寫在前面
為了提升數據庫的處理能力,我們把單庫擴展成多庫,並通過更新同步機制(即 Replication)來保證多份數據的一致性。如此這般,數據庫的擴展難題似乎已經順利解決了
然而,在 Replication 方案下,每個數據庫都持有一份完整數據,基於全量數據提供增刪改查服務,單庫的性能瓶頸仍然存在,並將成為限制系統擴展性的關鍵因素
一。單庫的性能瓶頸
單機的硬件資源是有限的,因此單庫的處理能力也是有限的:
-
容量有限:數據量可能大到單庫無法容納
-
性能有限:單庫的讀寫性能同樣受數據量影響,查詢/更新越來越慢
單靠加機器/加庫顯然無法直接解決單機/單庫的性能問題,除非進一步打破庫的邊界,把單庫拆分成多庫(而不只是複製多份)
P.S. 理論上,Web 應用層也面臨同樣的問題,卻不曾聽說過一個 Web 服務龐大到單機無法部署,這是因為Web 服務在設計之初就會考慮職責劃分與解耦,以便各部分能夠獨立部署、獨立擴展,從 20 年前的 SOA(即面向服務架構,包括 微服務架構(Microservices) 等變體)起便是如此
二。分區(Partitioning)
為了避免單庫性能成為系統可擴展性的瓶頸,通常把邏輯數據庫(或其組成元素,例如數據表)拆分成各個獨立部分,這種做法稱為分區(Partitioning):
A partition is a division of a logical database or its constituent elements into distinct independent parts.
(摘自 Partition (database))
就像微服務架構中把單體應用(Monolithic application)拆分成一組小型服務一樣,我們通過分區把單庫拆分成一組(數據規模)更小的庫,各自處理一部分數據,共同分擔流量,主要優勢體現在:
-
可擴展性:把單庫數據拆分到多庫後,系統的可擴展性不再受限於單庫性能,數據庫層「無限」擴展成為了可能
-
性能:單庫數據量減少,數據操作更快,甚至允許多庫並行操作
-
安全性:可以針對(拆出去的)敏感數據,採取更強的安全控制
-
靈活性:可以對不同的庫(比如按數據重要性)採用不同的監控、備份策略,以縮減成本,提升管理效率。或者對不同類型的數據選用不同的存儲服務,比如大型二進制內容放到 blob 存儲中,更複雜的數據可以存放在文檔數據庫中
-
可用性:把數據分散放到多個籃子裡,能夠避免單點故障,並且單庫故障僅影響一部分數據
具體的,有 3 種拆分策略:
-
水平分區(Horizontal partitioning,也叫 Sharding):按行拆分,把不同的行放入不同的表中
-
垂直分區(Vertical partitioning):按列拆分,把一些列放到其它表中
-
按功能分區(Functional partitioning,有時也叫 Federation):按業務功能拆分,把業務領域中屬於相同界限上下文(Bounded Context)的數據放在一起
當然,這 3 種策略並不衝突,可以結合使用
P.S. 關於領域驅動設計(Domain-Driven Design),以及界限上下文的更多信息,見 去中心化數據管理(Decentralized Data Management)
三。水平分區
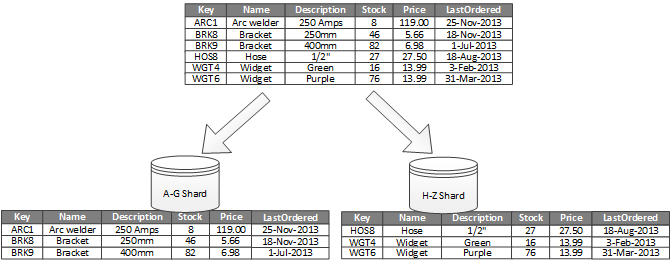
水平分區,即分片(Sharding)。每片(shard)都是原數據的一個子集,共同構成完整的數據集:
A database shard is a horizontal partition of data in a database or search engine. Each individual partition (or server) acts as the single source for this subset of data.
(摘自 Shard (database architecture))
與垂直分區相比,水平分區最大的特點是schema 保持不變:
Each partition is a separate data store, but all partitions have the same schema.
就像把一張表橫向切幾刀,分成幾段小表,它們的表結構(字段等)完全一致
這種橫向拆分減少了單庫所需存儲的數據量,以及所需承載的流量/操作,另一方面,還減少了資源爭用(contention),有助於提升性能
shard key 的選取
具體操作上,關鍵在於如何選取 shard key(按哪個字段的什麼特徵來分片),盡可能保證負載被均勻地分散到每一片上
注意,均勻並不意味著要求每一片的數據量均等,重點是均分流量(有些片可能數據量很大,但訪問量卻很低)
同時還要避免產生「熱點」,比如按姓氏首字母對用戶信息進行分片實際上是不均勻的,因為有些字母更常見,此時按用戶 ID 哈希值來分片可能更均勻些
四。垂直分區
另一種拆分方式是垂直分區,將一些列(字段)拆分到其它表中:
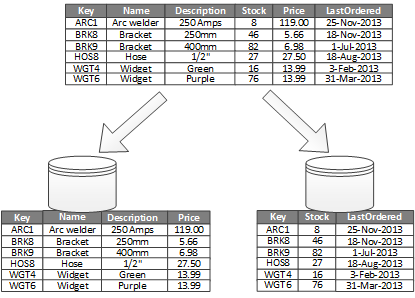
多用於減少 I/O、降低性能成本,比如,按使用頻率把常用字段和不常用的字段分開
比起水平分區,垂直分區的關鍵優勢在於把信息拆的更細,進而允許一些針對性的優化,比如把不經常變化的數據拆分出來,丟到緩存中,把照片等大型二進制內容拆出去單獨存放,或者對部分敏感數據進行針對性的安全控制,另一方面,細粒度的數據劃分也能夠消除一些並發訪問,降低並發訪問量
五。按功能分區
此外,還可以結合具體應用場景,按業務功能拆分:
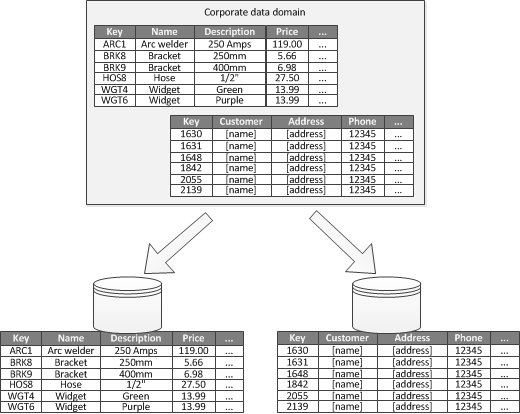
把不相干的數據剔除出去(把緊密相關的數據放到一起),有助於加強數據隔離,提升數據訪問性能,比如把客戶信息和商品庫存信息分開
六。分區的代價
把單庫拆成多庫,雖然能夠解決數據庫的擴展性難題,但也引發了一些新問題:
-
連表查詢慢:盡量避免跨分區 join、或者考慮並行查詢
-
全表查詢慢:對於需要掃描全量數據的查詢操作,即便有並行優化也慢,可以通過垂直分區、按功能分區來定位目標分區,避免全表查詢,至於水平分區,可以在應用層維護一張映射表,加快分區定位
-
不支持事務操作:將事務操作交由應用層來處理
-
負載不勻導致分區效果大打折扣:考慮增加監控,並根據分析預測定期調整
誠然,其中有些問題沒有非常漂亮的解決方案,實際應用中更多的是面向特定場景的權衡取舍
參考資料
-
[How Sharding Works](https://medium.com/ @jeeyoungk/how-sharding-works-b4dec46b3f6)
暫無評論,快來發表你的看法吧