はじめに
JavaScript の文字列処理は難しそうに見えないが、emoji に出会うまで:
[caption id="attachment_1801" align="alignnone" width="626"]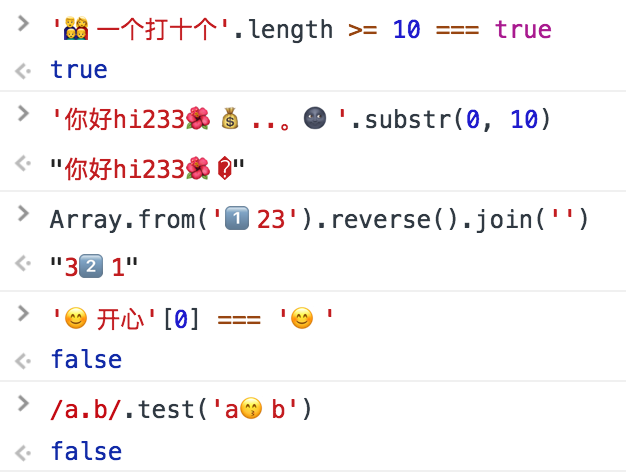 javascript-emoji-issues[/caption]
javascript-emoji-issues[/caption]
??何が起こったのか?一体どうなっているのか?
Unicode 符号化から説明する必要があります……
一.Unicode 符号化
The Unicode codepoint range goes from U+0000 to U+10FFFF which is over 1 million symbols, and these are divided into groups called planes. Each plane is about 65000 characters (16^4). The first plane is the Basic Multilingual Plane (U+0000 through U+FFFF) and contains all the common symbols we use everyday and then some. The rest of the planes require more than 4 hexadecimal digits and are called supplementary planes or astral planes.
つまり、Unicode がサポートする符号化範囲は U+0000 から U+10FFFF で、100 万を超える記号に対応できます(0x10FFFF === 1114111)。これらの記号は 16 個の*平面(panel)*にグループ化されており、各平面に 65536(16^4 === 65536)個配置されます
その中で、常用記号はすべて最初の平面(U+0000 から U+FFFF)に配置されているため、*基本多言語平面(Basic Multilingual Plane、略して BMP)と呼ばれます。残りの平面中のコードポイント値(codepoint、つまり記号に対応する Unicode 符号化値)*はすべて 4 桁(16 進数)より大きく、*補助平面(supplementary plane)*と呼ばれます
P.S. 補助平面にはとてもすごそうな名前もあり、astral plane(星界?星界位面?)と呼ばれます
I have no idea if there's a good reason for the name "astral plane." Sometimes, I think people come up with these names just to add excitement to their lives.
さらに、基本多言語平面内の 65536 個の位置の入居率は 100% ではなく、いくつかの位置を专门空けて 不時の需要に備えています。例えば、新しい特殊な意味の記号を追加したり、拡張したりするためです
例えば UTF-16 中の*サロゲートペア(surrogate pairs)*の概念で、2 つの 4 桁(16 進数)の小さなコードポイント値で 1 つの大きなコードポイント値(4 桁より大きい)を表します。基本多言語平面から補助平面へのマッピングの一種です。これが可能なのは、以下の理由です:
基本多言語平面内、U+D800 から U+DFFF までのコードポイント区間は Unicode 文字にマッピングされないよう永久に保留されています。UTF-16 はこの保留された 0xD800-0xDFFF 区間のコードポイントを利用して補助平面の文字のコードポイントを符号化します。
二.JavaScript 中の Unicode
JS 中の Unicode 文字には 3 種類の表現方法があります:
'A' === '\u0041' === '\x41' === '\u{41}'
その中で \x は U+0000 から U+00FF までにのみ使用され、\u は任意の Unicode 文字(U+0000 から U+10FFFF)に適用できますが、4 桁より大きい(U+FFFF より大きい)場合、花括弧({})で 16 進数シーケンスを囲む必要があります:
The \x can be used for most (but not all) of the Basic Multilingual Plane, specifically U+0000 to U+00FF. The \u can be used for any Unicode characters. The curly braces are required if there are more than 4 hexadecimal digits and optional otherwise.
注意、\u{} エスケープ構文は ES 2015 で定義されており、UnicodeEscapeSequence と呼ばれます。以前は 2 つの小さな Unicode で 1 つの大きな Unicode を表していました。例えば:
'' === '\u{1F4A9}'
'' === '\uD83D\uDCA9'
\uD83D\uDCA9 がサロゲートペアで、<H,L> の形をしており、二者の変換��係は以下の通り:
let C, L, H;
C = 0x1F4A9;
// 公式:大 Unicode 转代理对儿
H = Math.floor((C - 0x10000) / 0x400) + 0xD800;
L = (C - 0x10000) % 0x400 + 0xDC00;
[H, L].map(v => '\\u' + v.toString(16).toUpperCase()).join('')
"\uD83D\uDCA9"
さらに、JS では 16 ビット符号なし整数値を 1 文字とみなすため、1 つの emoji は複数の文字とみなされる可能性があります:
The phrase code unit and the word character will be used to refer to a 16-bit unsigned value used to represent a single 16-bit unit of text.
Unicode character only refers to entities represented by single Unicode scalar values: the components of a combining character sequence are still individual "Unicode characters", even though a user might think of the whole sequence as a single character.
P.S. JavaScript の Unicode サポートおよび ES 規範の関連内容については、JavaScript's internal character encoding: UCS-2 or UTF-16? を参照
正規表現中の Unicode
大きな Unicode(U+FFFF より大きい)が JS 中で 2 つの小さな Unicode(サロゲートペア)で表されるなら、当然このような正規表現を書きたくなります:
> /[\uD83D\uDCA9-\uD83D\uDE0A]/.test('')
Uncaught SyntaxError: Invalid regular expression: /[\uD83D\uDCA9-\uD83D\uDE0A]/: Range out of order in character class
このような range を識別できないというエラーが出ますが、どのように正規表現で大きな Unicode 文字範囲を記述するのでしょうか?
JS は u flag を提供してこの問題を解決します:
u Unicode; treat pattern as a sequence of Unicode code points
/[\uD83D\uDCA9-\uD83D\uDE0A]/u.test('')
/[-]/u.test('')
同様に、.(ドットは任意の文字にマッチ)がサロゲートペア形式の大きな Unicode にマッチしたい場合も、u flag を有効にする必要があります:
> /foo.bar/.test('foobar')
false
> /foo.bar/u.test('foobar')
true
P.S././u はサロゲートペア形式の emoji のみにマッチでき、他の形式はできません。例えば:
> /foo.bar/u.test('foo2??bar')
false
P.S. より多くの関連例については、Astral ranges in character classes を参照
fromCodePoint と fromCharCode
String.fromCodePoint と String.fromCharCode の違いは、前者がより大きな範囲の 16 進数 Unicode 符号化をサポートすることです。例えば:
> String.fromCodePoint(0x1F4A9)
""
> String.fromCharCode(0x1F4A9)
"?"
しかし fromCodePoint は ES 2015 規範で定義されており、互換性は fromCharCode より良くありません。0x0000-0xFFFF 範囲の 65536 個の Unicode 文字については、fromCharCode の使用を推奨します
三.emoji 符号化
Unicode に似て、emoji も一種の符号化規則で、対応する規範があり、多くのバージョンが存在します:
Emoji 12.0
Emoji 11.0
Emoji 5.0
Emoji 4.0
Emoji 3.0
Emoji 2.0
Emoji 1.0
その中で 12.0 は 2019 年にリリース予定で、最新の 11.0 は 2018-02-07 にリリースされました
HTML、CSS 規範と同様に、新版規範で追加された emoji がすべて実装されているわけではなく、HTML、CSS よりも深刻な互換性問題に直面しています:
-
規範バージョン:emoji 規範のリリースが頻繁で、複数バージョンが共存
-
プラットフォーム差異:Web ブラウザ環境以外に、emoji はプラットフォームのネイティブサポート(各種画面表示デバイス)に依存
-
Unicode への依存:emoji は Unicode を基礎として建立されており、Unicode 規範に依存
例えば、SMS から Web ページ入力ボックスにコピーペーストすると、emoji が表示されないか文字化けすることがあります。native と Web ブラウザがサポートする emoji 規範バージョンまたは実装程度に差異があるためです。さらに、Unicode 新規範は既に定義された emoji 規範と衝突する可能性があり、この場合当然 emoji 規範が譲歩する必要があります:
Unicode 12.0 is the new version of the Unicode Standard planned for release in March 2019. See Emoji 12.0 for a more complete list of potential emojis for 2019.
Note: All emojis listed throughout 2018 are candidates only, and subject to change before a final release.
emoji が直面する環境はどれほど厳しいでしょうか?図の通り:
[caption id="attachment_1802" align="alignnone" width="625"] emoji-unicode-platform[/caption]
emoji-unicode-platform[/caption]
emoji 規範自体に戻ると、このようになります:
1F600 ; emoji ; L1 ; secondary ; x # V6.1 () GRINNING FACE
1F48F ; emoji ; L1 ; none ; j # V6.0 () KISS
左端は Unicode コードポイント値で、Unicode 規範に正常に登録されれば、U+1F48F は KISS 絵文字に対応します:
> '\u{1F48F}'
""
このように Unicode と一対一で対応する emoji の他に、Unicode 大家族に加わる以外にも、いくつかの特殊な emoji があります:
-
variation selector-16:不可視文字(
U+FE0F)で、その前の文字を emoji で表示すべきことを示します -
zero width joiner:ゼロ幅接続符で、ゼロ幅スペース(
U+200D)で、複数の emoji を 1 つの emoji に結合するために使用されます -
tone modifier:肌色修飾で、一種の構文で、前の emoji の肌色を変更できます。構文形式は
<emoji>\ud83c[\udffb-\udfff]で、U+D83Cの後に異なる値を付けて異なる肌色制御を表します -
keycap:キーキャップ記号で、キーキャップスタイルの
0-9、#と*で、U+20E3で終わります -
unofficial emoji flag:非常に規な国旗 emoji が存在し、黒い旗(
U+1F3F4)で始まり、キャンセル記号(U+E007F)で終わります
例えば:
// \ufe0f 让黑心字符显示成 emoji,连续两个也没关系
'???' === '\u2764\ufe0f\ufe0f'
'\u2764\ufe0f' === '??'
'\u2764' === '?'
// 零宽连接符\u200d 合成复杂表情, + ?? + + = ?????
'?????' == '\ud83d\udc69\u200d\u2764\ufe0f\u200d\ud83d\udc8b\u200d\ud83d\udc69'
// 肤色修饰,黑 baby、白 baby
'' === '\ud83d\udc76\ud83c\udfff'
'' === '\ud83d\udc76\ud83c\udffb'
// 键帽样式
'#??' === '\u0023\ufe0f\u20e3'
// 非官方国旗
'' ==='\ud83c\udff4\udb40\udc67\udb40\udc62\udb40\udc73\udb40\udc63\udb40\udc74\udb40\udc7f'
四.JavaScript 里的 emoji
ではJS 中で、1 つの emoji は結局いくつの Unicode 文字を含んでいるのか?
> '?'.length
1
> ''.length
2
> '1??'.length
3
> ''.length
4
> '???'.length
11
> ''.length
14
1 つの emoji 字面量の長さは 1 から 14(さらに長いものが存在する可能性もあります)まで様々です……したがって、このような状況が発生します:
> '???我们是一家人'.slice(0, 1)
"?"
> '???我们是一家人'.substr(0, 2)
""
slice(0, 1) で最初の emoji を切り取ろうと期待したが、表示できない文字を取得してしまい、甚至 substr(0, 2) で一家 4 口から Man()を分解してしまいました……これはどうすればよいのか?
一部の emoji については、非常に簡単な処理方法があります。Array.from です:
> Array.from('').length
1
文字列を配列に変換する際にサロゲートペアを一緒に保つため、length は正しくなりますが、この方法は万能ではありません:
> Array.from('???').length
7
P.S. 同様に、Unicode 符号化変換をサポートする bestiejs/punycode.js にも類似の問題があります:
> punycode.ucs2.decode(' ').length
1
> punycode.ucs2.decode('???').length
7
つまり、JS の Unicode へのネイティブサポートだけでは、emoji を含む文字列を正しく処理できません。したがって、一部のシーンで問題に遭遇します:
-
フォーム検証の文字数制限
-
記事要約の切り取り
-
文字列の反転
-
文字単位の処理
-
正規表現マッチ
-
……その他 emoji を含むテキスト処理シーン
例えば:
> '???一个打十个'.length >= 10 === true
true
> '你好 hi233..。'.substr(0, 10)
"你好 hi233?"
> Array.from('1??23').reverse().join('')
"32??1"
> '开心'[0] === ''
false
> /a.b/.test('ab')
false
P.S. JavaScript 中の Unicode のより多くの問題については、JavaScript has a Unicode problem を参照
五.解決方案:emoutils.js
上記に列挙した一連の問題を解決するには、emoji を識別する方法を考えるしかありません。現在(2018/09/15)そのようなツールライブラリは存在しないようです
手作業で作成します。詞法分析 に似ており、文字単位でマッチし、emoji 符号化規則に合致する Unicode 組み合わせを選び出します。詳細は以下のソースコードを参照
Github アドレス:https://github.com/ayqy/emoji-utils
オンライン Demo(テスト case):https://ayqy.github.io/emoji/index.html
API
6 つのシンプルな API を提供します:
// 是不是一个 emoji
isEmoji(str)
// 是否包含 emoji
containsEmoji(str)
// 字符串转 Unicode 数组
str2unicodeArray(str)
// 计算长度
length(str)
// 子串截取
substr(str = '', start = 0, len = Infinity)
// 字符串转数组,相当于 split('')
toArray(str)
内部で公開されていない方法:
// 尝试匹配开头的 emoji,失败返回''
matchOneEmoji(str, matched = '')
欠陥
しかし、これらのツール関数は100% 信頼できません。なぜなら:
Not all browsers, UIs, etc even render ????? as a single symbol. The code assumes the joiners are used between characters appropriately which could be very problematic.
したがって、emoutils.js の実装は 3 つの仮定に基づいています:
-
すべてのサロゲートペアは emoji である(実際には、一部のサロゲートペアは emoji ではない)
-
肌色制御はすべての emoji に有効で、かつ emoji にのみ有効(通常のテキスト記号には無効)
-
joiner で接続された emoji はすべて 1 つとみなす。表示上で 1 つの emoji に合成できるかどうかは問わない
第一の仮定について、サロゲートペア形式は必ずしも emoji とは限らず、純粋なテキストの場合もあります。例えば:
'\ud835\udc00' === ''
後二つの仮定もいくつかの badcase を引き起こします。例えば(Chrome Console 環境):
// 尝试制造黑色笑脸,未遂
'\ud83d\ude0a\ud83c\udfff' === ''
// 尝试人工合成新物种,失败
'\u0023\ufe0f\u20e3\u200d\ud83d\ude0a' === '#???'
'\ud83d\ude0a\u200d\ud83d\ude0a' === '?'
これらの case はすべて 1 つの emoji として識別されますが、Chrome Console 環境での表示は 2 つです。なぜなら:
-
emoji 符号化の構文規則に合致
-
しかし合法的な emoji とは限らない
-
合法的であっても、現在のプラットフォームがサポートしているとは限らない
emoutils.js は第一点を満たすものを独立表示の合法的 emoji と仮定し、emoji 規範バージョンおよびプラットフォームサポート性を考慮していないため、このような badcase が存在します。badcase がもたらす影響は:
-
isEmoji/containsEmoji()が''に類似したテキスト文字を誤判断 -
length()が実際の表示文字長さより小さい -
substr()/toArray()が実際の予想と一致しない
したがって、このツールライブラリが識別できる文字セットは emoji の超集合で、追加の一部はサロゲートペア形式のテキスト、および emoji 符号化規則に合致するが emoji 規範中で定義されていない文字シーケンスです。それにもかかわらず、実際の応用では大多数のシーンに対応するのに十分です
P.S. emoji を正確に処理する必要があるシーンについては、emoji-regex の検討を推奨します
参考資料
-
[Finally moving past "".length === 2](https://medium.com/ @jtenclay/finally-moving-past-length-2-86054156b180)
-
Can you use String.fromCodePoint just like String.fromCharCode
コメントはまだありません