Preface
For relational databases, (when necessary) we can denormalize to sacrifice some write performance in exchange for higher read performance, but the premise is to first satisfy normalized design, then make local adjustments on this basis, deliberately breaking some rules.
Rather than normalizing first, then denormalizing after encountering performance bottlenecks, it's better to consider denormalized design from the start—directly adopt NoSQL.
I. What is NoSQL?
Different from relational databases, NoSQL databases (also called non-SQL or non-relational databases) provide data storage and retrieval mechanisms that are not based on tabular relation modeling:
A NoSQL (originally referring to "non SQL" or "non relational") database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
Without data tables, naturally there's no performance concern about multi-table joins (join operations), and the choice between normalization constraints and denormalization no longer exists.
But without data tables, how should data be organized, and how should relationships be described?
Actually, SQL (relational databases) is not the only option.
Not Only SQL
For NoSQL, another interesting interpretation is Not Only SQL. In the vast world beyond relational databases, data doesn't necessarily have to be flattened into two-dimensional tables, and relationships don't have to be described only using primary keys, foreign keys, and relation tables.
In terms of database types, NoSQL refers to database types other than relational, i.e., non-relational databases (NoREL, Non Relational), such as MongoDB, CouchDB, etc.
From a usage perspective, practicing NoSQL doesn't necessarily require choosing a NoSQL database first. Using MySQL and other relational databases in a "NoSQL" way certainly counts:
You can stay with MySQL, and use it like a NoSQL database.
For example, store a column of JSON strings in a data table, and use this column as a key-value database.
II. 4 Types of NoSQL Databases
Different from table structures in relational databases, NoSQL databases support some more flexible data structures, making certain operations faster.
Key-Value Store

Key-value store is the simplest NoSQL data model, can only store key-value pairs, can only query by key, because the stored values are opaque to the database system (similar to BLOB), unable to search or create indexes based on value characteristics.
P.S. Some key-value databases can sort keys, thereby supporting range queries (retrieving data where keys are within a specific interval), such as finding information about new employees with employee IDs greater than 100000.
The data model is a hash table, therefore can achieve O(1) read/write performance, suitable for simple or frequently changed data, often used as memory cache, such as Memcached, Redis.
Document Store
Document store models around documents (XML, JSON and other semi-structured data), equivalent to an enhanced version of key-value store, providing finer data operations oriented to documents. The biggest difference from key-value store is that the database can understand and process stored values (i.e., documents), querying and creating indexes based on value characteristics (i.e., internal structure of documents).
Additionally, documents support nesting, and even MongoDB, CouchDB and other document databases provide SQL-like query languages to support complex queries.
Suitable for persistent storage, used to store infrequently changed data, as a general alternative to relational databases.
Wide Column Store
In wide column store, column is the smallest data unit, each column is a name-value pair (and timestamp for version control and conflict resolution), above columns there's another level of super column:

Rows containing only columns are called column family, rows containing super columns are called super column family, each row (i.e., a column family or super column family) represents an entity, containing all relevant information about that entity:

The data model is a two-dimensional Map, characterized by high performance and good scalability, therefore suitable for very large datasets, used by Twitter, Facebook and other social networks to store massive data generated by海量 users.
P.S. For example, Google's earliest Bigtable, HBase in Hadoop ecosystem, and Cassandra launched by Facebook.
Graph Database
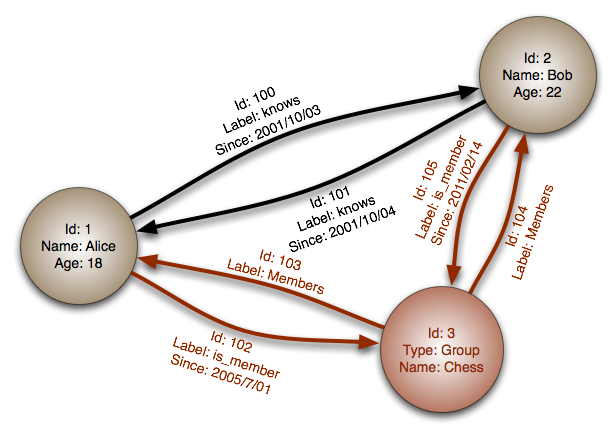
Data is modeled based on graphs, each node in the graph represents a record, each edge represents the relationship between nodes, therefore can easily describe complex relationships between data objects, such as complex foreign keys and many-to-many relationships in relational models.
Practical applications of graph databases are not yet very mature, and there's not yet a widely adopted standardized query language, but its connectivity advantages are especially suitable for data models with complex relationships (such as social networks), worth looking forward to:

P.S. For example, Neo4j, Oracle Spatial and Graph, ArangoDB, etc.
III. What Does NoSQL Mean?
Adopting simple NoSQL models (such as key-value store) is equivalent to shifting part of the work from the database layer to the application layer:
Joins will now need to be done in your application code.
Compared to the database layer, the application layer is usually easier to scale (horizontally), therefore this workload shift helps improve system scalability, throwing complex data operations to the application layer for processing, seeking greater optimization space.
Even strong consistency guarantees like transactions also need to be handled by the application layer, because most NoSQL databases don't provide transaction support:
Most NoSQL stores lack true ACID transactions, although a few databases have made them central to their designs.
ACID vs. BASE
Different from ACID (4 major characteristics of transactions) pursued in relational databases:
-
Atomicity: A series of operations either all succeed or all fail and roll back
-
Consistency: Database must be in a consistent state before and after transaction execution (satisfying all established consistency constraints)
-
Isolation: Results of concurrent transaction operations are the same as executing in sequence
-
Durability: Once a transaction is committed, changes to data are permanent, won't be lost even if encountering failures
NoSQL makes compromises on C in CAP theorem choices, allowing eventual consistency, i.e., BASE:
-
Basically Available: Read/write operations guarantee availability as much as possible, but don't guarantee any consistency
-
Soft state: Due to lack of consistency guarantees, may possibly read latest state after a period of time, because may not have converged yet
-
Eventual consistency: If system runs normally, after waiting long enough, will eventually be able to read latest state
That is, in distributed environments, (most) NoSQL databases only guarantee eventual consistency, may not be able to read latest data immediately.
IV. SQL or NoSQL?
In comparison, advantages of SQL databases (relational databases) lie in:
-
Support for transaction operations
-
Have clear scaling patterns
-
Developers, community, tools, etc. are relatively mature
Main defects are:
-
Complex multi-table queries lead to poor data read performance
-
Not easy to scale (manual sharding)
-
Significant differences between relational model and OOP (Object-relational impedance mismatch)
-
Only support storing structured data, schema (such as table structure) must be predefined, and modification costs are high
P.S. For more information about Object-relational impedance mismatch, see Why is MongoDB wildly popular? It's a data structure thing.
And advantages of NoSQL databases (non-relational databases) concentrate on:
-
No complex multi-table queries
-
Easy to scale (some NoSQL databases support automatic sharding)
-
Consistent with OOP data model, easy to use
-
No need to predefine data schema, support storing rapidly changing structured, semi-structured and unstructured data
-
High read/write performance (IOPS), suitable for data-intensive work
Main defects lie in:
-
Lack strong consistency guarantees
-
Developers, community, tools, etc. are not as mature
Application Scenarios
Therefore, NoSQL databases are suitable for:
-
Rapidly changing data, such as click stream data or log data
-
Leaderboard or rating data
-
Temporary data, such as shopping cart data
-
Frequently accessed hot data
-
Metadata, and lookup tables
No comments yet. Be the first to share your thoughts.