Design Philosophy
What does it express? How does React understand an Application?
An application is a state machine; state drives the view.
v = f(d)
v is the view
f is the component
d is the data/state
What is its relationship with Functional Programming (FP)?
It introduces functional thinking into the front-end, implementing UI through the composition of PureComponents.
The biggest benefit is making UI predictable; for the same f, the same d input will always yield the same v.
You can pull out individual fs to test them, and their combination is guaranteed to be correct. This confirms theoretically that the component quality is reliable and that the UI of the combined application is also reliable.
Goals
What problem does it aim to solve? What is its positioning?
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
It provides a component-based solution specifically for building UIs.
What problems can it solve?
-
Componentization
-
UI reliability
-
Data-driven views
Performance Goals
For many applications, using React will lead to a fast user interface without doing much work to specifically optimize for performance.
It seeks a balance between cost and benefit. Without intentionally performing performance optimizations, you can still write applications with decent performance (though not optimal).
In fact, React's performance optimizations are primarily reflected in:
-
Event delegation: a single global event listener.
-
It has its own complete capture and bubbling system to smooth out IE8 bugs.
-
An object pool reuses event objects to reduce GC (Garbage Collection).
-
-
Consolidation of DOM operations to reduce their frequency.
However, in any case, its performance certainly cannot match that of native DOM operations hand-written by a seasoned (highly experienced) front-end engineer.
Virtual DOM
How does it solve the problem?
By adding an extra layer of abstraction on top of the DOM tree.
Componentization approach: providing component class templates, lifecycle hooks, data flow mechanisms, and local state hosting.
Runtime: managing components with a virtual DOM tree, establishing and maintaining a mapping to the real DOM tree.
What is the role of the Virtual DOM?
-
Batch processing to improve performance.
-
Reducing the cost of
diffing. -
Implementing "data binding."
Specific Implementation
JSX -> React Element -> Virtual DOM Node ..> Real DOM Node
Description Object
-
At compile time, JSX is translated into
createElementcalls. -
Executing
createElementyields a React Element description object. -
A virtual DOM node is created based on the description object.
-
States on the virtual DOM node are consolidated to create the real DOM node.
The set of nodes in the virtual DOM tree is a superset of the nodes in the real DOM tree; the extra parts are custom components (Wrappers).
Structurally, the internal tree layout is a forest, maintained in instancesByReactRootID:
-
When introducing React into an existing app, there may be multiple root DOM nodes.
-
In a pure React application, there is generally only one tree in the forest.
One-Way Data Flow
Waterfall Model
Components are organized by props and state, with the data flow between components resembling a waterfall.
The data flow always goes from ancestor to descendant (from root to leaf) and does not flow backward.
-
props: The pipes. -
state: The water source.
One-way data flow is determined by the state discard mechanism, which specifically manifests as:
-
Changes in data and UI triggered by state changes only affect the components below.
-
Data flows down when rendering the view; form interactions can come back up, triggering another downward render.
One-way data flow is with respect to the view rendering process; changes in a descendant's state will not affect ancestors unless the ancestors are notified to update their own state.
state and props
state is the minimal set of mutable state. Characteristics:
-
Private: Completely controlled by the component itself, not coming from above.
-
Mutable: Changes over time.
-
Independent existence: Cannot be calculated from other
stateorprops.
props are immutable and used only to fill the view template:
props React Element description object
-----> Component ---------------------> View
Data Binding?
Two Stages
-
Dependency collection (static/dynamic dependencies).
-
Listening for changes.
The data-view mapping is collected during the initial render. Subsequently, once a data change is confirmed, the corresponding view for that data is updated.
Three Implementation Approaches
| Implementation | Dependency Collection | Listening for Changes | Examples |
|---|---|---|---|
| getter & setter | getter | setter listens for changes | Vue |
| Providing a data model | Parsing templates | All data operations use the framework's API to notify of changes | Ember |
| Dirty checking | Parsing templates | At the right moment, compare the latest value with the previous one to check for changes | Angular |
| Virtual DOM diff | Almost no collection | setState notifies of changes | React |
From the perspective of the granularity of dependency collection:
-
Vue's dynamic dependency collection via
gettersis the finest and most precise. -
Ember and Angular both identify dependencies through static template parsing.
-
React is the coarsest, performing almost no dependency collection, and rerendering the entire subtree.
When state changes, the internal state of the corresponding subtree is recalculated, differences are identified via diff, and then these changes are applied at the appropriate moment (patch).
Fine-grained dependency collection is the basis for precise DOM updates (which data affects which attribute of which element). It eliminates the need for extra guesswork and judgment. If a framework knows exactly which view elements/attributes are affected, it can directly perform the most fine-grained DOM operations.
Virtual DOM diff Algorithm
React does not collect dependencies and has only two known conditions:
-
Which component this
statebelongs to. -
A change in this
statewill only affect the corresponding subtree.
The subtree range is too large for the DOM operations required for final view updates; it needs to be refined (diffed).
tree diff
Tree diffing is a relatively complex (NP) problem. Consider a simple scenario:
A A'
/ \ ? / | \
B C -> G B C
/ \ | | |
D E F D E
The result of diff(treeA, treeA') should be:
1.insert G before B
2.move E to F
3.remove F
If a computer were to do this, add and delete are easy to find, but determining move is more complex. First, the similarity between trees must be quantified (e.g., weighted edit distance), and it must be determined at what similarity level move is more cost-effective than delete + add (fewer operation steps).
React diff
diffing virtual DOM subtrees faces similar issues. Consider the characteristics of DOM operation scenarios:
-
Local, small changes are frequent; large-scale changes are rare (performance-wise, these are often avoided using show/hide).
-
Cross-level moves are rare; moves within the same level are frequent (e.g., sorting a table).
Assumptions:
-
Assume different types of elements correspond to different subtrees (without considering "looking down to see if subtree structures are similar," determining
movebecomes effortless). -
Both old and new structures will carry unique
keys as the basis fordiff, assuming the samekeyrepresents the same element (reducing comparison costs).
In this way, the tree diff problem is simplified into a list diff (string editing problem):
-
Traverse the new list to find
add/move. -
Traverse the old list to find
delete.
Essentially, it's a very weak string editing algorithm. Therefore, even without considering the diff overhead, the performance of the final actual DOM operations is not optimal (compared to manual DOM manipulation).
Additionally, to be safe, React provides the shouldComponentUpdate hook, allowing manual intervention in the diff process to avoid misjudgments.
State Management
State Sharing and Passing
-
Sibling -> Sibling: Lift the shared state to ensure a top-down, one-way data flow.
-
Child -> Parent: The parent passes down a callback (
function props) in advance. -
? -> Distant relative: Long-distance communication is hard to solve, requiring manual relaying or sharing via
context.
Sharing by lifting state reduces isolated states and the surface area for bugs, but it's ultimately somewhat cumbersome. There is no good solution for long-distance communication between components.
Another issue in complex applications is that state changes (setState) are scattered across various components, making the logic too fragmented and posing maintenance problems.
Flux
The Flux pattern was proposed to solve state management problems, with the goal of making data predictable.
Basic Approach
(state, action) => state
Specific Practices
-
Use explicit data instead of derived data (declare before use, no on-the-fly data creation).
-
Separate data from view state (extract the data layer).
-
Avoid cascading effects from cascading updates (mutual influence between M and V, unclear data flow).
Structure
Generate action Pass action Update state
view interaction -----------> dispatcher -----------> stores --------------> views
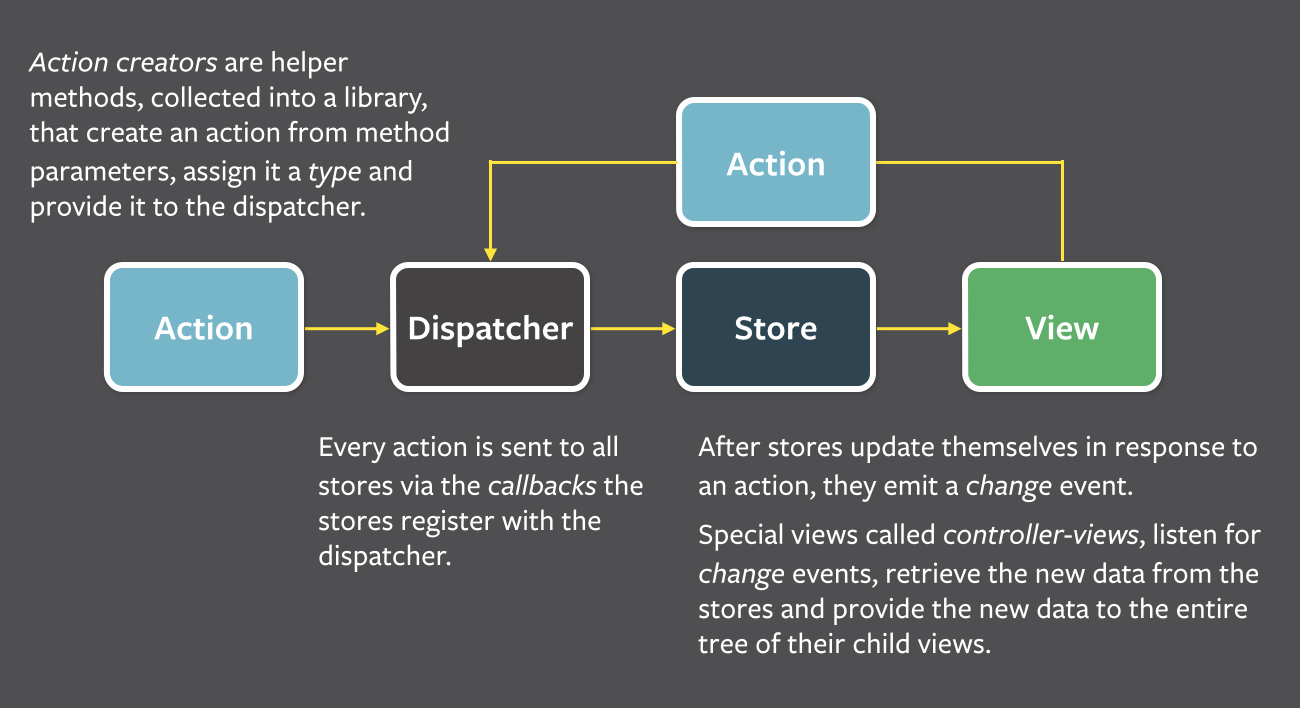
A characteristic is that the store is relatively heavy, responsible for updating internal state based on actions and synchronizing state changes to the view.
container and view
A container is actually a controller-view:
-
A React component used to control the
view. -
Its primary function is to collect information from the
storeand store it in its ownstate. -
It contains no
propsor UI logic.
Redux's Trade-offs
action Like in Flux, it's just an event with a type and data (payload).
Actions are also dispatched manually.
---
store Functions similarly to Flux but is global and unique, implemented as an immutable state tree.
It dispatches actions and registers listeners. Each action passes through layers of reducers to yield a new state.
---
reducer Acts similarly to arr.reduce(callback, [initialValue]).
The reducer is equivalent to the callback, taking the current state and action as input and outputting a new state.
call new state
action --> store ------> reducers -----------> view
An immutable state tree maintains the entire application's state, which cannot be changed directly. When a change occurs, a new object is created through an action and a reducer.
The concept of a reducer is equivalent to Node middleware or a Gulp plugin. Each reducer is responsible for a small part of the state tree. By chaining a series of reducers (using the output of the previous reducer as the input for the current one), the final output state is obtained.
Comparison with Flux
-
Limits the number of
stores to 1. -
Removes the
dispatcher, passing theactionto all top-levelreducers, from where it flows to the corresponding subtrees. -
Separates the part that updates the internal
statebased on anactioninto individualreducers.
The dispatcher could be removed because pure-function reducers can be composed arbitrarily without needing extra management of their execution order.
react-redux
Redux has no inherent connection to React. As a state management layer, Redux can be used with any UI solution, such as Backbone, Angular, React, etc.
react-redux is used to handle the new state -> view part. That is, once a new state exists, how do we synchronize the view?
container
A container is a special type of component that contains no view logic and is closely related to the store. Logically, it reads a part of the state tree via store.subscribe() and passes it as props to the ordinary components (view) below.
connect()
A seemingly magical API that primarily does three things:
-
Generates a container.
-
Injects
dispatchandstatedata aspropsinto the ordinary components below. -
Includes built-in performance optimizations to avoid unnecessary updates (built-in
shouldComponentUpdate).
What's with the Provider?
Purpose: To avoid manually passing the store through every layer.
Implementation: Inject the store via context at the top level, allowing all components below to share the store.
Ecosystem
-
Debugging tools:
DevTools -
Platforms:
React Native -
Component libraries:
antd,Material-UI -
Evolution:
Rax -
State management layers:
Redux Saga,Dva
No comments yet. Be the first to share your thoughts.