Preface
UC Berkeley published a paper about Serverless on February 10, 2019, which sparked heated discussion in the industry about Serverless in the following months.
Berkeley researchers believe Serverless can handle almost all system administration operations, making it easier for developers to use the cloud. It can greatly simplify cloud programming, and also marks an evolution similar to the transition from assembly language to high-level programming languages:
Serverless cloud computing handles virtually all the system administration operations needed to make it easier for programmers to use the cloud. It provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages.
They even believe Serverless will dominate the future of cloud computing:
Just as the 2009 paper identified challenges for the cloud and predicted they would be addressed and that cloud use would accelerate, we predict these issues are solvable and that serverless computing will grow to dominate the future of cloud computing.
I. 6 Predictions from 10 Years Ago
10 years ago (February 10, 2009), UC Berkeley pointed out 6 major potential advantages of cloud computing in a paper about Cloud Computing:
-
Can provide unlimited computing resources on demand
-
Cloud users don't need to estimate resources
-
Provides pay-as-you-go short-term computing resources
-
Economies of scale from hyperscale data centers will greatly reduce costs
-
Simplify operations and improve utilization through resource virtualization
-
Improve hardware utilization through multiplexing
P.S. For detailed information about these predictions, see [Cloud Computing in the Eyes of Berkeley Researchers](/articles/伯克利研究员们眼中的 cloud-computing/)
As of today, these advantages have basically been realized. But operational complexity still troubles cloud users, and the advantages of multiplexing haven't been fully leveraged:
-
Cloud computing alleviates the burden of managing physical infrastructure, but generates a large number of virtual resources that also need management
-
Multiplexing can excel in batch processing scenarios (such as MapReduce or high-performance computing), but is difficult to play a role for stateful services (such as enterprise applications like data management systems)
P.S. Multiplexing is a resource sharing technology widely used in communications, including time-division multiplexing, frequency-division multiplexing, etc.
The reason is that the market chose a lower degree of resource abstraction, cloud users control the entire resource stack like using physical hardware, still need to consider:
-
Availability redundancy (avoiding single points of failure)
-
Remote disaster recovery
-
Load balancing
-
Elastic scaling
-
Monitoring
-
Logs (for debugging or performance diagnosis)
-
System upgrades (security patches, etc.)
-
Portability (migrating to new instances)
II. Serverless Computing Enters the Stage
Concept Definition
After realizing the need for ease of use, Amazon launched AWS Lambda service in 2015, i.e., cloud functions, which then attracted widespread attention to the serverless computing concept:
Serverless suggests that the cloud user simply writes the code and leaves all the server provisioning and administration tasks to the cloud provider.
Handing over all server-related configuration and management tasks to cloud providers to reduce users' burden of managing cloud resources
Therefore, Serverless Computing doesn't mean computing without servers, but rather users don't need to spend much effort managing servers. Similarly, Serverless services can (automatically) elastically scale, no need for explicit resource provisioning, and billing is based on usage.
On the other hand, Serverless also brings a paradigm shift—allowing full operational responsibilities to be offloaded to providers, making fine-grained multi-tenant multiplexing possible:
Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplexing.
The core of Serverless is FaaS (Function as a Service), but cloud platforms usually also provide Serverless frameworks to meet specific application requirements like BaaS (Backend as a Service). Therefore, it can be simply understood as:
Serverless computing = FaaS + BaaS
Basic Architecture
Serverless layer sits between application layer and infrastructure cloud platform layer, used to simplify cloud programming:
[caption id="attachment_2050" align="alignnone" width="625"]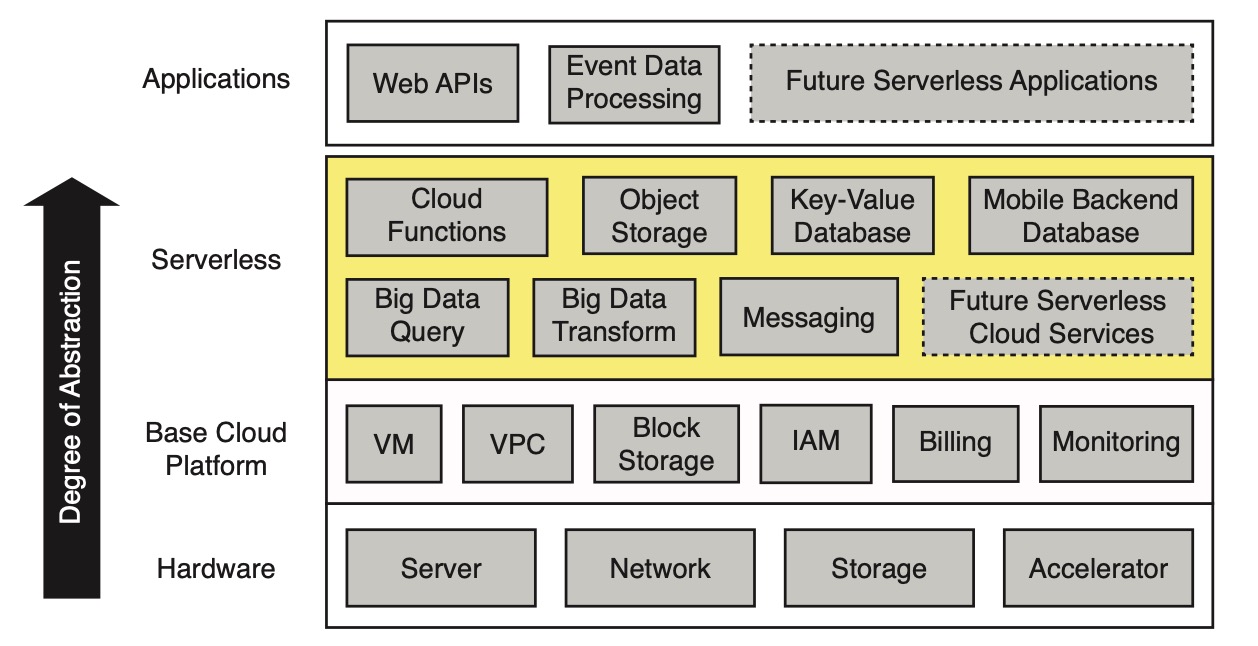 Architecture of the serverless cloud[/caption]
Architecture of the serverless cloud[/caption]
Among them, cloud functions (such as FaaS) provide general computing, supplemented by specific BaaS product ecosystems (such as object storage, databases, messaging mechanisms, etc.). Infrastructure platform includes virtual machines (VM), virtual private networks (VPC), virtualized block storage, identity and access management (IAM), and billing and monitoring.
Serverless vs. Serverful
Users only need to write some cloud functions in high-level languages on Serverless platform, then select events that trigger function execution. Everything after that is handled by Serverless system—instance selection, scaling, deployment, fault tolerance, monitoring, logs, security patches, etc., all don't need to be concerned. Simplifies application development by improving ease of use of cloud resources.
In cloud context, for cloud developers, traditional approach (Serverful Computing) is like using low-level assembly language, even simple calculation like c = a + b requires a series of operations:
-
Select 1 or 2 registers (provision or find available resources)
-
Load values into registers (load code and data)
-
Execute arithmetic operations (perform calculations)
-
Store calculation results (return or store results, finally release resources)
While Serverless approach is like programming in high-level languages like Python, avoiding these tedious operations.
Therefore, the most promising aspect of Serverless lies in bringing cloud developers benefits similar to transitioning to high-level languages:
The aim and opportunity in serverless computing is to give cloud programmers benefits similar to those in the transition to high-level programming languages.
Some features of high-level programming environments have natural similarities in Serverless, for example, automated memory management frees developers from memory resource management, while Serverless aims to free developers from server resource management.
More precisely, the most critical differences between Serverless and Serverful are:
-
Separation of compute and storage: Storage and compute scale separately, provisioned independently, priced independently. Usually storage is provided by separate cloud services, and compute is stateless
-
Execute code without managing resource allocation: Users provide code, cloud automatically provisions resources to execute
-
Pay per use, not per allocated resources: Pay based on dimensions related to code execution (such as execution time), not based on cloud platform dimensions (such as size and number of allocated VMs)
III. Key Characteristics
Sounds not much different from some previous patterns:
-
Some existing PaaS products, like Firebase, Heroku, Parse, seem to be Serverless
-
Didn't web hosting environments in the 80s also provide benefits claimed by Serverless?
-
Sounds like Google AppEngine from 10 years ago, but this was already rejected by the market before Serverless concept emerged
So, compared to these previous patterns, what are the key characteristics of Serverless?
Scalability
In terms of scalability, AWS Lambda can precisely track load conditions, quickly respond and scale on demand, scale down to zero resources and zero cost during idle times. And can bill in finer granularity (100ms), while traditional elastic scaling services usually bill by hour.
Most critically, Serverless's starting point is billing based on actual code execution time, not for resources reserved for program execution:
In a critical departure, it charged the customer for the time their code was actually executing, not for the resources reserved to execute their program.
This difference ensures cloud providers can share risks and benefits with cloud users on elastic scaling (skin in the game), thereby promoting efficient resource allocation.
Strong Isolation
Serverless relies on strong performance and security isolation to achieve multi-tenant hardware sharing.
For cloud functions, VM isolation is currently the standard approach, but provisioning VMs may take several seconds, so cloud providers use some fine-grained techniques to accelerate function execution environment creation. For example, AWS Lambda maintains a warm pool of VMs managing VMs that can be immediately allocated to tenants, and an active pool of instances managing those already executing or ready to execute functions.
Resource lifecycle management and multi-tenant bin packing are key to achieving high utilization, crucial for Serverless. Most use containers, single-core, library OS, or language VM technologies to reduce multi-tenant isolation overhead, such as gVisor used by Google App Engine, Firecracker VM in AWS Lambda, and CloudFlare Workers platform using web browser sandbox technology to achieve multi-tenant isolation between JavaScript cloud functions.
Platform Flexibility
PaaS services are usually closely related to specific use cases, while Serverless allows users to use their own libraries, supporting wider range of applications than PaaS.
Moreover, Serverless runs on modern large-scale data centers, supporting much larger scale than old shared web hosting environments.
Service Ecosystem Support
Cloud functions (such as FaaS) successfully popularized Serverless pattern, partly due to some BaaS services existing since public cloud era (such as AWS S3). These BaaS services can be viewed as Serverless implementations oriented to specific domains and highly optimized, while cloud functions are a more general Serverless manifestation:
| Service | Programming Interface | Cost Model |
|---|---|---|
| Cloud Functions | Arbitrary code | Function execution time |
| BigQuery/Athena | SQL-like query | The amount of data scanned by the query |
| DynamoDB | puts() and gets() | Per put() or get() request + storage |
| SQS | enqueue/dequeue events | per-API call |
IV. Core Advantages
For cloud providers, Serverless can promote business growth, simplify cloud programming, attract new users and help existing users fully utilize cloud resources. Additionally, short execution time, low memory footprint, and stateless characteristics facilitate statistical multiplexing. When running these tasks, cloud providers can more easily discover unused resources. Can even better utilize less popular machines (such as old machines), because instance types are determined by cloud providers. Both points can immediately increase revenue based on existing resources.
For cloud users, besides improving programming productivity, can also save costs in most scenarios, because utilization of underlying servers is improved. Can directly deploy functions without any cloud infrastructure, not only saves deployment time, letting cloud users focus on application problems themselves, but also saves money, because functions only execute when events occur. Fine-grained billing model (currently 100ms) means pay per actual use, not per reserved resources.
From research perspective, Serverless is a new general-purpose computing abstraction, expected to become the future of cloud computing. Because Serverless elevates cloud deployment level from x86 machine code to high-level programming languages, thereby achieving architectural innovation. If ARM or RISC-V has better cost-performance than x86, Serverless can easily change instruction sets. And cloud providers can also accelerate programs written in languages like Python through research on language-oriented optimization and domain-specific special architectures.
P.S. 99% of cloud computers use x86 architecture (x86 microprocessors + x86 instruction set)
V. Limitations of Existing Serverless Platforms
Nowadays, cloud functions have been successfully applied to various work, including API services, event stream processing, and limited ETL (Extract-Transform-Load, data processing). So why can't they carry more general services?
The reasons are:
-
Insufficient storage support for fine-grained operations: Current cloud storage services cannot meet cloud function needs
-
Lack of fine-grained coordination: No multi-task coordination mechanism
-
Poor performance under standard communication patterns: Cannot share or aggregate data between multi-tasks
-
Unpredictable performance: Although lower startup latency than traditional VM-based instances, startup latency for new instances is still too high for some applications
Insufficient Storage for Fine-Grained Operations
Serverless platform's statelessness makes it difficult to support applications requiring shared fine-grained state, currently mainly limited by cloud storage services.
Object storage services (such as AWS S3, Azure Blob Storage, Google Cloud Storage) can scale quickly and provide cheap long-term object storage, but have high access costs and latency. Recent tests show reading/writing small objects requires at least 10ms, maintaining 100K IOPS (Input/Output Operations Per Second) costs $30/minute, 3 to 4 orders of magnitude higher than AWS ElastiCache instances. ElastiCache instances have sub-millisecond read/write latency, and IOPS can even exceed 100K.
KV databases (such as AWS DynamoDB, Google Cloud Datastore, Azure Cosmos DB) all provide high IOPS support, but are very expensive and cannot scale quickly. Although cloud providers also offer memory storage instances based on popular open-source projects (such as Memcached or Redis), they lack fault tolerance support and cannot auto-scale like Serverless platforms.
Applications built on Serverless infrastructure need provision-transparent storage services, i.e., storage services that can automatically scale with compute. Different applications may have different requirements for durability, availability, latency, performance, etc., so may need both ephemeral and persistent Serverless storage options.
Lack of Fine-Grained Coordination
To support stateful applications, Serverless frameworks need to provide a way to coordinate multiple tasks. For example, if task A uses output from task B, A must have a way to know when input is ready, even if A and B are on different nodes. Many protocols ensuring data consistency also need similar coordination mechanisms.
Existing cloud storage services don't have notification capabilities. Although cloud providers offer independent notification services (such as SNS, SQS), they have high latency (sometimes hundreds of ms), and fine-grained coordination usage costs are also high. Although there are some related improvement research (such as Pocket), they haven't been adopted by cloud providers yet.
Therefore, applications either manage a VM-based system with notification capabilities (such as ElastiCache, SAND), or implement their own notification mechanisms, such as letting cloud functions communicate through a long-running VM-based rendezvous server. This limitation has sparked exploration of some new Serverless variants, such as named function instances allowing access to internal state through direct addressing (such as Actors as a Service).
Poor Performance Under Standard Communication Patterns
Common communication patterns in distributed systems like broadcast, aggregation, shuffle mechanisms have dramatically increased complexity in cloud function environments:
[caption id="attachment_2051" align="alignnone" width="1004"]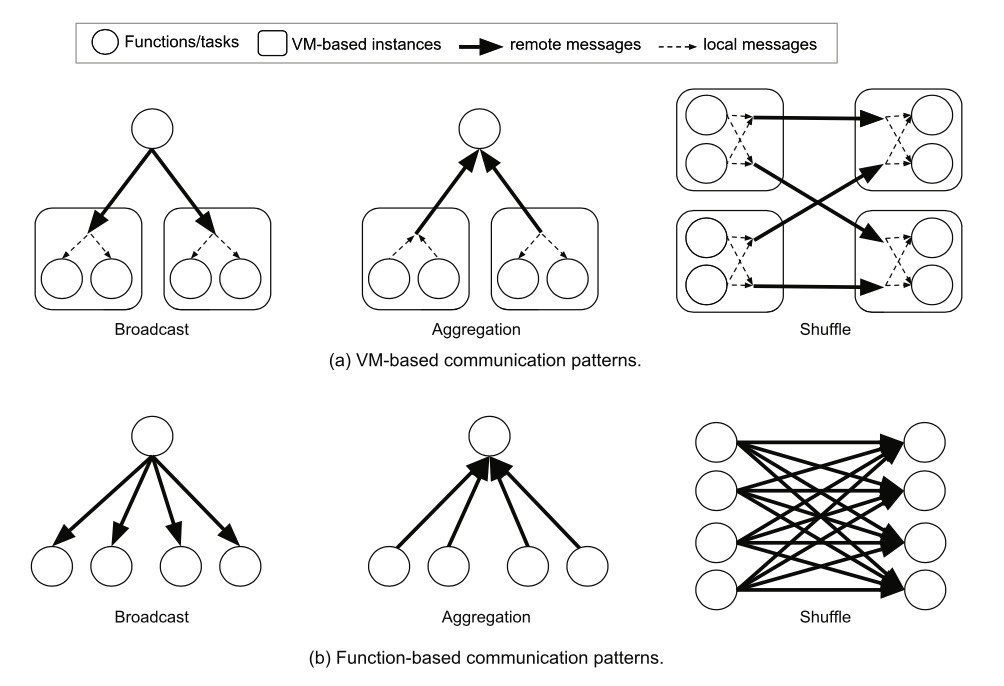 communication patterns for distributed applications[/caption]
communication patterns for distributed applications[/caption]
The reason is VM instances have opportunities to share, aggregate, or merge data between tasks before sending data and after receiving data, while Serverless doesn't.
Specifically, in VM-based approaches, all tasks running on the same instance can share broadcasted data, or perform local aggregation before sending partial results to other instances. Therefore, communication complexity for broadcast and aggregation is O(N), where N is the number of VM instances in the system. While in cloud function environment, communication complexity is O(N × K), where K is the number of functions on each VM.
This difference is even greater under shuffle mechanism. In VM-based approaches, all local tasks can merge data together, so only one message needs to be passed between two VMs. Assuming equal number of senders and receivers, N^2 messages need to be sent. While in cloud function approach, (N × K)^2 messages need to be sent. Since cloud functions have much fewer CPU cores than VMs, K is usually 10 to 100. Plus applications cannot control cloud function locations, actual data sent may be 2 to 4 orders of magnitude more than equivalent VM approaches.
P.S. These communication patterns are mostly used in machine learning and big data analysis applications.
Unpredictable Performance
There are 3 factors affecting cold start latency:
-
Time required to start cloud functions
-
Time required to initialize software environment for the function, such as loading Python libraries
-
Time for specific application initialization in user code
Compared to overhead of the latter two, the former is nothing. For example, starting cloud functions only takes 1 second, while loading all application libraries may take tens of seconds.
Another obstacle is variability of hardware resources, because cloud providers can flexibly choose underlying servers (may even encounter CPUs from different generations). For this problem, cloud providers need to balance between maximizing resource utilization and performance predictability.
VI. Ideal Serverless Computing
To let more applications benefit from Serverless, mainly faces challenges in abstraction, system, network, security, architecture, etc.
Abstraction
Resource Requirements
Developers can only limit cloud function memory size and execution time, but cannot control other resource requirements, such as CPU, GPU, or other types of accelerators.
One approach is to let developers explicitly specify these resource requirements, but makes it harder for cloud providers to achieve high utilization through statistical multiplexing, because more constraints are imposed on cloud function scheduling. And goes against Serverless spirit, because it increases resource management burden for cloud application developers.
Another better option is raising abstraction level, letting cloud providers infer resource requirements instead of developers specifying. For example, cloud providers can achieve this through static code analysis, analyzing previous run conditions, or dynamically compiling source code. Automatically provisioning appropriate memory sounds attractive, but is full of challenges, especially when high-level languages have automatic garbage collection mechanisms. Some research even suggests these language runtimes should be integrated with Serverless platforms.
Data Dependencies
Current cloud function platforms don't know data dependency relationships between two cloud functions, leading to potentially large data exchange between these functions. May also lead to undesirable node distribution, triggering less efficient communication patterns.
One solution is for cloud providers to expose an API that allows applications to specify their computation graphs, to support better node distribution decisions, minimizing communication, thereby improving performance. Actually, many general distributed frameworks (such as MapReduce, Apache Spark, Apache Beam/Cloud Dataflow), parallel SQL engines (such as BigQuery, Azure Cosmos DB), and orchestration frameworks (such as Apache Airflow) already generate such computation graphs internally. In principle, these systems can also run in cloud function environment through modification, and expose computation graphs to cloud providers.
P.S. AWS Step Functions is already doing this, providing a state machine language and API.
System
High-Performance, Provision-Transparent, and Affordable Storage
For ephemeral and persistent storage requirements, ephemeral storage is mainly used to solve speed and latency issues when passing state between cloud functions.
One approach to provide ephemeral storage is building distributed memory services with optimized network stacks to guarantee microsecond-level latency. And like operating systems providing transparent memory provisioning for processes, auto-scale, create/release with application lifecycle, and provide security isolation. But currently RAMCloud, FaRM can guarantee low latency and high IOPS, but don't provide multi-tenant isolation. While Pocket cannot auto-scale, requires pre-allocated storage.
Moreover, through statistical multiplexing, ephemeral storage can have higher memory efficiency than current Serverful models, can also utilize the part of memory in VM instances that applications don't fully use.
Although database functionalities like OLTP (On-Line Transaction Processing) may increasingly be provided in BaaS form, for applications requiring longer persistent storage than Serverless applications, should also implement high-performance Serverless persistent storage.
For persistent storage, can leverage SSD-based distributed storage supplemented by distributed memory cache, such as Anna KV database, achieving high cost-performance and high performance by combining multiple existing cloud storage services. But the key point of this design is how to achieve low tail latency under large tail access distributions. At this point, memory cache capability may be much lower than SSD capability. Additionally, leveraging new storage technologies promising microsecond-level access times is also a possible solution.
Similar to Serverless ephemeral storage, persistent storage services should also be provision-transparent and security-isolated. The difference is, Serverless persistent storage can only explicitly release resources, like traditional storage systems. Of course, must also guarantee durability, any written data must be preserved during failures.
Coordination/Signaling Services
Cloud functions usually use producer-consumer pattern to share state, requiring consumers to immediately know when producer's data is available.
Similarly, a function may need to signal another when certain conditions are met, or multiple functions may want to work together, such as implementing data consistency mechanisms. Such signaling systems will benefit from microsecond-level latency, reliable transmission, and broadcast or group communication. And because cloud function instances cannot be individually addressed, cannot be used to implement textbook distributed system algorithms (such as consensus or leader election).
Minimizing Startup Time
Startup time is divided into 3 parts:
-
Scheduling and starting resources related to running cloud functions
-
Downloading application software environment required to run cloud function code (such as operating systems, libraries)
-
Executing application-specific startup tasks, such as loading and initializing data structures and libraries
Resource scheduling and initialization, and configuring VPC and IAM policies cause significant latency and overhead. Cloud providers recently focus on shortening startup time through developing lightweight isolation mechanisms.
One approach is using single-core to save overhead:
-
Instead of dynamically detecting hardware, applying user configurations, allocating data structures like traditional operating systems, compress these costs through pre-configured hardware and statically allocated data structures
-
Additionally, single-core only contains drivers and system libraries necessary for applications, much lower space occupation than traditional operating systems
But single-core is customized for specific applications. When running multiple standard kernels in real-time, may not achieve further efficiency improvements, such as cannot share kernel code paging between different cloud functions in same VM, or reduce startup time through pre-caching.
Another approach is dynamically incrementally loading libraries when applications actually call them, such as shared file systems in Azure Functions.
Application-specific initialization is developer's responsibility, but cloud providers can provide ready signals in their APIs to avoid premature cloud function calls. Additionally, cloud providers can pre-execute startup tasks, especially suitable for customer-irrelevant tasks (such as starting VMs and popular operating systems and related libraries), because multi-tenants can share a warm pool.
Network
As mentioned earlier, popular communication mechanisms like broadcast, coordination, shuffle bring serious overhead in cloud function environments. For example, if packing K cloud functions into one VM instance, cloud function version will send K times (or even more) messages than VM version. In shuffle scenarios, even need K^2 message communications.
There are 3 ways to solve this problem:
-
Provide multi-core for cloud functions, similar to VM instances, so multiple tasks can merge/share data before sending or after receiving data
-
Allow developers to explicitly place some cloud functions on same VM instance, providing out-of-the-box distributed communication mechanisms for applications, so cloud providers can allocate cloud functions to same VM instance
-
Let applications provide computation graphs, allowing cloud providers to allocate related cloud functions to same VM instance (co-locate), thereby minimizing communication overhead
But first two approaches reduce cloud providers' flexibility in allocating cloud functions, leading to reduced data center utilization. And goes against Serverless Computing spirit, because forces cloud developers to consider system management.
Security
Serverless disrupts previous security responsibility division, shifting many responsibilities from cloud users to cloud providers, without fundamentally changing them. However, Serverless must also deal with inherent risks of multi-tenant resource sharing between applications.
Random Scheduling and Physical Isolation
Physical co-residency is key to hardware-level side-channel and Rowhammer attacks in cloud environments. Such attacks first require being on same physical host as victim.
Ephemeral nature of cloud functions can somewhat limit attackers' ability to identify concurrently running victims. Random or adversary-aware scheduling algorithms can reduce risk of attackers and victims being on same host, making physical co-residency attacks more difficult. But these security measures may conflict with allocation (VM) approach's startup time, resource utilization, and communication optimization.
Fine-Grained Security Contexts
Cloud functions need fine-grained configuration, including accessing private keys, storage objects, and local ephemeral resources. Need to convert security policies from existing Serverful applications, and provide security APIs that can fully express (these policies) for dynamic use in cloud functions. For example, cloud functions may have to delegate some security privileges to other cloud functions or cloud services.
In encryption-protected security contexts, function-based access control mechanisms may be natural choice for such distributed security models. Recommend using information flow control for cross-function access control in multi-party settings, such as dynamically creating short-term keys and certificates for cloud functions. But other issues in distributed management of security mechanisms (such as asymmetry and certificate revocation) will intensify.
From system perspective, users need function-level fine-grained security isolation, at least as an option. And the difficulty in providing function-level sandboxes lies in guaranteeing short startup times, not caching execution environment in shared state manner for repeated function calls. Can use local instance snapshots, letting each function start from clean state, or adopt lightweight virtualization technologies (such as library OS, single-core, micro VMs, etc.), can reduce startup time to tens of milliseconds. But uncertain whether security can reach traditional VM level. Positive side is, vendor management and short-term instances in Serverless can patch vulnerabilities faster.
For users wanting protection against physical co-residency attacks, one solution is requiring physical isolation. Cloud providers can provide advanced options for customers, starting cloud functions on dedicated physical hosts.
Oblivious Serverless
Cloud functions may leak access patterns and timing information in communication.
For serverful applications, usually batch retrieve data and cache locally. While since cloud functions are ephemeral and widely distributed in cloud environment, network transmission patterns may leak sensitive information (such as own employees), even if data is end-to-end encrypted. Trend of decomposing Serverless applications into many small functions exacerbates this security hazard. Although main security problems come from external attackers, can also protect against employee attacks through oblivious algorithms. However, overhead of doing so is usually very high.
Architecture
Hardware Heterogeneity, Pricing, and Ease of Management
Dominant x86 microprocessors in cloud computing have almost no performance improvement (single-program performance improvement was only 3% in 2017). If this trend continues, performance won't double in 20 years. Similarly, DRAM capacity per chip has also approached limits. Currently there are 16Gbit DRAM on sale, but seems cannot produce 32G DRAM chips. Only consolation is, this turtle-speed change lets suppliers calmly replace when old machines depreciate, with almost no impact on Serverless market.
General-purpose microprocessor performance problems won't reduce demand for faster computing. There are two directions. For functions written in high-level scripting languages (such as JavaScript or Python), can produce language-specific custom processors through hardware-software co-design, running 1 to 3 orders of magnitude faster. Another direction is Domain Specific Architectures (DSA). DSA can be tailored for specific problem domains, with significant performance and efficiency improvements for that domain, but performs poorly in other domains. Graphics Processing Units (GPU) have long been used to accelerate graphics processing. We're starting to see DSA in machine learning field, such as Tensor Processing Units (TPU). TPU can be 30 times faster than CPU. This is just one of many examples. Using DSA to enhance general-purpose processors for individual domains will become normal.
For hardware heterogeneity, similarly there are two directions:
-
Serverless cloud contains multiple instance types, pricing depends on specific hardware used
-
Cloud providers can automatically select language-based accelerators and DSA. This automation can be implicitly completed based on software libraries or languages used by cloud functions, such as CUDA code uses GPU, while TensorFlow code uses TPU. Or, cloud providers can monitor cloud function performance and migrate them to more suitable hardware on next run.
For x86 SIMD instructions, Serverless is facing heterogeneity. AMD and Intel rapidly improve this part of x86 instruction set by increasing operations executed per clock cycle and adding new instructions. For applications using SIMD instructions, running on recent Intel Skylake microprocessors (512-bit wide SIMD instructions) is much faster than on old Intel Broadwell microprocessors (128-bit wide SIMD instructions). Currently both microprocessors are supplied at same price in AWS Lambda, but Serverless users have no way to indicate wanting faster SIMD hardware. In our view, compilers should give suggestions on which hardware is most suitable.
As accelerators become more popular in cloud environments, Serverless cloud providers won't be able to ignore heterogeneity dilemma, especially because reasonable remedies exist.
VII. 6 Misunderstandings About Serverless
Cloud functions are more expensive per minute, therefore Serverless is more expensive than Serverful
Because Serverless pricing is not just resource instances, but includes all system management functions, such as availability redundancy, monitoring, logging, and scaling. Moreover, Serverless scaling granularity is finer, meaning actual compute used may be more efficient. More importantly, Serverless doesn't need to pay when cloud functions aren't called, therefore may be much cheaper than Serverful.
Serverless may produce unpredictable costs
For some users, pay-as-you-go also means unpredictable costs, which contradicts budget management approaches of many organizations. For example, wanting to know Serverless service costs for next year when approving budgets. Cloud providers can alleviate this need by offering bucket-based pricing, just like phone companies provide fixed-rate plans for specific usage. Even after Serverless becomes popular, can predict Serverless service costs based on history.
Serverless uses high-level languages like Python for programming, so easy to port to different Serverless platforms
Under different platforms, not only function calls and packaging methods differ, but many Serverless applications also rely on non-standardized BaaS product/service ecosystems (such as object storage, KV databases, logs and monitoring, etc., to achieve portability). Must form standardized APIs, such as Google's Knative project exploring in this direction.
Under Serverless, vendor lock-in is stronger
If application porting is difficult, there will be strong binding with vendors. Cross-cloud support provided by frameworks can alleviate this strong binding.
Cloud functions cannot handle applications with extremely low latency performance requirements
Serverful instances can handle such scenarios because they're always running, can respond quickly after receiving requests. But if cloud function startup latency cannot meet application requirements, can adopt some strategies to alleviate, such as warming up by periodically executing cloud functions.
Few so-called elastic services can meet Serverless's actual flexibility requirements
"Elastic" in Serverless refers to ability to quickly change capacity, with less user intervention the better, and should scale down to 0 when not in use. What cloud providers usually offer is only limited elasticity (such as only allowing instantiating integer number of Redis instances, requiring explicit capacity configuration, even taking minutes to respond to demand changes), not meeting these requirements, thereby losing many Serverless advantages.
Due to lack of clear technical definitions and metrics, the term "elastic" is vague.
VIII. Summary and Predictions
By providing simplified programming environment, Serverless makes cloud easier to use, thereby attracting more users. Serverless includes FaaS and BaaS products, marking important maturity in cloud programming. Eliminates burden of manual management and resource optimization that Serverful brings to application developers today. This maturity is like transitioning from assembly language to high-level languages over 40 years ago.
Predict Serverless applications will surge, and hybrid cloud-native applications will become fewer, although some deployments may remain due to regulatory constraints and data governance rules.
Although already achieved certain success, many challenges still exist. If these problems can be overcome, Serverless can become popular in wider range of applications. First step is Serverless ephemeral storage, must provide low latency, high IOPS (ephemeral storage services) at reasonable cost, but doesn't need to provide affordable long-term storage. Second category of applications will benefit from Serverless persistent storage, because they do need long-term storage. New non-volatile memory technologies may help such storage systems. Other applications will benefit from low-latency signaling services and support for popular communication mechanisms.
Two major challenges for Serverless future are improving security and adapting to cost-performance improvements possibly from specialized processors. Some existing Serverless characteristics help address these challenges, such as:
-
Physical co-residency is necessary condition for side-channel attacks. In Serverless, difficult to confirm (whether on same physical machine), and easy to take protective measures, such as randomly distributing cloud functions
-
Cloud functions programmed in high-level languages (such as JavaScript, Python, or TensorFlow) elevate programming abstraction level, more conducive to underlying hardware innovation
Finally, predict Serverless Computing in next 10 years:
-
New BaaS storage services will emerge, letting more types of applications run on Serverless. Such storage can reach performance of local block storage, divided into ephemeral and persistent. Compared to traditional x86 microprocessors, computer hardware heterogeneity under Serverless is much greater.
-
Will be easier to program securely than serverful. Thanks to high-level programming abstractions, and fine-grained isolation of cloud functions.
-
Serverless billing models will improve, because there's no reason for its costs to be higher than serverful. So vast majority of applications running at any scale won't have higher costs under Serverless, or even lower.
-
Serverful will be used to promote BaaS services. Applications difficult to implement on Serverless (such as OLTP databases or communication mechanisms like queues, etc.), may be provided as part of cloud provider service sets.
-
Although serverful won't disappear, its importance will gradually decrease as Serverless breaks through current limitations.
-
Serverless will become default computing mode of cloud era, largely replacing serverful, thereby ending Client-Server era.
No comments yet. Be the first to share your thoughts.