はじめに
データベース層の拡張問題を解決するために、我们已经讨论了两种方案:
-
Replication:単一データベースから複数データベースへ拡張し、より多くのリクエスト量を処理
-
Partitioning:単一データベース(テーブル)を複数データベース(テーブル)に分割し、単一データベースのパフォーマンスボトルネックを打破
(複数マシン)複数データベース複数テーブルの支援により、急増するリクエスト量、データ量はもはや問題ではありません。しかし、データ量以外にも、単一データベースのパフォーマンスに極めて影響する要因があります——データの組織方法
例えば、リレーショナルデータベースでは、データエンティティは 2 次元テーブル(エンティティテーブルと呼ぶ)で記述されます:
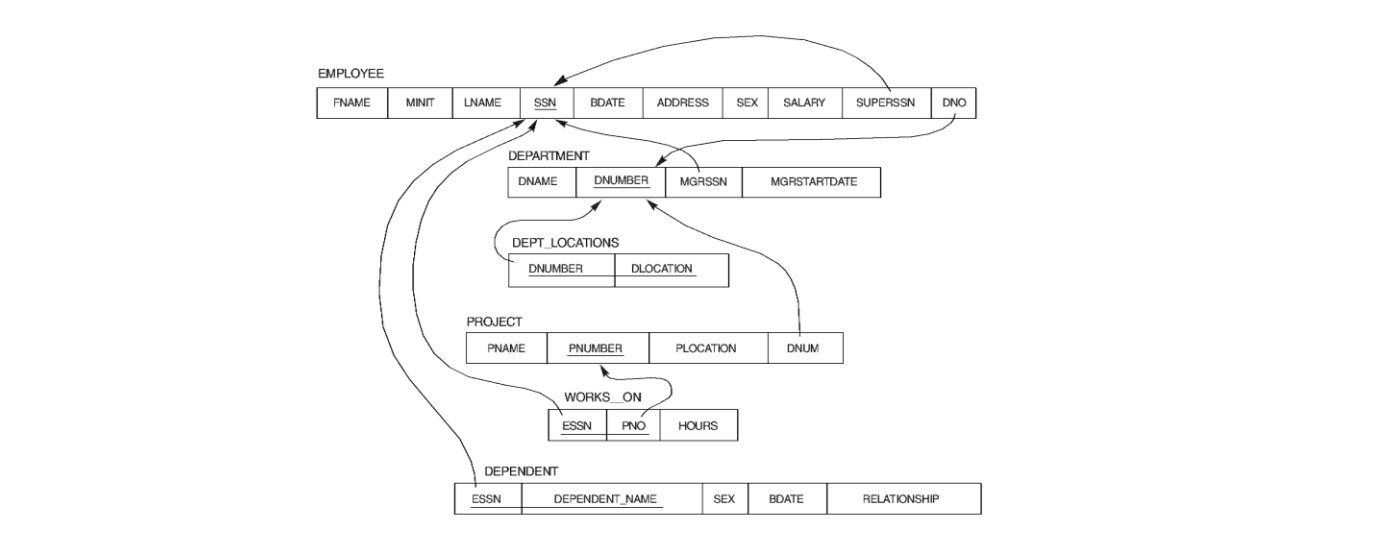
エンティティ間の複雑な関連関係(多対多)も 2 次元テーブル(リレーションシップテーブルと呼ぶ)で記述されます:
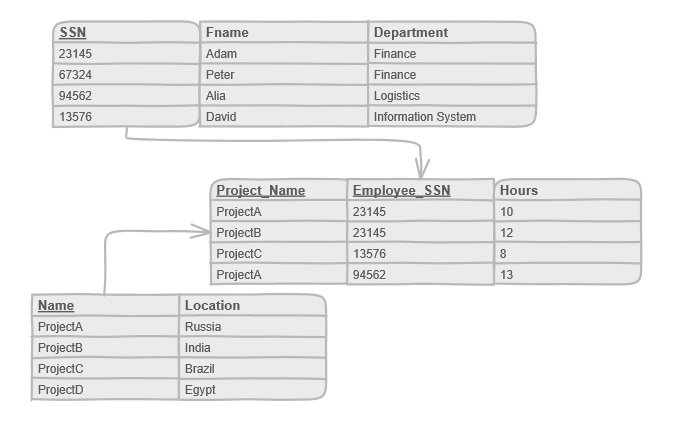
そのため、目標情報を得るために複数テーブルの結合查询が必要になることが多く、関係が複雑であればあるほど、読み取りパフォーマンスは悪くなり、最終的にはデータ量と同様に単一データベースのパフォーマンスボトルネックとなり、データベース層の拡張可能性を制約します
では、リレーショナルデータベースにおいて、データ読み取りパフォーマンスをさらに向上させる方法はありますか?
あります。(ある程度)データの組織方法を変更すること、すなわち非正規化(Denormalization)です
一.正規化
非正規化を討論する前に、まず正規化とは何か、何を非正規化するのかを明確にする必要があります
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
正規化(Database normalization)とは、一連の正規形(Normal forms)の要求に従ってデータモデルを組織するプロセスで、目的はデータ冗長性を削減し、データ整合性 を向上させることです
试想、もし同じ情報が複数行で繰り返し現れ、無関係な情報も同じテーブルにまとめられていれば、いくつかの異常状況が発生しやすくなります:
-
更新異常:単一行のみを更新すると、論理的不一致が発生
-
挿入異常:一部の情報のみ挿入できず、他の列を先に空欄にする必要がある
-
削除異常:一部の情報を削除する際、他の無関係な情報にも影響が及ぶ可能性
これらの異常状況を避けるために、人々はいくつかの制約規則を提案しました。すなわちデータベース設計正規形です
二.データベース設計正規形
-
1NF:第一正規形(First normal form) は、データテーブルの各フィールドの値がこれ以上分割できないことを要求
-
2NF:第二正規形(Second normal form) は、1NF を満たす基础上で、すべての非主属性が主キーに完全依存することを要求
-
3NF:第三正規形(Third normal form) は、2NF を満たす基础上で、すべての非主属性がどの主キーにも推移依存しないことを要求
P.S.此外、还有 BCNF、4NF、5NF など、詳細は Normal forms を参照
アプリケーション層に例えると、設計正規形はデータ層の設計パターンに相当し、データテーブルを結合解除し、単一テーブル情報をより凝集させ、彼此の境界を明確にし、依存関係をより明確にします
一般に 3NF を満たす関係モード(Relation schema)を正規化された(Normalized)と呼び、大多数の場合、上記の挿入、更新、削除異常を回避できます。しかし、これらの問題を解決する同時に、正規化は別の問題ももたらします
三.正規化の弊害
これらの設計正規形の制約下で、関連する情報は異なる論理テーブルに保存されます:
A normalized design will often "store" different but related pieces of information in separate logical tables (called relations).
例えば:
[caption id="attachment_2131" align="alignnone" width="625"]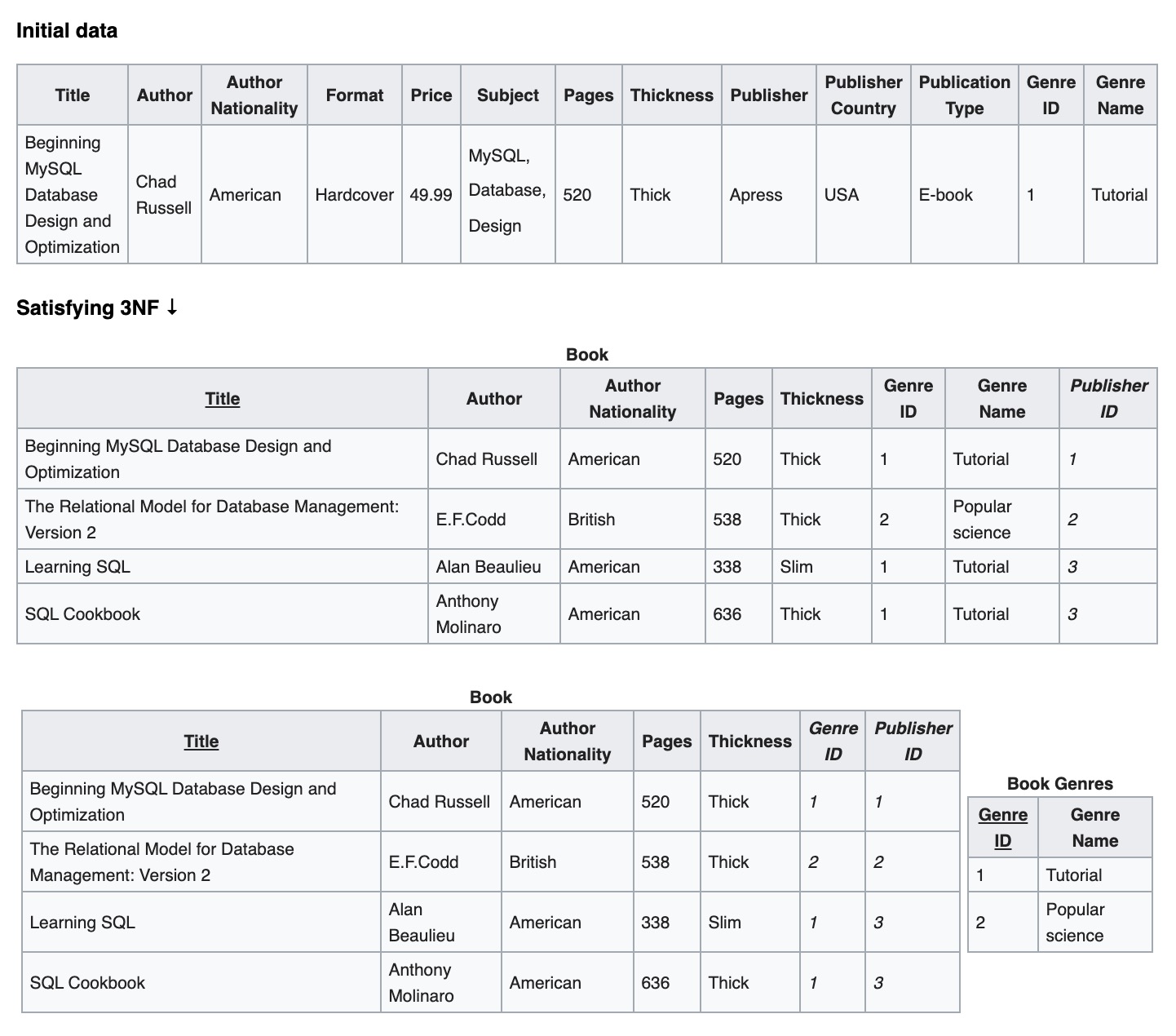 3NF[/caption]
3NF[/caption]
そのため、複数テーブルの結合查询(join 操作)が必要になることが多く、関係が複雑であればあるほど、テーブル結合查询は遅くなります:
If these relations are stored physically as separate disk files, completing a database query that draws information from several relations (a join operation) can be slow. If many relations are joined, it may be prohibitively slow.
では、查询パフォーマンスを改善する方法はありますか?
あります。冗長性を導入することです:
-
DBMS に追加の冗長情報を保存させることを許可。例えばインデックス付きビュー(indexed views)、マテリアライズドビュー(materialized views)。但仍遵从设计范式
-
冗長データを追加し、
join操作を削減し、設計正規形を打破(すなわち非正規化)
四.非正規化
所谓非正規化とは、設計正規形に従うデータベース(関係モード)に対するパフォーマンス最適化戦略です:
Denormalization is a strategy used on a previously-normalized database to increase performance.
P.S.注意、非正規化は非正規化形式(Unnormalized form)と等しくありません。非正規化は必ず正規化設計を満たす基础上で発生します。前者はすべての規則に従ってから局所調整を行い、意図的にいくつかの規則を打破するのに対し、後者は規則を完全に無視します
冗長データを追加するかデータをグループ化することで、一部の書き込みパフォーマンスを犠牲にして、より高い読み取りパフォーマンスを獲得します:
In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.
設計正規形の制約下では、データテーブルに冗長情報がなく(あるデータは某テーブルの某セルにのみ保存)、あるデータを取得するために一連の跨表查询が必要になる可能性があり、そのため読み取り操作のパフォーマンスは良くありませんが、書き込み操作は高速です。データ更新時には 1 か所のみ修正すればよいためです
非正規化はこの制約を打破し、あるデータを異なる場所に複数コピー保存する ことで、データ検索速度を高速化します:
The opposite of normalization, denormalization is the process of putting one fact in many places.
具体的操作
具体的には、一般的な做法は以下の通り:
-
派生データを保存:Redux Store に計算属性を追加するのと類似。頻繁に繰り返し計算する結果を保存。例えば一対多関係では、「多」の数を「一」の属性として保存
-
事前結合(pre-joined)で集計テーブルを生成:頻繁に
joinするテーブルを事前にjoinしておく -
ハードコード値を採用:依存テーブルの定数値(または頻繁に変化しない値)を直接現在のテーブルにハードコードし、
join操作を回避 -
詳細情報を主テーブルに統合:データ量の大きくない詳細テーブルの場合、全部/部分の詳細情報を主テーブルに追加し、
join操作を回避
P.S.非正規化の具体的做法に関するより多くの情報は、When and How You Should Denormalize a Relational Database を参照
五.非正規化の代償
しかし、必要でない限り、一般に非正規化は推奨されません。その代償は高額です:
-
データ整合性保証を失う:正規形を打破することは、之前通过正規化解决的更新、挿入、削除異常問題が再び現れることを意味します。つまり、冗長データの一貫性は DBA 自身が保証する必要があり、インデックス付きビューなど DBMS が保証するのとは異なります
-
書き込み速度を犠牲:非正規化は冗長データを導入するため、更新時には複数箇所を修正する必要があります。しかし、大多数のシナリオは読み取り集中型であり、書き込みが少し遅いのは問題ありません
-
保存スペースを浪費:不要な冗長データを保存するため、 naturalmente 一部の保存スペースを浪費します。しかし、スペースで時間を換えるのは一般に許容可能です(メモリ、ハードディスクなどのリソースはすでに比較的安価になっているため)
P.S.一般に制約規則(constraints)を通じて冗長データの一貫性を保証しますが、これらの規則は一部の作用を相殺します
コメントはまだありません