寫在前面
我們沒有辦法擁有一塊又大、又快、又便宜的儲存,所以出現了許多權衡之下的產物:
-
CPU 暫存器:非常快,但不便宜也不大
-
RAM:不太快也不太大,還算便宜
-
硬碟:非常便宜而且容量很大,但讀寫慢
並最終形成了這樣的階層結構:

類似的,系統設計中也面臨許多權衡取捨:
-
效能與可擴充性
-
延遲與吞吐量
-
可用性與一致性
一.效能與可擴充性
可擴充,意味著服務能以增加資源的方式成比例地提升效能:
A service is scalable if it results in increased performance in a manner proportional to resources added.
效能提升體現在能夠承擔更多的工作量,或者處理更大更重的任務(比如數據量增多)
P.S. 當然,增加資源也有可能是為了提升服務的可靠性,比如引入冗餘
但增加資源也會引入多樣性,一些節點可能比其他節點的處理能力更強大,另一些老舊節點可能弱一些,而系統又必須適應這種異質性 (heterogeneity),那麼依賴均勻性的演算法就會對新節點利用不足,繼而產生效能影響
二.延遲與吞吐量
延遲 (Latency) 是指從執行操作到產生結果所需要的時間:
Latency is the time required to perform some action or to produce some result.
其度量單位是時間,例如秒 (seconds)、奈秒 (nanoseconds),系統時鐘週期數 (clock periods) 等
吞吐量 (Throughput) 是指單位時間內所能處理的操作數,或能產生的結果數:
Throughput is the number of such actions executed or results produced per unit of time.
透過單位時間所生產的東西來計量,例如記憶體頻寬 (memory bandwidth) 用來衡量記憶體系統的吞吐量,而對於 Web 系統,有這些度量單位:
-
QPS (Queries Per Second):用來衡量資訊檢索系統(如搜尋引擎、資料庫等)在 1 秒內的搜尋流量
-
RPS (Requests Per Second):請求-回應系統(如 Web 伺服器)每秒所能處理的最大請求數量
-
TPS (Transactions Per Second):廣義上指在 1 秒內所能執行的原子操作數量,狹義上指 DBMS 在 1 秒所能執行的交易 (transaction) 數量
P.S. 通常也用 QPS 衡量 Web 服務的吞吐量,但更準確的單位是 RPS
同樣,由於無法兼具低延遲和高吞吐量,所以權衡之下的原則是:
Generally, you should strive for maximal throughput with acceptable latency.
在確保延遲尚可接受的前提下,轉而追求最大的吞吐量
三.可用性與一致性
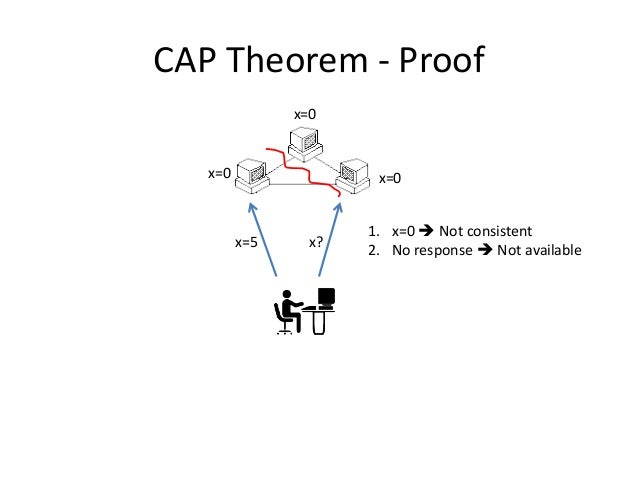
關於可用性與一致性,有個著名的 CAP 定理:
Of three properties of distributed data systems - consistency, availability, partition tolerance - choose two. —— Eric Brewer, CAP theorem, PODC 2000
在分散式電腦系統中,一致性、可用性和分區容錯性三者只能擇其二(而且分區容錯性必選):
-
一致性 (Consistency):每次讀取都能得到最新寫入的結果,抑或出錯
-
可用性 (Availability):每個請求都能收到正常回應,但不保證傳回的是最新資訊
-
分區容錯性 (Partition Tolerance):即便有一部分由於網路故障 down 掉了,系統仍能繼續執行
因為網路不完全可靠,所以必須保證分區容錯性 (P 必選)。當部分節點出現網路故障時,有 2 個選擇:
-
取消操作:能確保一致性,但會降低可用性(使用者可能收到逾時錯誤),即 CP (Consistency and Partition Tolerance),適用於需要原子讀寫的場景
-
繼續操作:保證可用性,但存在一致性風險(傳回的資訊可能是舊的),即 AP (Availability and Partition Tolerance),適用於可接受最終一致性 (Eventual consistency) 的場景
也就是說,在 P 必須滿足的前提下(網路故障是系統之外的不可控因素,沒得選),只能在 C 和 A 之間進行取捨,要麼保證一致性(犧牲可用性),要麼保證可用性(犧牲一致性),即:
Possibility of Partitions => Not (C and A)
(摘自 10. Why do some people get annoyed when I characterise my system as CA? )
P.S. 當然,在中心化系統(例如 RDBMS)中,不存在網路可靠性的問題,此時 C 和 A 能夠兩全
四.一致性模式
如果同一數據存在多份拷貝,那麼就需要考慮如何保證其一致性。而嚴格的一致性意味著要麼讀到最新數據,要麼出錯
但並非所有場景下都需要達到這樣的一致性要求,所以出現了弱一致性與最終一致性等妥協產物
弱一致性
寫完之後,不一定能讀到
弱一致性模式 (Weak consistency) 適用於網路電話、視訊聊天、即時多人遊戲等即時場景,而網路電話斷線重連後,不會再收到斷線期間的通話內容
最終一致性
寫完之後,非同步複製數據,保證最終能讀到
最終一致性模式 (Eventual consistency) 適用於 DNS、email 等高可用系統
強一致性
寫完之後,同步複製數據,立即就能讀到
強一致性模式 (Strong consistency) 適用於檔案系統、RDBMS 等需要交易機制的場景
五.可用性模式
可用性保障方面,主要有兩種方式:故障轉移與複製
故障轉移
一個節點 down 掉之後,迅速用另一個點代替它,以縮減當機時間。具體的,有兩種故障轉移模式:
-
主動-被動(主從故障轉移):只由主動伺服器處理流量,在工作的主動伺服器與待命的被動伺服器之間發送心跳包,如果心跳斷了,由被動伺服器接管主動伺服器的 IP 位址並恢復服務,當機時間的長短取決於被動機器是熱啟動還是冷啟動
-
主動-主動(主主故障轉移):兩台伺服器都處理流量,共同承擔負載
主動-被動模式下,(切換時)存在數據丟失的風險,而且無論哪種方式,故障轉移都會增加硬體資源和複雜度
複製
分為主從複製與主主複製,多用於資料庫,暫不展開
可用性指標
可用性通常用幾個 9 來衡量,表示服務可用時間佔執行時間的百分比
3 個 9 意味著可用性為 99.9%,即:
| 期限 | 當機時間不得超過 |
|---|---|
| 每年當機時間 | 8 小時 45 分鐘 57 秒 |
| 每月當機時間 | 43 分鐘 49.7 秒 |
| 每週當機時間 | 10 分鐘 4.8 秒 |
| 每天當機時間 | 1 分鐘 26.4 秒 |
4 個 9 就是 99.99% 可用:
| 期限 | 當機時間不得超過 |
|---|---|
| 每年當機時間 | 52 分鐘 35.7 秒 |
| 每月當機時間 | 4 分鐘 23 秒 |
| 每週當機時間 | 1 分鐘 5 秒 |
| 每天當機時間 | 8.6 秒 |
特殊的,對於由多部分組成的服務,其整體可用性取決於這些組成部分是串列的還是並行的:
// 串列
Availability (Total) = Availability (Foo) * Availability (Bar)
// 並行
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
可用性都達不到 100% 的兩個服務組合起來,如果是串列的,其整體可用性會下降(99.9% * 99.9% = 99.8%),而並行的話,整體可用性會提高(1 - 0.1% * 0.1% = 99.9999%)
暫無評論,快來發表你的看法吧