Preface
We cannot have a storage medium that is large, fast, and cheap at the same time. Therefore, many products of trade-offs have emerged:
-
CPU Registers: Extremely fast, but neither cheap nor large.
-
RAM: Not particularly fast or large, but relatively cheap.
-
Hard Disk: Very cheap with large capacity, but slow read/write speeds.
This eventually formed the following hierarchy:

Similarly, system design faces many trade-offs:
-
Performance vs. Scalability
-
Latency vs. Throughput
-
Availability vs. Consistency
1. Performance vs. Scalability
Scalability means a service can increase its performance proportionally by adding resources:
A service is scalable if it results in increased performance in a manner proportional to resources added.
Performance improvement is reflected in being able to handle a larger workload or process larger and heavier tasks (e.g., an increase in data volume).
P.S. Of course, adding resources might also be aimed at improving service reliability, such as introducing redundancy.
However, adding resources also introduces heterogeneity. Some nodes may have more processing power than others, while older nodes may be weaker. Since the system must adapt to this heterogeneity, algorithms that rely on homogeneity will underutilize new nodes, subsequently impacting performance.
2. Latency vs. Throughput
Latency is the time required from executing an operation to producing a result:
Latency is the time required to perform some action or to produce some result.
Its unit of measure is time, such as seconds, nanoseconds, system clock cycles (clock periods), etc.
Throughput is the number of operations processed or results produced per unit of time:
Throughput is the number of such actions executed or results produced per unit of time.
It is measured by the amount of output produced per unit of time. For example, memory bandwidth measures the throughput of a memory system. For web systems, these units of measure are used:
-
QPS (Queries Per Second): Used to measure the search traffic of an information retrieval system (such as search engines, databases, etc.) within 1 second.
-
RPS (Requests Per Second): The maximum number of requests a request-response system (such as a web server) can handle per second.
-
TPS (Transactions Per Second): In a broad sense, it refers to the number of atomic operations that can be executed within 1 second; in a narrow sense, it refers to the number of transactions a DBMS can execute in 1 second.
P.S. QPS is also commonly used to measure the throughput of web services, but the more accurate unit is RPS.
Similarly, because it is impossible to have both low latency and high throughput, the principle of trade-off is:
Generally, you should strive for maximal throughput with acceptable latency.
While ensuring that latency is acceptable, aim for maximum throughput instead.
3. Availability vs. Consistency
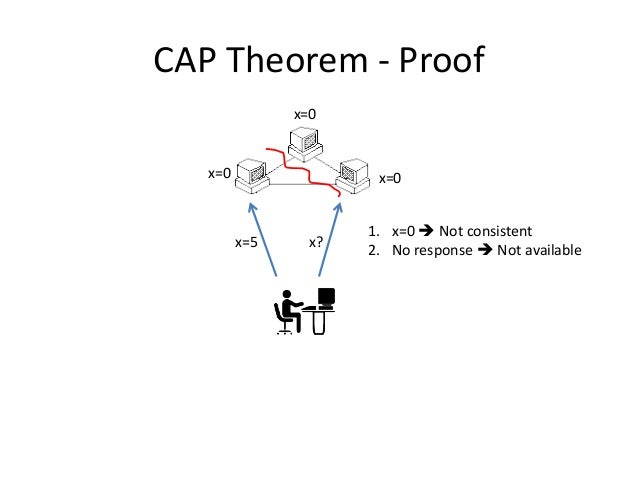
Regarding availability and consistency, there is the famous CAP Theorem:
Of three properties of distributed data systems - consistency, availability, partition tolerance - choose two. —— Eric Brewer, CAP theorem, PODC 2000
In a distributed computer system, you can only choose two out of three properties (and partition tolerance is mandatory):
-
Consistency: Every read receives the most recent write or an error.
-
Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
-
Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped or delayed by the network between nodes.
Because networks are not perfectly reliable, partition tolerance must be guaranteed (P is mandatory). When some nodes experience network failure, there are two choices:
-
Cancel the operation: Ensures consistency but reduces availability (users may receive timeout errors). This is CP (Consistency and Partition Tolerance), suitable for scenarios requiring atomic reads and writes.
-
Continue the operation: Ensures availability but poses a consistency risk (the information returned may be outdated). This is AP (Availability and Partition Tolerance), suitable for scenarios that can accept eventual consistency.
In other words, given that P must be satisfied (network failure is an uncontrollable factor outside the system; there is no choice), you can only make a trade-off between C and A: either ensure consistency (sacrificing availability) or ensure availability (sacrificing consistency). That is:
Possibility of Partitions => Not (C and A)
(Excerpt from 10. Why do some people get annoyed when I characterise my system as CA?)
P.S. Of course, in centralized systems (such as RDBMS), network reliability is not an issue, so both C and A can be achieved.
4. Consistency Models
If multiple copies of the same data exist, then you need to consider how to ensure their consistency. Strict consistency means either reading the latest data or receiving an error.
However, not all scenarios require such consistency, leading to products of compromise like weak consistency and eventual consistency.
Weak Consistency
After a write, a subsequent read may or may not return the value.
Weak consistency is suitable for real-time scenarios like VoIP, video chat, and real-time multiplayer games. After a VoIP call is reconnected, you won't receive the conversation that occurred during the disconnection.
Eventual Consistency
After a write, data is asynchronously replicated, ensuring that a subsequent read will eventually return the value.
Eventual consistency is suitable for high-availability systems such as DNS and email.
Strong Consistency
After a write, data is synchronously replicated, and a subsequent read will return the value immediately.
Strong consistency is suitable for scenarios requiring transactional mechanisms, such as file systems and RDBMS.
5. Availability Models
Regarding availability guarantees, there are two main methods: failover and replication.
Failover
After a node goes down, it is quickly replaced by another node to minimize downtime. Specifically, there are two failover models:
-
Active-Passive (Master-Slave failover): Only the active server handles traffic. Heartbeat messages are sent between the active server and the standby passive server. If the heartbeats stop, the passive server takes over the active server's IP address and resumes service. Downtime depends on whether the passive machine is a hot or cold standby.
-
Active-Active (Master-Master failover): Both servers handle traffic and share the load.
In Active-Passive mode, there is a risk of data loss (during switching), and either way, failover increases hardware resources and complexity.
Replication
Divided into Master-Slave replication and Master-Master replication, often used in databases; I won't expand on this for now.
Availability Metrics
Availability is usually measured by the number of nines, representing the percentage of uptime relative to total runtime.
Three nines means 99.9% availability, i.e.:
| Period | Downtime Allowed |
|---|---|
| Annual Downtime | 8h 45m 57s |
| Monthly Downtime | 43m 49.7s |
| Weekly Downtime | 10m 4.8s |
| Daily Downtime | 1m 26.4s |
Four nines is 99.99% availability:
| Period | Downtime Allowed |
|---|---|
| Annual Downtime | 52m 35.7s |
| Monthly Downtime | 4m 23s |
| Weekly Downtime | 1m 5s |
| Daily Downtime | 8.6s |
Specially, for a service composed of multiple parts, its overall availability depends on whether these parts are in serial or parallel:
// Serial
Availability (Total) = Availability (Foo) * Availability (Bar)
// Parallel
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
When two services with less than 100% availability are combined, if they are in serial, the overall availability decreases (99.9% * 99.9% = 99.8%); if they are in parallel, the overall availability increases (1 - 0.1% * 0.1% = 99.9999%).
No comments yet. Be the first to share your thoughts.