一。不可變的資料結構
資料結構不可變,所以對其進行增、刪、改等操作的結果只能是重新建立一份新的資料結構,例如:
reverse' xs
| length xs <= 1 = xs
| otherwise = last xs : (reverse' (init xs))
���轉 List 就像倒序一疊撲克牌,抽出最下面的一張放到新牌堆最上方,接著抽出倒數第二張放到它下面……所以,對牌堆進行倒序操作的結果實際上是造出了一個新牌堆。新牌堆仍由之前的牌構成,但與原牌堆沒有任何聯絡,類似於狀態丟棄,直接丟掉原牌堆,而不是維護修改,例如(實現陣列反轉的一般方法,用 JS 描述):
function swap(arr, from, to) {
let t = arr[from];
arr[from] = arr[to];
arr[to] = t;
}
function reverse(arr) {
for (let i = 0; i < arr.length / 2; i++) {
swap(arr, i, arr.length - 1 - i);
}
return arr;
}
如果資料結構可變,陣列反轉就可以通過 n/2 次元素交換來實現。二者的差異在於,可變的資料結構中,我們把資料結構當做可擴充套件複用的容器,對資料結構的操作就是對容器裡的值進行增、刪、改;不可變的資料結構中,我們把資料結構當做資料常量,無法擴充套件和複用,所以對資料結構的操作相當於重新建立一份很像但不太一樣的資料。例如 swap:
swap _ _ [] = []
swap i j xs
| i == j = xs
| i > j = swap j i xs
| otherwise = (take i xs) ++ [xs !! j] ++ (sublist (i + 1) (j - 1) xs) ++ [xs !! i] ++ (drop (j + 1) xs)
where sublist _ _ [] = []
sublist a b xs
| a > b = []
| a == b = [xs !! a]
| otherwise = (drop a . take (b + 1)) xs
一條線被 2 個點分成 3 段,List 中兩個元素交換的結果就是第一段並上第二個點,並上中間那段,再並上第一個點和最後一段
(摘自 一場函數式思維模式的洗禮)
對應的 JS 描述如下(僅關鍵部分):
function swap(i, j, xs) {
return xs.slice(0, i).concat([xs[j]]).concat(xs.slice(i + 1, j)).concat([xs[i]]).concat(xs.slice(j + 1));
}
相當麻煩,而且效率也不高,比如樹結構的場景,改一個節點就需要建一棵新樹,再改它旁邊的節點又需要建立一棵新樹……簡單地給所有節點值都 +1 就需要建立 n 棵完整樹。實際上,區域性的修改沒必要重新建立整棵樹,直到需要完整樹的時候再去建立更合理一些。在資料結構不可變的情況下,這能實現嗎?
二。在資料結構中穿梭
樹
先造一顆二叉搜尋樹:
> let tree = fromList [7, 3, 1, 2, 6, 9, 8, 5]
> tree
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
(fromList 及二叉搜尋樹的實現來自 [Monoid_Haskell 筆記 9](/articles/monoid-haskell 筆記 9/#articleHeader12))
樹結構如下:
5
2
1
3
8
6
空
7
9
想要修改指定節點的話,需要知道兩個東西:位置索引和新值。位置索引可以用訪問路徑來表示,例如:
data Direction = L | R
type Path = [Direction]
那麼 modify 函式的型別應該是這樣的:
modify :: Tree a -> Path -> Tree a -> Tree a
根據位置索引找到目標節點,換上新值即可,這樣實現:
modify EmptyTree _ n = n
modify t [] n = n
modify (Node x l r) (d:ds) n
| d == L = Node x (modify l ds n) r
| d == R = Node x l (modify r ds n)
試玩一下,把 3 改成 4,訪問路徑是 [L, R]:
> modify tree [L, R] (singleton 4)
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
符合預期,如果改完 3 還想改 1 呢?
可以把改完 3 之後的完整樹作為輸入,再從根節點開始找到 1 並改成 0:
> modify (modify tree [L, R] (singleton 4)) [L, L] (singleton 0)
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
能用,但存在 2 個問題:
-
改完
3之後生成的完整樹是多餘的 -
1就是3的左兄弟,不需要再從根開始找
實際上,我們希望的是:
-
不生成中間多餘的完整樹,在需要的時候(比如一系列修改操作之後)才生成完整樹
-
能夠方便地進行區域性修改(改左右兄弟、父級子級),而不用關注完整樹
要對一棵子樹進行多次修改,修改完畢後還要能生成完整樹,怎麼才能做到?
進行區域性修改的同時要保留其結構上下文資訊。比如修改右子樹時,關注點是:
8
6
空
7
9
就二叉樹而言,結構上下文資訊由兩部分組成,父節點和兄弟節點:
-- 父節點
5
-- 左兄弟
2
1
3
右子樹加上這兩部分資訊,就能夠得到以父節點為根的完整子樹。同樣,如果父節點也有其父節點和兄弟節點的資訊,就能接著向上恢復子樹,走到根的時候就能得到完整樹。實際上,只要擁有足夠的結構上下文資訊,就能在樹中上下左右任意穿梭,並且隨時能夠停下來重建完整樹
先定義結構上下文資訊:
data DirectionWithContext a = LeftSibling a (Tree a) | RightSibling a (Tree a) deriving (Show, Eq)
type PathWithContext a = [DirectionWithContext a]
type TreeWithContext a = (Tree a, PathWithContext a)
用 LeftSibling a (Tree a) 來記錄結構上下文資訊,其中 a 表示父節點的值,Tree a 表示右兄弟,這是向上恢復子樹所需的最小資訊,一點不多餘。PathWithContext 與之前的 Path 類似,同樣用來表示訪問路徑,只是路徑的每一步除了記錄方向,還記錄了相應的上下文資訊,包括父節點和兄弟節點
接著實現「任意穿梭」:
goLeft ((Node x l r), ps) = (l, ((LeftSibling x r) : ps))
goRight ((Node x l r), ps) = (r, ((RightSibling x l) : ps))
goUp (l, ((LeftSibling x r):ps)) = (Node x l r, ps)
goUp (r, ((RightSibling x l):ps)) = (Node x l r, ps)
走兩步試玩一下,還走之前的場景,先找 3,再找 1,即先向左向右,再上去,最後向左:
> let cTree = (tree, [])
> let focus = goLeft (goUp (goRight (goLeft cTree)))
> fst focus
Node 1 EmptyTree EmptyTree
> snd focus
[LeftSibling 2 (Node 3 EmptyTree EmptyTree),LeftSibling 5 (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))]
找到了 1 所在子樹,並且保留有完整的訪問路徑(5 的左兄弟 2 的左兄弟)
要重建完整樹的話,只需要原路走回到樹根,這樣做:
backToRoot (t, []) = (t, [])
backToRoot t = backToRoot $ goUp t
驗證一下:
> fst $ backToRoot focus
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
能夠自由穿梭,還能隨時重建完整樹之後,modify 就變得很簡單:
modifyTreeWithContext (EmptyTree, ps) _ = (EmptyTree, ps)
modifyTreeWithContext ((Node x l r), ps) v = ((Node v l r), ps)
再來一遍,先把 3 改成 4,再把 1 改成 0:
> let modified = modifyTreeWithContext (goLeft (goUp (modifyTreeWithContext (goRight (goLeft cTree)) 4))) 0
> fst modified
Node 0 EmptyTree EmptyTree
> fst $ backToRoot modified
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
與之前結��一致。看起來不太清楚,利用工具函式:
x +> f = f x
m = flip modifyTreeWithContext
簡單變換一下,以更自然的方式來描述:
> fst $ backToRoot $ cTree +> goLeft +> goRight +> m 4 +> goUp +> goLeft +> m 0
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
從樹根開始,向左走,向右走,改成 4,再向上走,向左走,改成 0,一系列操作相當自然,沒有感受到資料結構不可變的限制
List
實際上,List 也能以這種更自然的方式來操作,只要帶上結構上下文資訊即可
對於 List 來說,只有左右 2 個方向,比樹的場景簡單許多:
type ListWithContext a = ([a], [a])
左右穿梭、重建完整 List、修改元素都很容易實現:
goListRight (x:xs, ps) = (xs, x:ps)
goListLeft (xs, p:ps) = (p:xs, ps)
backToHead (xs, []) = (xs, [])
backToHead ls = backToHead $ goListLeft ls
modifyListWithContext ([], ps) _ = ([], ps)
modifyListWithContext (x:xs, ps) v = (v:xs, ps)
試玩一下:
> let list = [1, 3, 5, 7, 8, 10, 12]
> let cList = (list, [])
> m = flip modifyListWithContext
> let modified = cList +> goListRight +> goListRight +> goListRight +> m 4 +> goListLeft +> goListLeft +> m 2
> modified
([2,5,4,8,10,12],[1])
> fst $ backToHead modified
[1,2,5,4,8,10,12]
把第 4 個元素改成了 4,第 2 個元素改成了 2。對比之前的做法:
modifyList xs i x = take i xs ++ [x] ++ drop (i + 1) xs
> modifyList (modifyList list 1 2) 3 4
[1,2,5,4,8,10,12]
二者的差異在於,前者支援以符合直覺的方式遍歷、修改元素,對不可變的限制無感知
三.Zipper 是什麼東西
上面我們定義的 TreeWithContext、ListWithContext 都是 Zipper,正規描述如下:
The Zipper is an idiom that uses the idea of "context" to the means of manipulating locations in a data structure.
用「上下文」的思想來處理資料結構中的位置,習慣叫法是 Zipper(拉鍊)。為什麼叫「拉鍊」呢?
ListWithContext 就是拉鍊,非常形象。把 List 當作拉鍊,鎖頭是一個游標(cursor,或者理解成指標),游標所指的位置上的元素就是當前元素,其餘元素是其上下文。鎖頭向右拉開,向左拉住(想象拉檔案袋封口的動作),對應到資料結構操作中就是,向右訪問新元素,拉到最右端就是遍歷,向左訪問歷史元素,拉到最左端就是重建完整 List
類似的,TreeWithContext 也可以這樣理解,向左向右拉開,訪問新元素,向上拉住,訪問歷史元素,拉到頂部就是重建完整樹
具體地,Zipper 可以據其通用程度分為:
-
針對特定資料結構的 Zipper:如 ListZipper、TravelTree、TravelBTree
-
通用 Zipper:如 Zipper Monad、Generic Zipper
針對具體資料結構的 Zipper 我們已經實現過兩個了(把 xxxWithContext 換成 Zipper 即可),大致思路是:
Zipper, the functional cursor into a data structure, is itself a data structure, derived from the original one. The derived data type D' for the recursive data type D is D with exactly one hole. Filling-in the hole -- integrating over all positions of the hole -- gives the data type D back.
從給定的資料結構派生出 Zipper 結構,具體做法是把原資料結構拆成兩部分,子結構(作為值)和帶「洞」的結構(作為值的結構上下文,有「洞」是因為從原完整結構上摳掉了值所在的子結構),二者拼起來恰好就是原完整結構,如下圖:
[caption id="attachment_1762" align="alignnone" width="620"]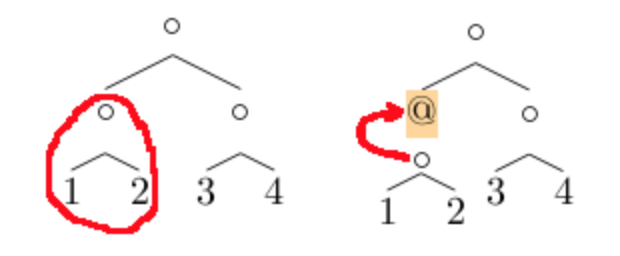 zipper-hole[/caption]
zipper-hole[/caption]
Zipper Monad
The Zipper Monad is a generic monad for navigating around arbitrary data structures. It supports movement, mutation and classification of nodes (is this node the top node or a child node?, etc).
除了支援移動,修改外,還能區分節點型別。基本實現如下:
import Control.Monad.State
data Loc c a = Loc { struct :: a,
cxt :: c }
deriving (Show, Eq)
newtype Travel loc a = Travel { unT :: State loc a }
deriving (Functor, Monad, MonadState loc, Eq)
結構 + 上下文 = 位置,通過幾個 monadic 函式來遍歷、修改:
traverse :: Loc c a -- starting location (initial state)
-> Travel (Loc c a) a -- locational computation to use
-> a -- resulting substructure
traverse start tt = evalState (unT tt) start
-- modify the substructure at the current node
modifyStruct :: (a -> a) -> Travel (Loc c a) a
modifyStruct f = modify editStruct >> liftM struct get where
editStruct (Loc s c) = Loc (f s) c
-- put a new substructure at the current node
putStruct :: a -> Travel (Loc c a) a
putStruct t = modifyStruct $ const t
-- get the current substructure
getStruct :: Travel (Loc c a) a
getStruct = modifyStruct id -- works because modifyTree returns the 'new' tree
P.S. 本來是給 Zipper 設計的通用 Monad,結果發現並不需要:
It's designed for use with The Zipper but in fact there is no requirement to use such an idiom.
目前好像被當做樹結構專用的了:
Zipper monad is a monad which implements the zipper for binary trees.
Generic Zipper
另一種通用 Zipper:
Generic Zipper: the context of a traversal
把 Zipper 看做遍歷操作的上下文,與之前的思路不同:
We advocate a different view, emphasizing not the result of navigating through a data structure to a desired item and extracting it, but the process of navigation.
不強調移動到資料結構中的某個位置,訪問想要的東西,而只關注移動的過程:
Each data structure comes with a method to enumerate its components, representing the data structure as a stream of the nodes visited during the enumeration. To let the user focus on a item and submit an update, the enumeration process should yield control to the user once it reached an item.
從遍歷的角度看,資料結構就是列舉過程中被訪問到的節點形成的流。那麼,要關注某個節點並更新的話,列舉過程應該在訪問到該節點時把控制權交回給使用者,例如:
Current element: 1
Enter Return, q or the replacement value:
Current element: 2
Enter Return, q or the replacement value:
Current element: 6
Enter Return, q or the replacement value:
42
Current element: 24
Enter Return, q or the replacement value:
q
Done:
fromList [(1,1),(2,2),(3,42),(4,24),(5,120),(6,720),(7,5040),(8,40320),(9,362880),(10,3628800)]
(具體見 ZipperTraversable)
P.S. 這個思路像極了 [JS 裡的生成器](/articles/javascript 生成器/#articleHeader8),每走一步都喘口氣看看要不要修改元素,或者停止遍歷:
As Chung-chieh Shan aptly put it, 'zipper is a suspended walk.'
暫無評論,快來發表你的看法吧