前言
理論上、信頼できる負荷分散メカニズムがあれば、1 台のサーバーを簡単に n 台に拡張できます。しかし、これら n 台のマシンが依然として同一データベースを使用する場合、すぐにデータベースがシステムのパフォーマンスボトルネックと信頼性ボトルネックになります
では、どのようにデータベースの処理能力を向上させるのでしょうか?
リソースの観点から見ると、2 つの考え方しかありません:
-
垂直拡張:単一マシンの構成を向上させる(ハードディスク、メモリ、CPU など)。しかし、同様に単一マシンのパフォーマンスボトルネックに遭遇します
-
水平拡張:マシンを追加し、数を単一データベースインスタンスから複数インスタンスに拡張する
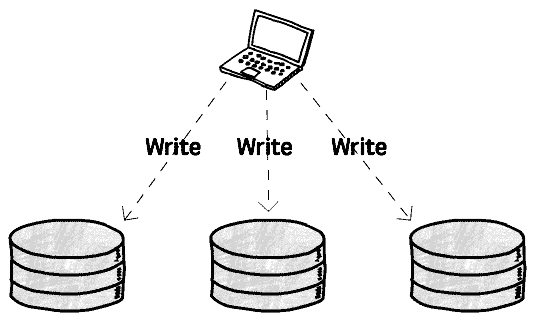
このように見ると、いくつかのデータベースを追加し、アプリケーション層からのトラフィックを共同で分担すれば、単一データベースから複数データベースへの拡張が完了するように思えます:
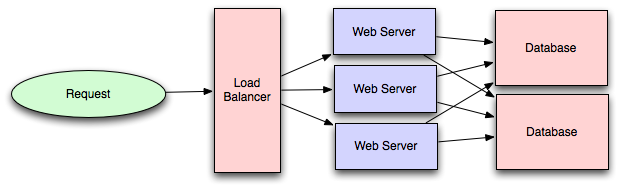
本当にこんなに簡単なのでしょうか?
一.一貫性问题
同じデータが複数のコピー存在する場合、その一貫性をどのように保証するかを考える必要があります
(一貫性パターン より引用)
データベースとアプリケーションサービスの最大の違いは、アプリケーションサービスはステートレスであることができる(または共有状態を外部に抽出できる。例えばデータベースに配置)のに対し、データベース操作は必ずステートフルであることです。データベースを拡張する際、データの一貫性を考慮する必要があります
具体的には、一貫性は 3 種類に分類され、厳格さは順次減少します:
-
強一貫性(Strong consistency):書き込み後、即座に読み取れる
-
最終一貫性(Eventual consistency):書き込み後、最終的に読み取れることが保証される
-
弱一貫性(Weak consistency):書き込み後、読み取れるとは限らない
二.Replication
したがって、単一データベースから複数データベースに拡張するには、少なくとも 1 つのデータ更新同期メカニズムが必要です。これを*Replication(複製)*と呼びます:
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
(Replication (computing) より引用)
つまり、_複製(書き込み操作)を通じて複数データコピーの情報一貫性を保証する_ことです。例えば、データベースインスタンス A にデータを書き込む際、同じデータをインスタンス B、C、D などにも書き込む必要があります
三.複製方式
非同期複製
具体的には、書き込み完了後、他のインスタンスにデー��更新を通知できます。これを非同期複製(Asynchronous replication)と呼びます:
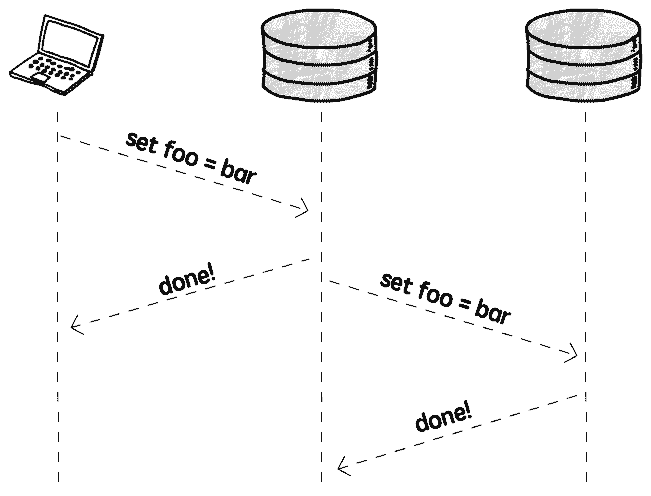
このモードでは、クライアントは複製操作の完了を待つ必要がなく、追加のパフォーマンス影響はありません。しかし、問題があります:
-
データ丢失リスクがある
-
複製遅延(Replication lag)が存在するため、強一貫性を保証できない
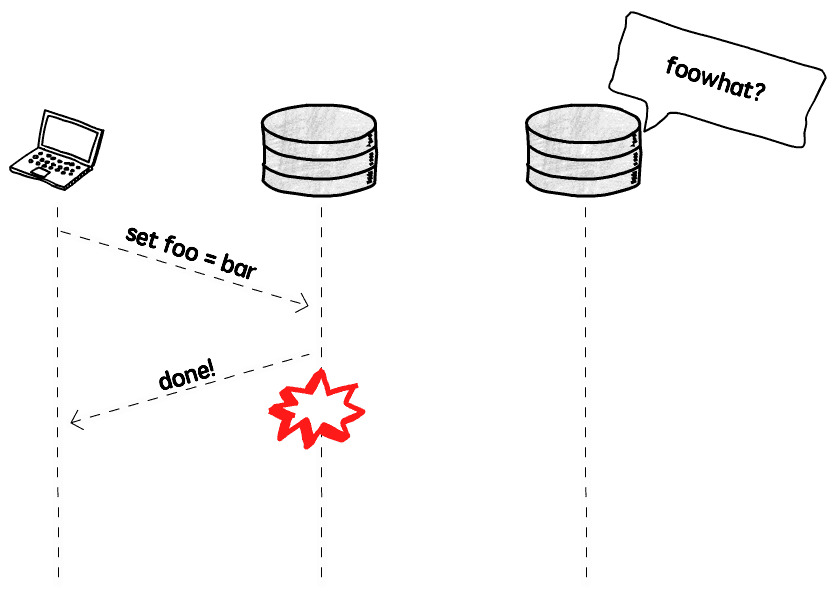
インスタンス A が書き込み完了後、他のインスタンスに通知する前にダウンした場合、データ丢失が発生します:
一方、複製操作は非同期で完了するため、データ更新は実際には遅れています:
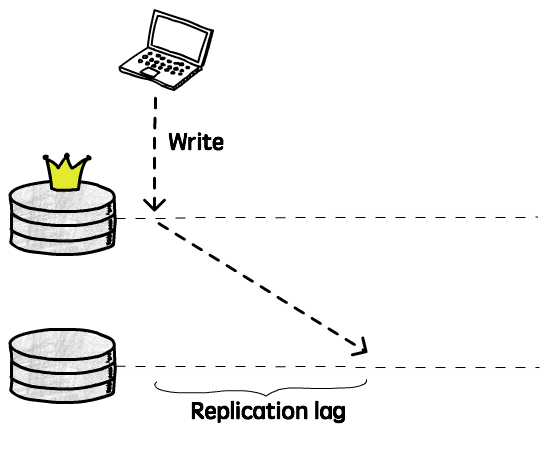
現在のインスタンスで前の書き込み操作が完了してから、その操作が他のインスタンスに適用されるまでの時間差を複製遅延(Replication lag)と呼びます。この期間中、クライアントが他のインスタンスから読み取るのは依然として旧データであり、明らかに強一貫性の要求を満たしません(最終一貫性のみ保証可能)
同期複製
厳格な一貫性要求を達成するには、同期複製(Synchronous replication)を検討する必要があります:
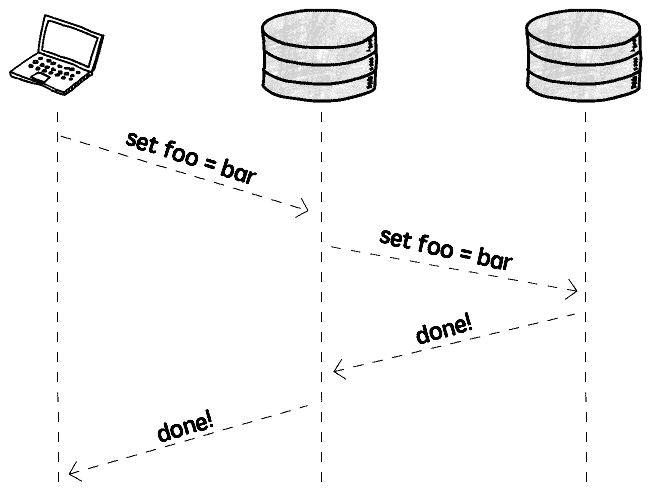
書き込み操作発生時、直ちに操作を他のすべてのインスタンスに同期し、複製完了後に初めて書き込み完了とみなし、厳格な一貫性を確保します
しかし同期複製はパフォーマンスと可用性に影響し、代償は非常に高いです:
-
パフォーマンス影響:複製プロセス全体の完了を待つ必要がある
-
可用性影響:1 つのインスタンスでも故障(ネットワークなどの理由)すると、書き込み操作全体が失敗する
さらに、データベースインスタンス数が多ければ多いほど、これら 2 つの面の影響は大きくなります
準同期複製
特殊的には、2 つの方式を組み合わせて使用できます。これを準同期複製(Semi-synchronous replication)と呼びます:
Some databases and replication tools allow us to define a number of followers to replicate synchronously, and the others just use the asynchronous approach. This is sometimes called semi-synchronous replication.
つまり、一部のデータベースインスタンスに同期複製を要求し、残りは非同期複製を使用します
P.S.PostgreSQL はこのモードをサポートしています
四.トポロジ構造
トポロジ構造上、複製は 3 種類に分類できます:
-
単主構造(Single leader replication)
-
多主構造(Multi leader replication)
-
無主構造(Leaderless replication)
単主構造
最も一般的な 1 主多従構造です:
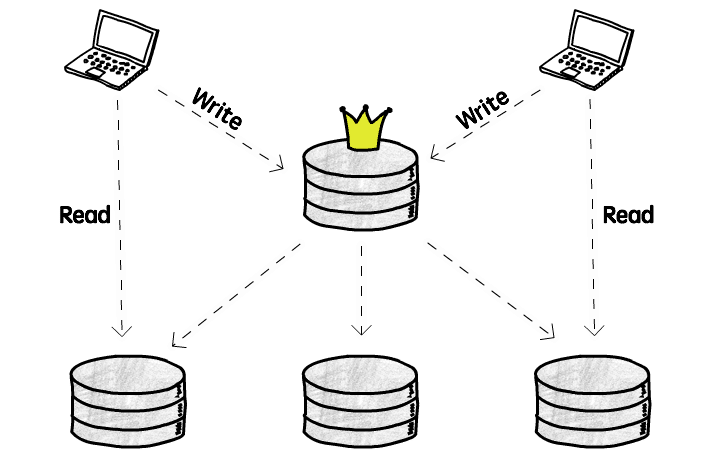
この構造では、書き込み操作(追加/削除/変更)は主庫でのみ発生し、主庫が書き込み操作を他のすべての従庫に複製します。従庫は読み取り操作(照会)のみをサポートします
すべてのクライアントが同じ庫に書き込むため、書き込み操作衝突の大きな問題をうまく回避できます。しかし、注意が必要です:
-
書き込み操作の圧力を担うのは依然として単一庫:書き込み集中(write-intensive)のアプリケーションには適さない。しかし、幸いなことに大多数のアプリケーションは読み取り集中です
-
主庫へのアクセス遅延問題:主庫は 1 つしかなく、特定の地理位置に配置するしかないため、一部の領域で書き込み操作(主庫へのアクセス)を発行すると、高い遅延を負担する必要がある
さらに悪い状況として、主庫がダウンした場合、直ちに従庫の中から後継者を選出し、主庫の职责を担い、このメカニズムの正常な稼働を保証する必要があります
しかし、この故障転送戦略はそれほど簡単に実装できません。難点は以下の通り:
-
主庫が本当にダウンしたことをどのように確定するか?
-
新任主庫をどのように選択するか?
-
書き込み操作を新任主庫にどのように転送するか?
実際、高遅延と使用不可を区別することはできず、通常はタイムアウトすれば使用不可とみなします(本当にダウンしたかどうかに関わらず)。その後、故障転送预案を起動し、新任主庫の選択を開始します
1 つ選出するのは難しくありません。鍵は、選択された新任主庫が他のすべての従庫にその地位を認められる必要があることです(つまり 合意問題)。例えば、事前に接班順序を決定しておきます
新任主庫が選出された後、すべての書き込み操作を転送する必要があります。例えば、ルーティング制御を許可するために、配布メカニズムを 1 層追加します
さらに、非同期複製を採用している場合、旧主庫が回復した後、他の従庫に複製されていないデータと、オフライン期間中に新任主庫が書き込んだデータが衝突する可能性があります。この場合、通常は LWW(last-write-win)戦略を採用し、旧データを直接破棄しますが、同様にリスクが存在します
特殊的には、興味深い状況として旧主庫が回復して自分がまだ主庫だと考える 場合、分裂(Split-brain)が発生します:
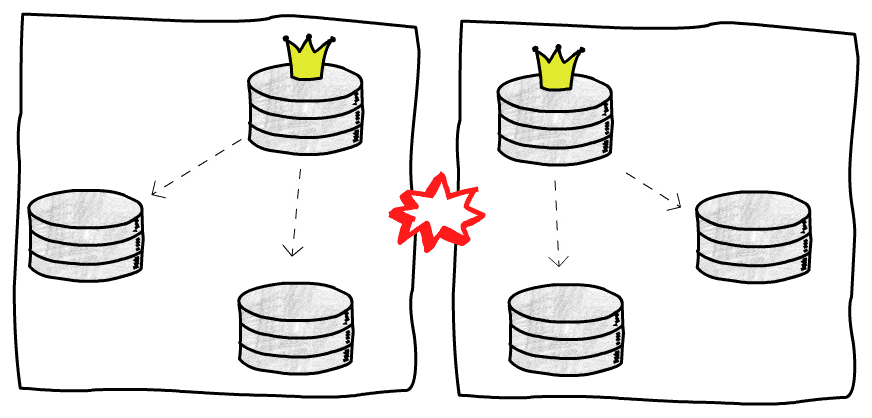
P.S.ネットワーク障害もこのような状況を引き起こす可能性があります。例えば 2 つのクラスター間でネットワーク障害が発生し、互いにアクセスできなくなり、どちらも相手チームがダウンしたと考え、それぞれで大選を開始します
簡単な処理方法は STONITH(Shoot The Other Node In The Head)で、複数の主庫が存在することを発見すると、直接 1 つを停止します
多主構造
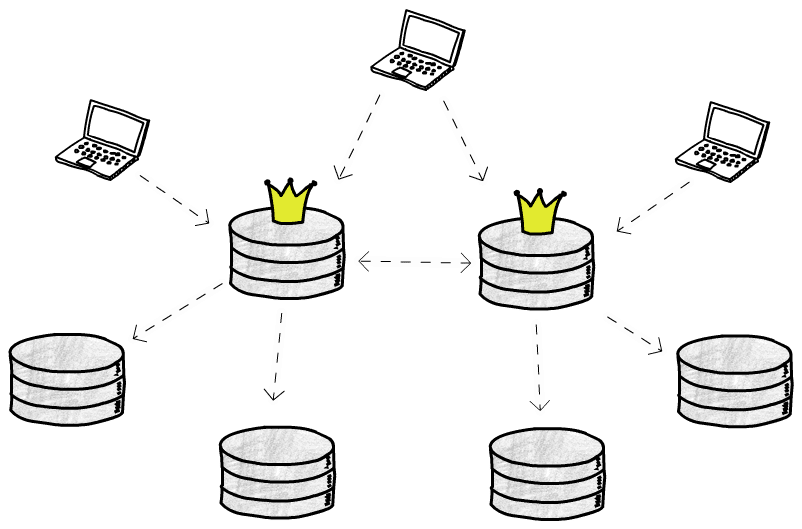
これで書き込み可能な主庫が複数あり、書き込み操作を分担でき、多地に配備することもできます。単主構造の 2 つの問題は簡単に解決します。しかし、大きな問題が発生しました
書き込み操作が同時に(非同期複製の)複数の庫で発生する可能性があるため、書き込み衝突をどのように解決するかを考える必要があります。一般的に 3 つの考え方があります:
-
衝突回避:例えばコンテンツ特徴で庫を分けて存储し、互いに干渉しない。例えば国内国外の 2 つの主庫に対して、すべての国内データへの書き込み操作が国内主庫に落ち、すべての国外データへの書き込み操作が国外主庫に落ちることを保証できれば、衝突は存在しません
-
LWW(last-write-win)戦略:各書き込み操作にタイムスタンプを付け、最新バージョンのみを保持
-
ユーザーに解決を委ねる:衝突を記録し、アプリケーションがユーザーに提示し、ユーザーがどちらを保持するか決定
P.S.��部のデータベース(CouchDB など)は、すべての衝突値を書き込み、読み取り時に一連の値を返すことをサポートしています
さらに、多主構造下のもう 1 つの難題は DDL(Data Definition Language)の複製です。つまり Schema への書き込み操作。詳細は DDL replication を参照
無主構造
もちろん、主庫を区別しない構造もあり、すべての庫が読み取り書き込み可能です
「全主構造」のように見えるため、予測可能なこととして、書き込み衝突は非常に一般的になります。したがって、戦略を調整して「全主構造」になるのを回避する必要があります:
-
書き込み:クライアントは同時に複数のデータベースに書き込み、いくつか成功すれば書き込み完了とみなす
-
読み取り:クライアントは同時に複数のデータベースから読み取り、各庫がデータとそのバージョン番号を返し、クライアントがバージョン番号に基づいてどのデータを採用するか決定
主庫がないということは、故障転送を考慮する必要がない ことを意味し、単庫故障は全体に影響せず、新任主庫を選択する様々な面倒な問題は存在しなくなります
同時に、主庫がないということはデータ同期メカニズムがなくなり、読み取った旧値を自動的に修正できない ことを意味します:
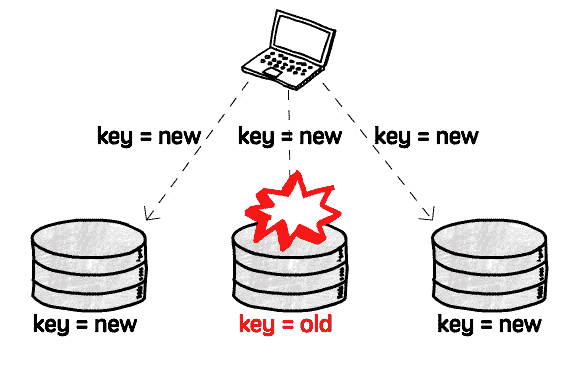
したがって、追加のエラー修正メカニズムが必要です。クライアントが旧値を読み取った際に新値を書き戻します(Read repair と呼ばれます)。または、独立したプロセスが专门负责旧値を見つけ出し修正します
もう 1 つの鍵となる要素は、読み取り/書き込み操作の目標庫の数量です。少なくともいくつかの庫への書き込み成功后、少なくともいくつかの庫から成功裡に読み取れば、新値を読み取れることが保証できるでしょうか?
w 個の庫への書き込みが成功し、続いて r 個の庫のデータを成功裡に読み取った場合、w + r > 庫の総数 を満たす必要があります
五.具体的実装
具体的には、いくつかのデータを 1 つの庫から別の庫にコピーするには 3 つの方式があります:
-
ステートメントベースの複製:書き込み操作ステートメントをそのまま他の庫に送信して実行
-
ログ転送式複製:物理複製とも呼ばれ、データベースログを他の庫に転送し、ログから完全に一貫したデータを回復。例えば PostgreSQL が提供する Streaming Replication
-
行ベースの複製:論理複製とも呼ばれ、複製専用のログを転送し、行ごとに複製。例えば MySQL が提供する Mixed Binary Logging Format
ステートメントごとに複製する問題点は、すべてのステートメントの実行結果が確定であるとは限らない ことです。例えば CURRENT_TIME()、RANDOM() です。一部のデータベースは複製時にこれらの値を置換しますが、それでもトリガーおよびユーザー定義関数が確定の実行結果を持つことを保証できません。一方、トランザクション操作がすべてのデータベース上でアトム性を確保する必要があります。すべて完了するか、すべて全く実行されないかのどちらかです
ログ転送式複製はデータの完全な一貫性を保証できますが、(ストレージエンジン向けの)ログは通常、データベースバージョンを跨いで使用できません。異なるバージョンのデータベースでは、データの物理存储方式が変化する可能性があるためです。さらに、ログ転送は多主構造には適しません。複数のログを 1 つにマージできないためです
行ベースの複製は前 2 つの方式の組み合わせで、複製専用のログを採用し、ストレージエンジンとの結合がなくなり、したがってデータベースバージョンを跨いで使用できます。ステートメントごとの複製と比較して、行ごとの複製はより多くの情報を記録する必要があります(例えば、1 つのステートメントが 100 行に影響した場合、行ごとにすべて記録する必要があります)
コメントはまだありません