寫在前面
[上一篇筆記](/articles/uniform 變量與片元著色器-webgl 筆記 4/) 中,我們用比較笨的方式繪製了多個點,效率低,而且無法繪製三角形這樣的基本圖元,複雜圖形就更無從談起了
一。認識 buffer
buffer 是 WebGL 系統內部劃分出的一塊區域,可以存放一組頂點數據,比如頂點坐標,把頂點數據寫入 buffer 後,著色器程序執行時就可以從 buffer 中讀取數據,在數據量較大時尤為方便
著色器程序中雖然不能直接讀 buffer,但可以先通過 API 來指定著色器變量值為 buffer 的地址,再指定數據讀取方式,例如從哪裡開始讀?讀幾個數?下一個頂點的數據在哪裡?間接地從 buffer 中讀取數據
二。類型化數組
準備頂點數據本來沒有必要單獨拿出來討論,但這一步很容易錯,正確代碼如下:
// 一次性傳遞一組頂點數據
//!!! 注意:不是一般數組,需要 new 類型化數組,否則報錯
// GL ERROR :GL_INVALID_OPERATION :glDrawArrays: attempt to access out of range vertices in attribute 0
// var arrVtx = [-1.0, 1.0, 1.0, 1.0, -1.0, -1.0, 1.0, -1.0, 0.0, 0.0];
var arrVtx = new Float32Array([-1.0, 1.0, 1.0, 1.0, -1.0, -1.0, 1.0, -1.0, 0.0, 0.0]);
特別注意:準備向 buffer 寫入的數據不是一般數組,需要 new 類型化數組,否則報錯,錯誤信息如下:
GL ERROR :GL_INVALID_OPERATION :glDrawArrays: attempt to access out of range vertices in attribute 0
單從錯誤信息很難追溯到頂點數據上,所以才要特別注意
因為 GLSL ES 是強類型語言,js 是弱類型的,js 數組元素沒有限制,而 GLSL ES 需要非常嚴格的數據,所以才有了類型化數組。在 WebGL 中,類型化數組有以下 8 種:
-
Int8Array
-
UInt8Array
-
Int16Array
-
UInt16Array
-
Int32Array
-
UInt32Array
-
Float32Array
-
Float64Array
區別是每個元素所佔字節數不同(類型化數組有 BYTES_PER_ELEMENT 屬性,可以獲取數組內每個元素所佔字節數,比如 Float32Array 每個元素佔 4 個字節),與普通數組相比,類型化數組不支持push 和 pop 方法,但針對「大量元素都是同一種類型」做了優化
三。使用 buffer
從創建 buffer 到寫入一組頂點數據,我們需要做 5 件事
###1. 創建 buffer
直接調用 API 創建 buffer,如下:
// 1. 創建 buffer
var vBuffer = gl.createBuffer();
if (!vBuffer) {
console.log('Failed to create buffer');
return;
}
若創建失敗,則返回 null,但由於這種函數出錯率比較低,此處不做嚴格的錯誤判斷(而出錯率高的部分一定要做嚴格的判斷,比如編譯著色器源程序)
###2. 把緩衝區對象綁定到目標
創建緩衝區後需要把緩衝區對象綁定到 WebGL 系統中已經存在的 target 上
// 2. 把緩衝區對象綁定到目標
gl.bindBuffer(gl.ARRAY_BUFFER, vBuffer);
buffer 都創建好了,下一步不應該是寫入數據嗎?綁定目標做什麼?
因為我們無法直接向緩衝區寫入數據,只能向 target 寫入,所以要向緩衝區寫數據,必須要先綁定 target 與 buffer。target 表示緩衝區對象的用途,值為 gl.ARRAY_BUFFER 或者 gl.ELEMENT_ARRAY_BUFFER,前者表示緩衝區對象包含了頂點數據,後者表示包含了頂點的索引值
###3. 向緩衝區對象寫入數據
通過 gl.bufferData(target, data, usage) 寫入數據
// 3. 向緩衝區對象寫入數據
gl.bufferData(gl.ARRAY_BUFFER, arrVtx, gl.STATIC_DRAW);
其中 data 是類型化數組,前面已經介紹過了
usage 表示緩衝區數據用途,WebGL 會根據用途進行優化,值為 gl.STATIC_DRAW(只向緩衝區對象寫入一次數據,但需要繪製很多次)、gl.STREAM_DRAW(只向緩衝區對象中寫入一次數據,然後繪製若干次)或 gl.DYNAMIC_DRAW(向緩衝區對象多次寫入數據,並繪製很多次),區別不是很明顯,而且只會影響性能,不會影響最終結果
###4. 將緩衝區對象分配給 a_Position 變量
buffer 準備好了,現在要給著色器變量賦值,並告訴著色器這些數據待會兒怎麼用
// 4. 將緩衝區對象分配給 a_Position 變量
gl.vertexAttribPointer(a_Position, 2, gl.FLOAT, false, 0, 0);
// 等價於
// gl.vertexAttribPointer(a_Position, 2, gl.FLOAT, false, arrVtx.BYTES_PER_ELEMENT * 2, 0);
通過 gl.vertexAttribPointer(location, size, type, normalized, stride, offset) 給 attribute 對象賦值緩衝區指針,參數含義如下:
gl.vertexAttribPointer(location, size, type, normalized, stride, offset)
---
size 緩衝區中每個頂點的分量個數(1~4),表示每個頂點數據中要賦值給著色器變量的分量個數
type 數據格式,值為 gl.UNSIGNED_BYTE、gl.SHORT、gl.UNSIGNED_SHORT、gl.INT、gl.UNSIGNED_INT、gl.FLOAT 五種
normalized true|false,表示是否把非浮點型數據歸一化到 [0, 1] 或者 [-1, 1] 區間
stride 指定相鄰兩個頂點間的字節數,預設為 0
offset 緩衝區對象中的偏移量,從緩衝區的 offset 位置開始寫,從頭開始就是 0
特別注意:stride 參數比較特別,如果每個頂點有 n 個數據,把 stride 置為 arr.BYTES_PER_ELEMENT * n 的效果和 0 一樣。因為當前頂點數據讀取結束後,如果 stride 為 0,則從當前頂點數據結束的位置開始讀取下一個頂點的數據,如果 stride 非 0,則從當前頂點數據開始的位置跳過 stride 指定的字節再開始讀取
P.S. 可能不好理解,但事實就是這樣,我們在以後的具體例子中再解釋
###5. 連接 a_Position 變量和分配給它的緩衝區對象
buffer 準備好了,也告訴著色器數據該怎麼用了,最後還要連接變量和緩衝區
//!!! 注意:分配完還要 enable 連接
// 5. 連接 a_Position 變量和分配給它的緩衝區對象
gl.enableVertexAttribArray(a_Position);
這一步很容易忘記,因為從邏輯上看已經完整了,這一步純屬多餘,但 API 就是這樣,這一步就像下圖的開關:
[caption id="attachment_901" align="alignnone" width="893"]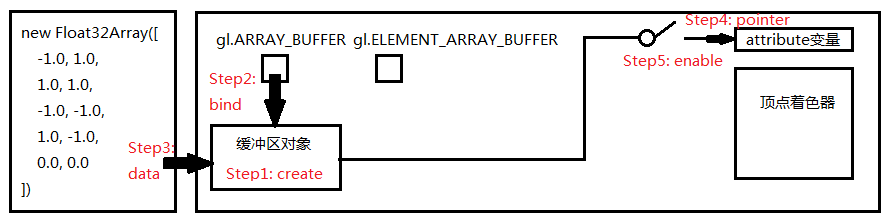 webgl-buffer[/caption]
webgl-buffer[/caption]
###6. 繪製多個點
// 繪製點
gl.drawArrays(gl.POINTS, 0, arrVtx.length / 2);
終於用上了第三個參數,不再是 draw a point 了,第三個參數表示要繪製的頂點個數,本例中數組長度 arrVtx.length 除以每個頂點的數據數 2 表示繪製 arrVtx 中的全部頂點(共 5 個)
四。DEMO
包含上述代碼的完整的例子,請查看:http://www.ayqy.net/temp/webgl/buffer/index.html
五。總結
本例中,我們用 buffer 傳入了 5 個點的坐標(4 個角以及中心),一次性繪製了出來,解決了最基本的輸入數據的問題
解鎖了 buffer 後就可以去摸摸圖元以及稍複雜的圖形了,下一篇筆記中我們要畫最神奇的圖元——三角形。這樣誇三角形真的沒錯,事實上,三角帶可以拼出整個世界,人物模型、BOSS 模型、花草樹木等等一切都是三角帶拼出來的
參考資料
- 《WebGL 編程指南》
暫無評論,快來發表你的看法吧