1. Starting from Network Reliability
Machines can transmit signals and exchange information through physical connections (such as cables, telephone lines, radio waves, satellites, or infrared beams, etc.):
However, some abnormal conditions may occur during data transmission, such as:
-
Data loss: Data packets may arrive at a router whose buffer is already full, and then be dropped
-
Order errors: A group of data packets may pass through multiple routers with different load levels, experiencing varying degrees of delay, and the final arrival order may be inconsistent with the sending order
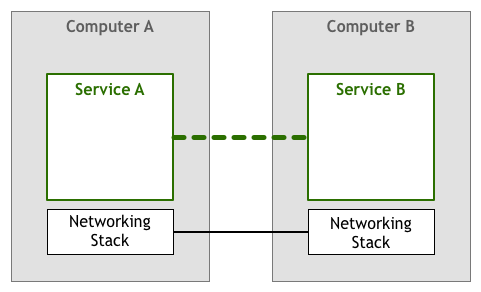
So at least there must be control mechanisms such as packet loss retransmission and order reassembly. In the early days, this work was completed by network services/applications (coexisting with business logic at the application layer):
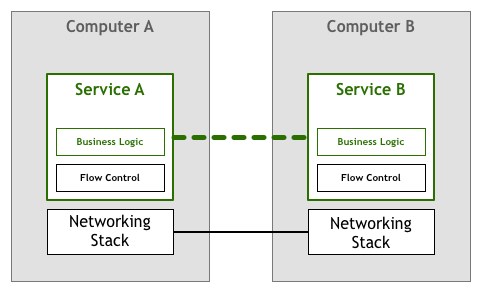
Later, this work sank to the network stack (the network layer of the operating system), and standard network protocols such as TCP/IP guarantee the reliability of data transmission (the thick line in the figure below):
2. Reliability Challenges in Microservices Architecture
The reliability guarantees provided by network protocols are sufficient for small-scale multi-machine interconnection scenarios, but in large-scale distributed scenarios (such as Microservices Architecture), more mechanisms need to be introduced to ensure overall reliability, such as:
-
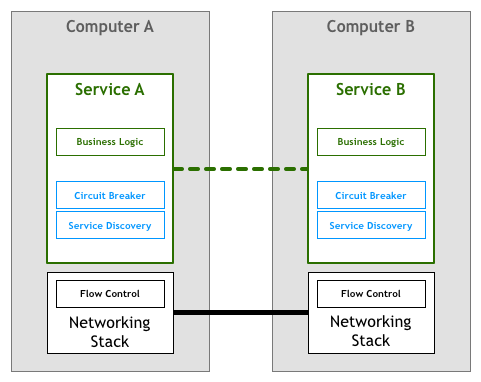
Service Discovery Mechanism: Through service registration and query mechanisms, allowing one microservice to find another, thereby allowing dynamic scaling and failover
-
Circuit Breaker Mechanism (Circuit Breaker pattern): Provides circuit protection (like a circuit breaker tripping), preventing a service from being unavailable from causing cascading failures, such as unsuccessful operations leading to crazy retries, request accumulation, and even exhausting related resources, causing failures in unrelated parts of the system
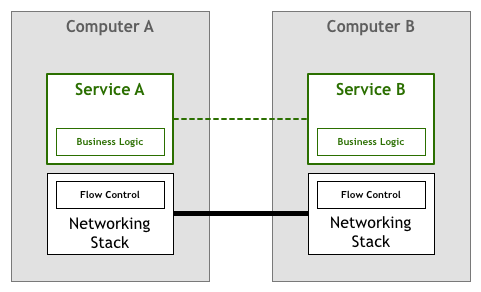
Similarly, this work was also completed by microservices in the early days (coexisting with business logic in microservices):
Then open source libraries such as Finagle and Proxygen appeared, these works are completed by specialized libraries, without having to repeat the same control logic in each service:
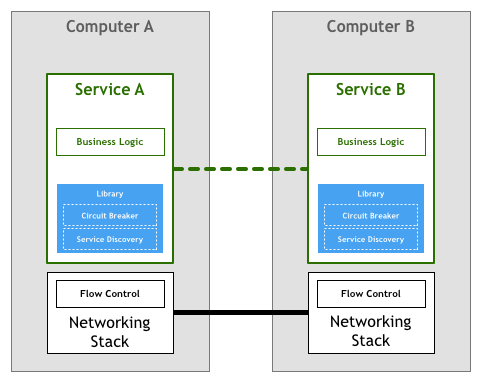
However, as the number of services in the system increased, this approach also exposed some problems:
-
Resource investment in glue parts: Resources need to be invested to connect third-party libraries with the rest of the system
-
Libraries limit microservice technology selection: These libraries are usually platform-specific, supporting only specific runtimes or programming languages, which limits the technology choices for microservices. After all, one of the major features of microservices is allowing different services to be written in different programming languages)
-
Library maintenance costs: The libraries themselves also need continuous maintenance and upgrades, and every update requires redeploying all services, even if the services have no changes
Looking at it this way, libraries don't seem to be an ideal solution
3. Sink Microservice Control to Network Stack?
Since solving at the application layer is not quite suitable, can we follow the same approach and sink to the network stack?
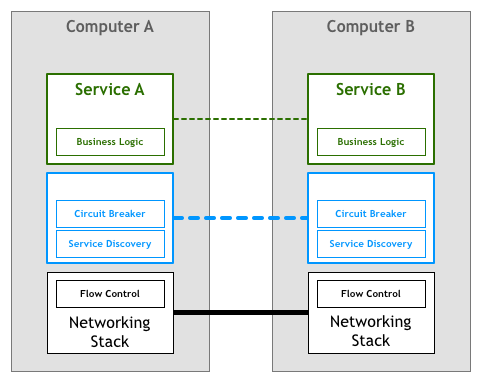
Unlike general basic communication mechanisms, these application service-related control mechanisms are difficult to implement by the lower network stack, and copying the sinking approach doesn't work
Sidecar
Can't be inside (the service), can't be below, so finally placed to the side:
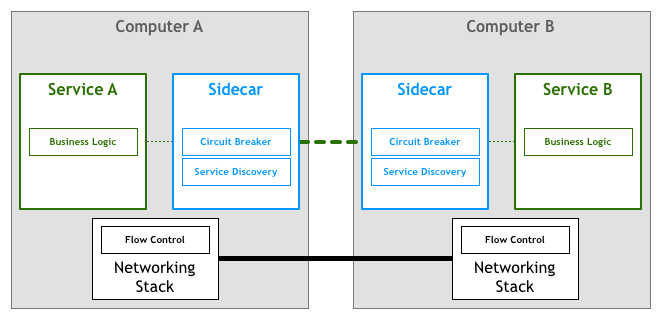
That is, implement these network controls through proxies, with all inbound and outbound traffic going through the proxy, called Sidecar:

Sidecar as an auxiliary process runs alongside the application and provides additional functionality for it
The problem seems to have been perfectly solved through network proxies, and the industry has also produced some open source solutions:
However, these solutions are built on specific infrastructure components, for example, Nerve and Synapse are based on Zookeeper, Prana is based on Eureka, and cannot adapt to different infrastructure components
So, is there a solution flexible enough and infrastructure-agnostic?
Yes. It's called Service Mesh
4. From Sidecar to Service Mesh
If each service is equipped with a proxy Sidecar, and services communicate with each other only through proxies, a deployment model like this is finally obtained:
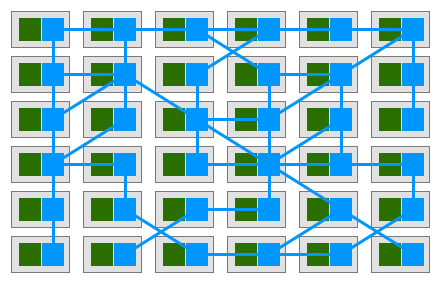
That is, proxies are connected to each other forming a mesh network, called Service Mesh:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It's responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application.
A dedicated infrastructure layer for handling service-to-service communication, guaranteeing communication reliability in complex service topologies
Specifically, Service Mesh can provide Service Discovery, load balancing, encryption, observation/tracing, authentication and authorization, and circuit breaker pattern support:
The mesh provides critical capabilities including service discovery, load balancing, encryption, observability, traceability, authentication and authorization, and support for the circuit breaker pattern.
From Sidecar to Service Mesh, the key is to view these proxies from a higher perspective and discover the value of the network they form:
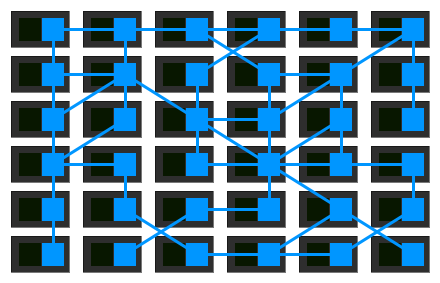
5. Service Mesh + Deployment Platform
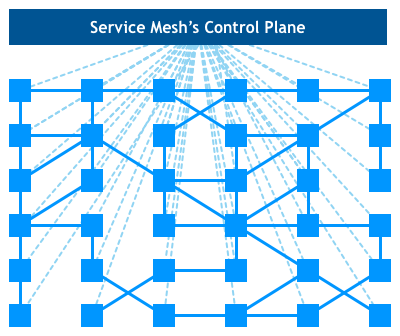
Subsequently, Service Mesh naturally sparked with deployment platforms (that control Services) (such as Istio + Kubernetes), and then derived a Control Plane, making this infrastructure layer configurable:
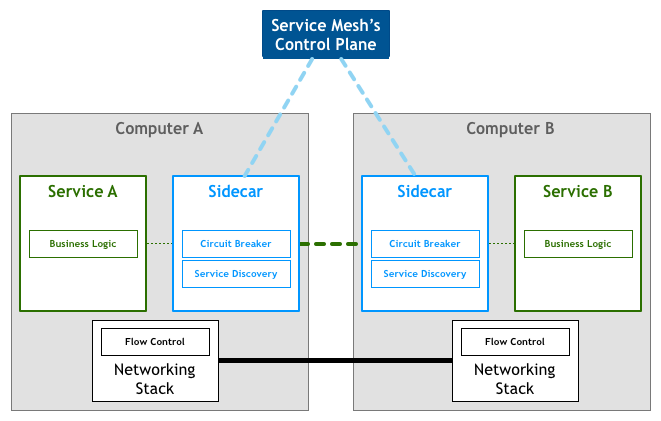
And finally formed an upper-lower structure of Control Plane + Data Plane:

Among them, the part that manages network traffic between instances is called the Data Plane, and the behavior of the Data Plane is controlled by configuration items generated by the Control Plane, and the Control Plane generally provides multiple ways to manage applications such as API, CLI, and GUI
That is:
No comments yet. Be the first to share your thoughts.