this, in practical applications it's sufficient to handle most scenarios.
P.S. For scenarios that need to accurately handle emoji, can consider emoji-regex
No comments yet. Be the first to share your thoughts.