はじめに
前篇 SSR の利点と欠点 では SSR レンダリングモードの 6 大難題を挙げました:
- 難題 1:既存の CSR コードをどのように活用して同構を実現するか
- 難題 2:サービスの安定性と性能要件
- 難題 3:付帯設備の構築
- 難題 4:金銭の問題
- 難題 5:hydration の性能損失
- 難題 6:データリクエスト
これらの問題は SSR がこれまで CSR ほど広く応用されてこなかった主な理由ですが、今日に至り、Serverless、low-code、4G/5G ネットワーク環境という 3 大機会により SSR に新たな転機が訪れ、実装され花開く時機が到来しました
第一大機会:Serverless
サーバーレスコンピューティング(serverless computing)はサーバー関連の設定管理作業をすべてクラウドプロバイダーに委ね、ユーザーのクラウドリソース管理負担を軽減します
クラウドコンピューティングユーザーにとって、Serverless サービスは(自動的に)エラスティックスケーリングが可能で、明示的なリソースプロビジョニングが不要であり、クラウドリソースの管理負担を免除するだけでなく、使用状況に応じて課金されます。この特徴は「難題 4:金銭の問題」を很大程度上解決します:
SSR レンダリングサービスを導入することは、実際にはネットワーク構造に 1 つのノードを追加することで、大流量が通る場所では、すべての層が金銭です
コンポーネントレンダリングロジックをクライアントからサーバーに変更して実行することは、確実にコストを増加させますが、Serverless を通じてそのコストを最低限に抑えることが期待できます
もう一方では、Serverless Computing の鍵は FaaS(Function as a Service)で、クラウド関数が通常の計算能力を提供します:
バックエンドコードを直接実行でき、サーバーなどの計算リソースやサービスの拡張性、安定性などの問題を考慮する必要がなく、ログ、監視、アラームなどの付帯設備も开箱即用です
つまり、FaaS に JavaScript 関数を与えるだけで、高可用性のサービスをオンラインにできます。大流量(数万 QPS)をどのように担うか、サービスの安定性と信頼性をどのように保障するか……と心配する必要はありません。少し時代を超えているように聞こえますか?実際には、AWS Lambda、アリババクラウド FC、テンセントクラウド SCF はすでに成熟した商業製品であり、無料試用 も可能です
ステートレスなテンプレートレンダリング作業は特にクラウド関数(React/Vue コンポーネントを入力し、HTML を出力)で完了するのに適しており、「難題 2:サービスの安定性と性能要件」最も重要なバックエンドの専門性問題が解決され、SSR が直面する技術的難題は高可用性のコンポーネントレンダリングサービスから 1 つの JavaScript 関数に縮小されました:
クライアントプログラムと比較して、サーバー側プログラムは安定性と性能に対する要求がはるかに厳格です。例えば:
- 安定性:異常クラッシュ、無限ループ(フロントエンド担当者が自行解決)
- 性能:
メモリ/CPU リソース占有(FaaS インフラストラクチャが解決)、応答速度(ネットワーク伝送距離なども考慮する必要があります)
大流量/高並発にどのように対応するか、故障をどのように識別するか、どのようにダウングレード/快速回復するか(FaaS インフラストラクチャが解決)、どの環節にキャッシュを追加する必要があるか、キャッシュをどのように更新するか……
FaaS インフラストラクチャは大部分の性能問題と可用性問題を解決し、関数内の安定性問題は純粋なフロントエンド手段で解決できます。残りの応答速度、キャッシュ/キャッシュ更新問題については、もう 1 つのクラウドコンピューティング概念——エッジコンピューティングを導入する必要があります
エッジコンピューティング
いわゆるエッジコンピューティングとは、計算とデータストレージをユーザーにより近い(CDN)ノード(またはエッジサーバー、Edge server と呼ぶ)に分布させ、帯域幅を節約しながらユーザーリクエストに更快に响应することです:
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the location where it is needed, to improve response times and save bandwidth.
(Edge computing から引用)
従来の CDN が静的コンテンツと最終ユーザー間の物理的距離を短縮してリソースアクセスを加速し、同時にアプリケーションサーバーの負荷を軽減するのと同様に、エッジコンピューティングをサポートする CDN はクラウド関数をエッジノードにデプロイすることを許可し、サービス响应を加速し、同時に CDN に依拠してキャッシュ戦略を簡単に制御でき、さらに**動静分離のエッジフローレンダリング(ESR)**を実現できます:
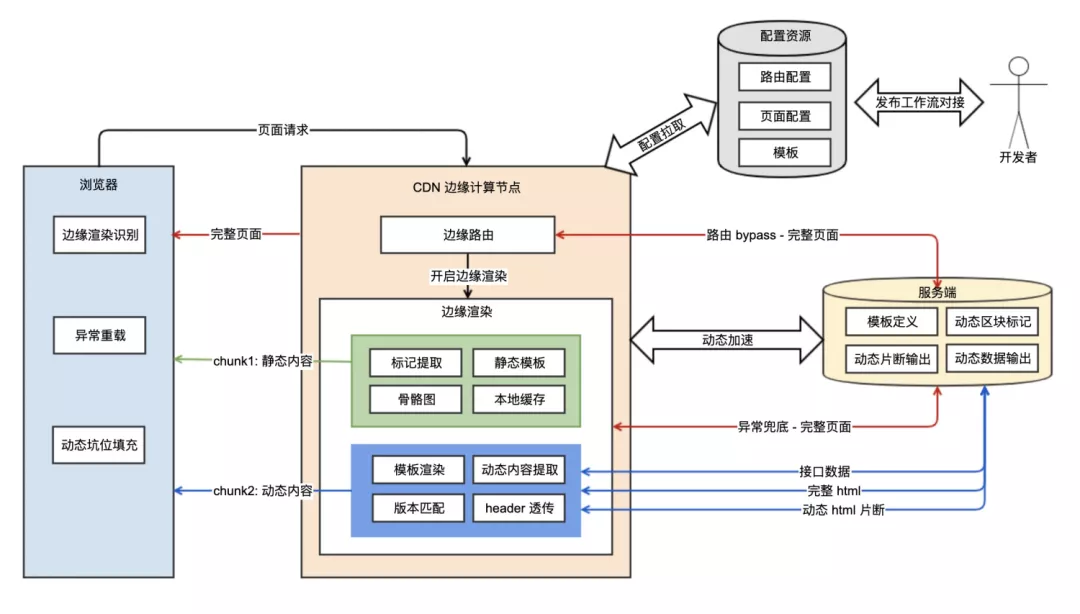
P.S. エッジコンピューティングに基づく SSR の詳細情報は、フロントエンド性能最適化:ページレンダリングがエッジコンピューティングに出会う を参照
第二大機会:low-code
FaaS が SSR 実装の最も核心的なサービス可用性問題を解決し、SSR に双翼を挿したとすれば、low-code は SSR が天際冲向くのを助ける滑走路です
なぜならlow-code は残りのすべての難題をほぼ解決したからです:
- 難題 1:既存の CSR コードをどのように活用して同構を実現するか
難題 2:サービスの安定性と性能要件- 難題 3:付帯設備の構築
難題 4:金銭の問題- 難題 5:hydration の性能損失
- 難題 6:データリクエスト
ソースコード開発モードでは解決が難しい問題が、low-code モードでは異なる次元の解法を持ち、まるで幾何学的方法で代数問題を解決するようなものです
難題 1:既存の CSR コードをどのように活用して同構を実現するか
既存の CSR コードをサーバー側で実行させるには、まず多くの問題を解決する必要があります。例えば:
- クライアント依存:API 依存とデータ依存の 2 種類に分かれ、
window/documentなどの JS API、デバイス関連データ情報(画面幅高さ、フォントサイズなど)
- ライフサイクルの差異:例えば React では、
componentDidMountはサーバー側で実行されません
- 非同期操作が実行されない:サーバー側コンポーネントレンダリングプロセスは同期であり、
setTimeout、Promiseなどは待てません
- 依存ライブラリの適応:React、Redux、Dva など、さらにサードパーティライブラリなどが universal 環境で実行できるかどうかが不確定で、環境を跨いで状態を共有する必要があるか。状態管理層を例にすると、SSR はその store がシリアライズ可能であることを要求します
- 両側で状態を共有:共有が必要なすべての状態について、(サーバー側で)どのように伝達するか、(クライアントで)どのように受信するかを考慮する必要があります
まず、low-code モードはソースコード開発とは異なり、既存の CSR コードを直接 low-code プラットフォームに移植することはできません。次に、low-code 設定化の開発モードは天然的な細粒度ロジック分割と完全な精細制御力を提供します。体现在:
-
細粒度ロジック分割:各ライフサイクル関数を独立して設定
-
完全な精細制御力:依存ライブラリ、ライフサイクル、非同期操作、共有状態は厳密に制御され、low-code プラットフォームが記入されたコードのコンパイル時、ランタイム環境を全権制御
クライアント依存は消除できませんが、関数型プログラミングにおける副作用 のように管控でき、例えば特定のライフサイクル関数(componentDidMount)に制約し、クライアントでのみ実行させ、サーバー側に影響を与えるのを回避できます。ライフサイクルの差異は low-code プラットフォームを通じてユーザーに強い感知を生じさせることができ、例えば編集、プレビューなどの環節で差異を強化します。サポートされない非同期操作については、編集段階で検証し提示できます。依存ライブラリと状態共有方式については、low-code プラットフォームが全権制御し、サポート範囲内に制約できます
总之、low-code はソースコード開発モードで厄介な書き方をどのように制約するか、不確実性をどのように管控するかという問題を簡単に解決します
難題 3:付帯設備の構築
SSR の最も核心的な部分はレンダリングサービスですが、それ以外にも考慮する必要があります:
- ローカル開発キット(検証 + 構築 + プレビュー/HMR + デバッグ)
- 公開フロー(バージョン管理)
一整套の工程施設は、SSR モードではすべて再考慮する必要があります
これらの付帯設備は SSR が解決すべき問題であり、low-code も同様の問題に直面しているため、SSR はある程度上 low-code が提供するオンライン研究開発リンクサポートを复用でき、その一部の環節のみを拡張し、付帯設備構築のコストを低減できます
難題 5:hydration の性能損失
コンポーネントは 1 つの抽象層として、モジュール化開発、コンポーネント复用などの工程価値を提供する一方で、いくつかの問題ももたらします。典型的には、インタラクションロジックとコンポーネントレンダリングメカニズムが绑定されており、これが SSR が hydration を必要とする根本的な原因です:
クライアントが SSR 响应を受け取った後、(JavaScript ベースの)インタラクション機能をサポートするために、依然としてコンポーネントツリーを作成し、SSR がレンダリングした HTML と関連付け、関連する DOM イベントを绑定して、ページをインタラクティブにする必要があります。このプロセスを hydration と呼びます
つまり、コンポーネントという抽象層に依存し続ける限り、hydration の性能損失は避けられません。ソースコード開発モードでは、コンポーネントは代替不可能です。それと同等の抽象記述形式がないからです。しかし、low-code モードでは、その出力産物(設定データ)も 1 つの抽象記述形式であり、コンポーネントと同等の表現力を持てば、コンポーネントという抽象層を完全に除去でき、hydration の性能損失を負う必要がなくなります
もう一方では、インタラクションなし(純粋な静的表示)、弱インタラクション(静的表示に埋め込み/ジャンプ付き)の偏静的シーンに対して、low-code プラットフォームも正確に識別でき、不要な hydration を回避できます
難題 6:データリクエスト
サーバー側同期レンダリングはまずリクエストを送信し、データを取得してからコンポーネントのレンダリングを開始する必要があるため、3 つの問題に直面します:
- データ依存をビジネスコンポーネントから剥离する必要がある
- クライアント公参(cookie などクライアントがデフォルトで付ける header 情報を含む)が欠如
- 両側のデータプロトコルが異なる:サーバー側にはより効率的な通信方式がある可能性があります。例えば RPC
low-code 開発モードでは、データ依存は設定化の形式で录入され、天然的に剥离され、クライアント公参、データプロトコルなどは low-code プラットフォームを通じて設定できます。例えば HTTP、RPC の 2 セットのプロトコルを設定し、環境に応じて自動選択します
第三大機会:4G/5G ネットワーク環境
モバイル時代早期、オフライン H5 が業界のベストプラクティスでした。オンラインページは秒単位のロード時間を意味し、オフラインページには巨大なロード速度の優位性があったからです
しかしネットワーク環境の発展に伴い、オフラインページのロード速度の優位性はすでに決定的要因ではなくなりました(ミニプログラムの大爆発がこれを十分に説明しています)。オンラインページの動的化特性が注目され、(SSR が无能为力な)オフラインシーンはますます少なくなり、SSR の出番はますます多くなりました
コメントはまだありません