寫在前面
JavaScript 的字串處理貌似不難,直到遇上了 emoji:
[caption id="attachment_1801" align="alignnone" width="626"]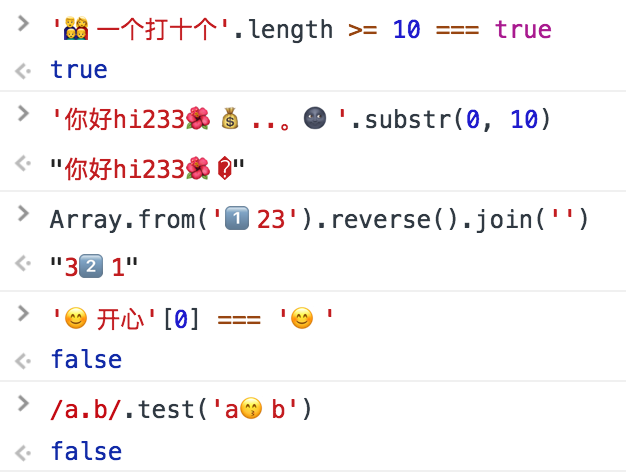 javascript-emoji-issues[/caption]
javascript-emoji-issues[/caption]
??發生了什麼?到底怎麼回事?
得從 Unicode 編碼說起……
一. Unicode 編碼
The Unicode codepoint range goes from U+0000 to U+10FFFF which is over 1 million symbols, and these are divided into groups called planes. Each plane is about 65000 characters (16^4). The first plane is the Basic Multilingual Plane (U+0000 through U+FFFF) and contains all the common symbols we use everyday and then some. The rest of the planes require more than 4 hexadecimal digits and are called supplementary planes or astral planes.
也就是說, Unicode 支援的編碼範圍是 U+0000 到 U+10FFFF ,能對應 100 多萬個符號( 0x10FFFF === 1114111 )。這些符號被分組歸入 16 個平面 (panel) ,所以每個平面放 65536( 16^4 === 65536 )個
其中,常用符號都放在第一個平面( U+0000 到 U+FFFF )裡,所以稱之為基本多語言平面 (Basic Multilingual Plane,也簡稱 BMP) ,其餘的平面中的碼位值 (codepoint,即符號對應的 Unicode 編碼值) 都大於 4 位(16 進位),稱為輔助平面 (supplementary plane)
P.S. 輔助平面還有個看起來很厲害的名字,叫 astral plane(星界?星界位面?)
I have no idea if there’s a good reason for the name “astral plane.” Sometimes, I think people come up with these names just to add excitement to their lives.
此外,基本多語言平面裡 65536 個位置的入住率並不是 100% ,專門空出來一些位置以備不時之需,比如新增特殊含義符號,或者擴充
比如 UTF-16 中代理對兒 (surrogate pairs) 的概念,即用兩個 4 位(16 進位)的小碼位值表示一個大碼位值(大於 4 位),算是一種從基本多語言平面到輔助平面的映射,之所以能這樣做,就是因為:
基本多語言平面內,從 U+D800 到 U+DFFF 之間的碼位區段是永久保留不映射到 Unicode 字元。 UTF-16 就利用保留下來的 0xD800-0xDFFF 區段的碼位來對輔助平面的字元的碼位進行編碼。
二. JavaScript 中的 Unicode
JS 中的 Unicode 字元有 3 種表示方法:
'A' === '\u0041' === '\x41' === '\u{41}'
其中 \x 僅用於 U+0000 到 U+00FF , \u 適用於任意 Unicode 字元( U+0000 到 U+10FFFF ),但大於 4 位(大於 U+FFFF )的話,就要用花括號( {} )把十六進位序列包起來:
The \x can be used for most (but not all) of the Basic Multilingual Plane, specifically U+0000 to U+00FF. The \u can be used for any Unicode characters. The curly braces are required if there are more than 4 hexadecimal digits and optional otherwise.
注意, \u{} 跳脫語法是在 ES 2015 中定義的,稱之為 UnicodeEscapeSequence 。之前用兩個小 Unicode 來表示一個大 Unicode,例如:
'' === '\u{1F4A9}'
'' === '\uD83D\uDCA9'
\uD83D\uDCA9 就是代理對兒,形如 <H,L> ,二者的轉換關係如下:
let C, L, H;
C = 0x1F4A9;
// 公式:大Unicode转代理对儿
H = Math.floor((C - 0x10000) / 0x400) + 0xD800;
L = (C - 0x10000) % 0x400 + 0xDC00;
[H, L].map(v => '\\u' + v.toString(16).toUpperCase()).join('')
"\uD83D\uDCA9"
另外,JS 中認為一個 16 位無符號整數值是一個字元,所以一個 emoji 可能會被認為是多個字元:
The phrase code unit and the word character will be used to refer to a 16-bit unsigned value used to represent a single 16-bit unit of text.
Unicode character only refers to entities represented by single Unicode scalar values: the components of a combining character sequence are still individual “Unicode characters”, even though a user might think of the whole sequence as a single character.
P.S. 關於 JavaScript 的 Unicode 支援以及 ES 規範的相關內容,見 JavaScript’s internal character encoding: UCS-2 or UTF-16?
正規表示式中的 Unicode
既然大 Unicode(大於 U+FFFF 的)在 JS 中用兩個小 Unicode(代理對兒)來表示,那麼自然會寫出這樣的正規表示式:
> /[\uD83D\uDCA9-\uD83D\uDE0A]/.test('')
Uncaught SyntaxError: Invalid regular expression: /[\uD83D\uDCA9-\uD83D\uDE0A]/: Range out of order in character class
報錯無法識別這樣的 range,那怎樣用正規表示式描述大 Unicode 字元範圍呢?
JS 提供了 u flag 來解決這個問題:
u Unicode; treat pattern as a sequence of Unicode code points
/[\uD83D\uDCA9-\uD83D\uDE0A]/u.test('')
/[-]/u.test('')
類似的, . (點號匹配任意字元)想要匹配代理對兒形式的大 Unicode 的話,也需要開啟 u flag:
> /foo.bar/.test('foobar')
false
> /foo.bar/u.test('foobar')
true
P.S. /./u 僅能匹配代理對兒形式的 emoji ,其他形式的不行,例如:
> /foo.bar/u.test('foo2??bar')
false
P.S. 更多相關範例,見 Astral ranges in character classes
fromCodePoint 與 fromCharCode
String.fromCodePoint 與 String.fromCharCode 的區別在於,前者支援更大範圍的 16 進位 Unicode 編碼,例如:
> String.fromCodePoint(0x1F4A9)
""
> String.fromCharCode(0x1F4A9)
"?"
但 fromCodePoint 由 ES 2015 規範定義,相容性不如 fromCharCode 好,對於 0x0000-0xFFFF 範圍的 65536 個 Unicode 字元,建議使用 fromCharCode
三. emoji 編碼
類似於 Unicode, emoji 也是一種編碼規則,也有對應的規範,還存在很多個版本:
Emoji 12.0
Emoji 11.0
Emoji 5.0
Emoji 4.0
Emoji 3.0
Emoji 2.0
Emoji 1.0
其中 12.0 計畫 2019 年才發布,最新的 11.0 發布於 2018-02-07
像 HTML、CSS 規範一樣,新版規範中新增的 emoji 不一定都被實作了,並且面臨的相容性問題比 HTML、CSS 更惡劣:
-
規範版本: emoji 規範發版頻繁,多版本共存
-
平台差異:除了 Web 瀏覽器環境外, emoji 還依賴平台原生支援(各種螢幕顯示設備)
-
依賴 Unicode: emoji 是在 Unicode 基礎上建立的,依賴 Unicode 規範
比如從簡訊複製貼上到網頁輸入框, emoji 可能就顯示不出來或者亂碼了,因為 native 與 Web 瀏覽器支援的 emoji 規範版本或實作程度存在差異。另外, Unicode 新規範可能��與已定義的 emoji 規範有衝突,這時候自然得由 emoji 規範讓步:
Unicode 12.0 is the new version of the Unicode Standard planned for release in March 2019. See Emoji 12.0 for a more complete list of potential emojis for 2019.
Note: All emojis listed throughout 2018 are candidates only, and subject to change before a final release.
emoji 面臨的環境有多惡劣呢?如圖:
[caption id="attachment_1802" align="alignnone" width="625"] emoji-unicode-platform[/caption]
emoji-unicode-platform[/caption]
回到 emoji 規範本身,長這樣子:
1F600 ; emoji ; L1 ; secondary ; x # V6.1 () GRINNING FACE
1F48F ; emoji ; L1 ; none ; j # V6.0 () KISS
最左邊是 Unicode 碼位值,被成功錄入 Unicode 規範的話, U+1F48F 就會對應 KISS 表情:
> '\u{1F48F}'
""
除了這種與 Unicode 一一對應的 emoji,加入 Unicode 大家庭外,還有幾種特殊的 emoji :
-
variation selector-16 :一個不可見字元(
U+FE0F),表示在它前面的字元應該用 emoji 顯示 -
zero width joiner :零寬連接符,是一個零寬空格(
U+200D),用來把多個 emoji 合成為一個 emoji -
tone modifier:膚色修飾,一種語法,能改變前一個 emoji 的膚色,語法格式是
<emoji>\ud83c[\udffb-\udfff],即U+D83C後面跟不同的幾個值表示不同的膚色控制 -
keycap:鍵帽符號,鍵帽樣式的
0-9、#和*,以U+20E3結尾 -
unofficial emoji flag:存在一些非常規國旗 emoji,以黑色旗子(
U+1F3F4)開頭, 取消符號 (U+E007F)結尾
例如:
// \ufe0f让黑心字符显示成emoji,连续两个也没关系
'???' === '\u2764\ufe0f\ufe0f'
'\u2764\ufe0f' === '??'
'\u2764' === '?'
// 零宽连接符\u200d合成复杂表情, + ?? + + = ?????
'?????' == '\ud83d\dc69\u200d\u2764\ufe0f\u200d\ud83d\udc8b\u200d\ud83d\dc69'
// 肤色修饰,黑baby、白baby
'' === '\ud83d\udc76\ud83c\udfff'
'' === '\ud83d\udc76\ud83c\udffb'
// 键帽样式
'#??' === '\u0023\ufe0f\u20e3'
// 非官方国旗
'' ==='\ud83c\udff4\udb40\udc67\udb40\udc62\udb40\udc73\udb40\udc63\udb40\udc74\udb40\udc7f'
四. JavaScript 裡的 emoji
那麼在 JS 裡,一個 emoji 到底含有幾個 Unicode 字元?
> '?'.length
1
> ''.length
2
> '1??'.length
3
> ''.length
4
> '???'.length
11
> ''.length
14
一個 emoji 字面量的長度從 1 到 14 (還可能存在更長的)各不相同……所以,會出現這種情況:
> '???我们是一家人'.slice(0, 1)
"?"
> '???我们是一家人'.substr(0, 2)
""
期望透過 slice(0, 1) 截取第一個 emoji,卻得到了一個無法顯示的字元,甚至 substr(0, 2) 從一家 4 口中拆出了 Man()……這可咋整?
對於某些 emoji,有一種非常簡單的處理方式, Array.from :
> Array.from('').length
1
字串轉陣列時會保持代理對兒在一起,所以 length 正確了,但這種方法不是萬能的:
> Array.from('???').length
7
P.S. 類似的,支援 Unicode 編碼轉換的 bestiejs/punycode.js 也存在類似的問題:
> punycode.ucs2.decode(' ').length
1
> punycode.ucs2.decode('???').length
7
也就是說,單靠 JS 對 Unicode 的原生支援,無法正確處理含 emoji 的字串。那麼,在一些場景會遇到問題:
-
表單檢驗字數限制
-
截取文章摘要
-
反轉字串
-
逐字元處理
-
正則匹配
-
……其他含 emoji 的文本處理場景
例如:
> '???一个打十个'.length >= 10 === true
true
> '你好hi233..。'.substr(0, 10)
"你好hi233?"
> Array.from('1??23').reverse().join('')
"32??1"
> '开心'[0] === ''
false
> /a.b/.test('ab')
false
P.S. 關於 JavaScript 中 Unicode 的更多問題,見 JavaScript has a Unicode problem
五. 解決方案: emoutils.js
要解決上面列出的一排問題,只能設法識別 emoji 了,目前 ( 2018/09/15 ) 貌似還沒有這樣的工具庫
手搓一個,類似於詞法分析 ,逐字元匹配,挑出符合 emoji 編碼規則的 Unicode 組合,具體見下面源碼
Github 位址: https://github.com/ayqy/emoji-utils
線上 Demo(測試 case): https://ayqy.github.io/emoji/index.html
API
提供了 6 個簡單 API:
// 是不是一個emoji
isEmoji(str)
// 是否包含emoji
containsEmoji(str)
// 字串轉Unicode陣列
str2unicodeArray(str)
// 計算長度
length(str)
// 子字串截取
substr(str = '', start = 0, len = Infinity)
// 字串轉陣列,相當於split('')
toArray(str)
內部未暴露的方法有:
// 嘗試匹配開頭的emoji,失敗傳回''
matchOneEmoji(str, matched = '')
缺陷
但是,這些工具函數並不 100% 靠譜,因為:
Not all browsers, UIs, etc even render ????? as a single symbol. The code assumes the joiners are used between characters appropriately which could be very problematic.
所以, emoutils.js 的實作基於 3 點假設:
-
所有代理對兒都是 emoji(事實上,有些代理對兒不是 emoji)
-
膚色控制對所有 emoji 都是有效的,並且只對 emoji 生效(對普通文本符號無效)
-
joiner 連接起來的 emoji 都算一個,無論顯示上能否被合成一個 emoji
對於第一點假設,代理對兒形式的不一定是 emoji,也可能是純文本,例如:
'\ud835\udc00' === ''
後兩點假設也會導致一些 badcase,例如(Chrome Console 環境):
// 嘗試製造黑色笑臉,未遂
'\ud83d\ude0a\ud83c\udfff' === ''
// 嘗試人工合成新物種,失敗
'\u0023\ufe0f\u20e3\u200d\ud83d\ude0a' === '#???'
'\ud83d\ude0a\u200d\ud83d\ude0a' === '?'
這些 case 都會被識別成 1 個 emoji,而 Chrome Console 環境顯示是 2 個,因為他們:
-
符合 emoji 編碼的語法規則
-
但不一定是合法的 emoji
-
即便合法,目前平台也不一定支援
emoutils.js 假設滿足第一點的就是一個獨立顯示的合法 emoji,未考慮 emoji 規範版本以及平台支援性,所以存在這樣的 badcase。 badcase 可能帶來的影響是:
-
isEmoji/containsEmoji()誤判類似於 '' 的文本字元 -
length()小於實際顯示的字元長度 -
substr()/toArray()與實際預期不符
所以能這個工具庫所能識別出的字元集是 emoji 的超集,多出來一部分代理對兒形式的文本,以及符合 emoji 編碼規則但在 emoji 規範中未定義的字元序列。儘管如此,實際應用中足夠應對大多數場景了
P.S. 對於需要準確處理 emoji 的場景,可以考慮 emoji-regex
暫無評論,快來發表你的看法吧