寫在前面
對於關係型數據庫,(必要時)我們可以通過 反範式化 犧牲一部分寫入性能,來換取更高的讀取性能,但前提是先要滿足範式設計,接著在此基礎上進行局部調整,故意打破一些規則。
與其先範式化,遭遇性能瓶頸再進行反範式化,不如從一開始就考慮反範式設計——直接採用 NoSQL。
一.什麼是 NoSQL?
不同於關係型數據庫,NoSQL 數據庫(也叫非 SQL 或非關係型數據庫)提供的數據存儲、檢索機制並不是基於表關係建模的:
A NoSQL (originally referring to "non SQL" or "non relational") database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
沒有了數據表,自然就沒有了多表連查(join 操作)的性能顧慮,範式約束和反範式化的抉擇也就不復存在了。
可是,沒有了數據表,數據該如何組織,關係要怎樣描述呢?
實際上,SQL(關係型數據庫)並不是唯一的選擇。
Not Only SQL
對於 NoSQL,另一種有趣的理解是 Not Only SQL,在關係型數據庫之外的廣闊世界裡,數據不一定非要打平存放到二維表格裡,關係也不是只能用主鍵、外鍵、關係表來描述。
就數據庫類型而言,NoSQL 指的是除關係型以外的其它類型的數據庫,即非關係型數據庫(NoREL, Non Relational),例如 MongoDB、CouchDB 等。
從使用角度來看,踐行 NoSQL 並不一定先要選個 NoSQL 數據庫,以「NoSQL」的方式來使用 MySQL 等關係型數據庫當然也算:
You can stay with MySQL, and use it like a NoSQL database.
比如在數據表中存一列 JSON 字符串,把這一列當作鍵值數據庫來用。
二.4 種 NoSQL 數據庫
不同於關係型數據庫中的表結構,NoSQL 數據庫支持一些更靈活的數據結構,使得某些操作更快。
鍵值存儲

鍵值存儲(Key-value store)是最簡單的 NoSQL 數據模型,只能存鍵值對兒,只能按 key 查詢,因為所存儲的值對數據庫系統不透明(類似於 BLOB),無法根據值的特徵查找或建立索引。
P.S.有些鍵值數據庫能夠對 key 進行排序,從而支持範圍查詢(檢索 key 在特定區間內的數據),比如找出工號大於 100000 的新人信息。
數據模型上是個哈希表,因此能夠達到 O(1) 的讀寫性能,適用於簡單、或者頻繁更改的數據,經常用作內存緩存,例如 Memcached、Redis。
文檔存儲
文檔存儲(Document store���以文檔(XML、JSON 等 半結構化數據)為中心建模,相當於增強版的鍵值存儲,面向文檔提供更精細的數據操作。與鍵值存儲最大的區別在於數據庫能夠理解並處理所存儲的值(即文檔),根據值的特徵(即文檔的內部結構)查詢和建立索引。
此外,文檔還支持嵌套,甚至 MongoDB、CouchDB 等文檔數據庫還提供了類 SQL 的查詢語言,以支持複雜查詢。
適用於持久化存儲,用來存放不經常更改的數據,作為關係型數據庫的一般替代方案。
寬列存儲
寬列存儲(Wide column store)中,列(column)是最小的數據單元,每一列是個名值對兒(以及用於版本控制和衝突解決的時間戳),在列之上還有一級超級列(super column):

僅含列的行稱為列族(column family),含有超級列的行稱為超級列族(super column family),每一行(即,一個列族或超級列族)代表一個實體,包含該實體的所有相關信息:

數據模型上是個二維 Map,特點是高性能以及良好的擴展性,因此適用於非常大的數據集,被 Twitter、Facebook 等社交網絡用來存儲海量用戶所產生的數據。
P.S.例如 Google 最早推出的 Bigtable、Hadoop 生態中的 HBase,以及 Facebook 推出的 Cassandra。
圖形數據庫
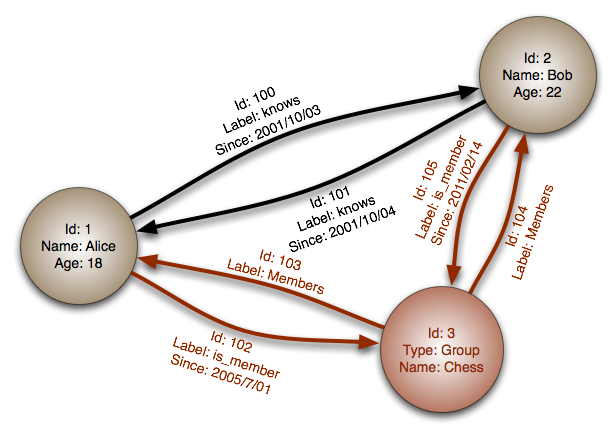
數據基於圖來建模,圖中每個節點代表一條記錄,每條邊表示節點之間的關係,因此能夠輕鬆描述數據對象之間的複雜關係,比如關係模型中複雜的外鍵和多對多關係。
圖形數據庫的實際應用還不十分成熟,甚至還沒有一種被廣泛採用的標準化查詢語言,但其連接性優勢尤其適用於具有複雜關係的數據模型(比如社交網絡),值得期待:

P.S.例如 Neo4j、Oracle Spatial and Graph、ArangoDB 等。
三.NoSQL 意味著什麼?
採用簡單的 NoSQL 模型(如鍵值存儲),相當於把一部分工作從數據庫層轉移到了應用層:
Joins will now need to be done in your application code.
與數據庫層相比,應用層通常更容易(橫向)擴展,因此這種工作量轉移有助於提升系統的可擴展性,將複雜的數據操作拋給應用層來處理,以求更大的優化空間。
甚至事務等強一致性保證也要由應用層來處理,因為多數 NoSQL 數據庫並不提供事務支持:
Most NoSQL stores lack true ACID transactions, although a few databases have made them central to their designs.
ACID vs. BASE
不同於關係型數據庫中追求的 ACID(事務的 4 大特性):
-
Atomicity(原子性):一系列操作要麼全部成功要麼失敗全部回滾
-
Consistency(一致性):事務執行前後數據庫都必須處於一致性狀態(滿足既定的所有一致性約束)
-
Isolation(隔離性):併發事務操作的結果狀態與按順序執行一樣
-
Durability(持久性):事務一旦提交,對數據的改變就是永久性的,遭遇故障也不會丟失已提交的結果
NoSQL 在 CAP 的抉擇 中對 C 做了妥協,允許最終一致性,即 BASE:
-
Basically Available(基本可用):讀寫操作盡可能保證可用,但不保證任何一致性
-
Soft state(軟狀態):由於沒有的一致性保證,在一段時間後,只是有可能讀到最新狀態,因為可能還沒收斂
-
Eventual consistency(最終一致性):如果系統運行正常,等待足夠長的時間後,最終能夠讀到最新狀態
也就是說,在分佈式環境下,(大多數)NoSQL 數據庫僅保證最終一致性,可能無法立即讀到最新的數據。
四.SQL or NoSQL?
相比之下,SQL 數據庫(關係型數據庫)的優勢在於:
-
支持事務操作
-
有明確的擴展模式
-
開發人員、社區、工具等相對成熟
主要缺陷是:
-
複雜的連表查詢導致數據讀取性能不佳
-
不太容易擴展(手動 分片)
-
關係模型與 OOP 之間存在較大差異(Object-relational impedance mismatch)
-
只支持存取結構化數據,關係模式(如表結構)必須預先定義,並且修改成本高
P.S.關於 Object-relational impedance mismatch 的更多信息,見 Why is MongoDB wildly popular? It's a data structure thing.
而 NoSQL 數據庫(非關係型數據庫)的優勢集中在:
-
不存在複雜的連表查詢
-
容易擴展(一些 NoSQL 數據庫支持自動分片)
-
與 OOP 數據模型一致,易於使用
-
不必預先定義數據模式,支持存取快速變化的結構化、半結構化和非結構化數據
-
讀寫性能(IOPS)很高,適合數據密集型工作
主要缺陷在於:
-
缺少強一致性保證
-
開發人員、社區、工具等沒那麼成熟
應用場景
因此,NoSQL 數據庫適用於:
-
快速變化數據,如點擊流(click stream)數據或日誌數據
-
排行榜或評分數據
-
臨時數據,如購物車數據
-
頻繁訪問的熱點數據
-
元數據(metadata),以及查找表(lookup tables)
暫無評論,快來發表你的看法吧