設計思想
何を表現したいのか?Reactはアプリケーションをどう理解しているのか?
アプリケーションは状態機械(ステートマシン)であり、状態がビューを駆動する。
v = f(d)
v はビュー
f はコンポーネント
d はデータ/状態
FP(関数型プログラミング)との関係は?
関数型の思想をフロントエンドに導入し、PureComponent の組み合わせによって UI を実現する。
最大の利点は UI を予測可能にすること であり、同じ f に対して同じ d を入力すれば、必ず同じ v が得られる。
個々の f を個別にテストすることができ、それらを組み合わせても問題ないことが保証されるため、理論上コンポーネントの品質が信頼でき、組み合わされたアプリケーション全体の UI も信頼できるものになる。
目標
何を解決したいのか?ポジショニングは?
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
UI の構築に対してコンポーネント化されたソリューションを提供する。
どのような問題を解決できるのか?
-
コンポーネント化
-
UI の信頼性
-
データ駆動型ビュー
パフォーマンスの目標
For many applications, using React will lead to a fast user interface without doing much work to specifically optimize for performance.
コストと収益のバランスポイントを模索し、意図的なパフォーマンス最適化を行わなくても、*パフォーマンスの良い(最適ではないが)*アプリケーションを書くことができる。
実際、React が行っているパフォーマンス最適化は主に以下に現れている:
-
イベントデリゲーション、グローバルで一つのイベントリスナー
-
独自の完全なキャプチャとバブリングを持ち、これは IE8 のバグを吸収するためである。
-
オブジェクトプールによる
eventオブジェクトの再利用、GC(ガベージコレクション)の削減。
-
-
DOM 操作の統合、実行回数の削減。
しかし、いずれにせよ、パフォーマンスは熟練した(経験豊富な)フロントエンドエンジニアが手書きしたネイティブな DOM 操作版には及ばない。
仮想 DOM
どのような方法で問題を解決するのか?
DOM ツリーの上に一層の追加の抽象化を加える。
コンポーネント化の手法:コンポーネントのクラス形式テンプレート、ライフサイクル hook、データの流れ、ローカル状態の管理の提供。
実行時:仮想 DOM ツリーでコンポーネントを管理し、リアル DOM ツリーとのマッピング関係を構築・維持する。
仮想 DOM にはどのような役割があるのか?
-
バッチ処理によるパフォーマンス向上
-
diff コストの削減
-
「データバインディング」の実現
具体的な実装
JSX -> React Element -> 仮想 DOM ノード ..> リアル DOM ノード
記述オブジェクト
-
コンパイル時に JSX をパースして
createElementを得る。 -
createElementを実行して React Element 記述オブジェクトを得る。 -
記述オブジェクトに基づいて仮想 DOM ノードを作成する。
-
仮想 DOM ノード上の状態を統合し、リアル DOM ノードを作成する。
仮想 DOM ツリーのノード集合はリアル DOM ツリーのノード集合のスーパーセットであり、余分な部分はカスタムコンポーネント(Wrapper)である。
構造的には、内部のツリーレイアウトは森林であり、instancesByReactRootID で管理される:
-
既存のアプリに React を導入する場合、複数のルート DOM ノードが存在することがある。
-
純粋な React アプリケーションでは、通常、森の中にツリーは1つしかない。
単方向データフロー
ウォーターフォールモデル
props と state によってコンポーネントが組織化され、コンポーネント間のデータの流れはウォーターフォールに似ている。
データの流れは常に先祖から子孫(根から葉)へ向かい、逆流することはない:
-
props:パイプ -
state:水源
単方向データフローは状態破棄メカニズムによって決定され、具体的には以下のように現れる:
-
状態の変化によって引き起こされるデータおよび UI の変化は、下方のコンポーネントにのみ影響する。
-
レンダリングビュー時は下向きに流れ、フォームのインタラクションによって戻ることができ、それが再び下向きのレンダリングを引き起こす。
単方向データフローはビューのレンダリングプロセスに関してのものであり、子孫の state がどのように変化しても先祖には影響しない(先祖に自身の state を更新するよう通知しない限り)。
state と props
state は最小の可変状態セットであり、特徴は:
-
プライベートである。コンポーネント自身によって完全に制御され、上方から来るものではない。
-
可変である。時間とともに変化する。
-
独立して存在する。他の
stateやpropsから計算して出すことはできない。
props は不変であり、ビューテンプレートを埋めるためだけに私用される:
props React Element 記述オブジェクト
-----> コンポーネント ---------------------> ビュー
データバインディング?
2つのステップ
-
依存関係の収集(静的依存 / 動的依存)
-
変化の監視
初回レンダリング時に data-view のマッピング関係を収集し、その後のデータ変化を確認した後、データに対応するビューを更新する。
実装方法
| 実装方法 | 依存関係の収集 | 変化の監視 | 事例 |
|---|---|---|---|
| getter & setter | getter | setter による変化の監視 | Vue |
| データモデルの提供 | テンプレートの解析 | すべてのデータ操作がフレームワークの API を経由し、変化を通知する | Ember |
| ダーティチェック | テンプレートの解析 | 適切なタイミングで最新の値と前回の値を比較し、変化をチェックする | Angular |
| 仮想 DOM diff | ほとんど収集しない | setState による変化の通知 | React |
依存関係の収集の粒度から見ると:
-
Vue は
getterを通じて動的に依存関係を収集するため、粒度が最も細かく、正確である。 -
Ember と Angular はどちらも静的なテンプレート解析によって依存関係を見つけ出す。
-
React は最も大まかで、ほとんど依存関係を収集せず、サブツリー全体を再レンダリングする。
state が変化した際、対応するサブツリーの内部状態を再計算し、比較して変化を見つけ出し(diff)、適切なタイミングでそれらの変化を適用する(patch)。
細粒度の依存関係の収集は正確な DOM 更新の基盤となる(どのデータがどの要素のどの属性に影響するか)。余計な推測や判断をする必要がなく、フレームワークが影響を受けるビュー要素や属性を明確に知っていれば、直接最も細かい粒度で DOM 操作を行うことができる。
仮想 DOM diff アルゴリズム
React は依存関係を収集せず、以下の2つの既知条件しかない:
-
この
stateがどのコンポーネントに属しているか -
この
stateの変化は対応するサブツリーにのみ影響する
サブツリーの範囲は、最終的なビュー更新に必要な DOM 操作としては大きすぎるため、*細分化(diff)*が必要である。
tree diff
ツリーの diff は比較的複雑な(NP)問題である。まずシンプルなシナリオを考えてみる:
A A'
/ \ ? / | \
B C -> G B C
/ \ | | |
D E F D E
diff(treeA, treeA') の結果は以下のようになるはずである:
1. B の前に G を挿入 (insert)
2. E を F に移動 (move)
3. F を削除 (remove)
コンピュータにこれをやらせる場合、「追加」と「削除」は見つけやすいが、「移動」の判定は非常に複雑になる。まずツリーの類似度を定量化し(重み付き編集距離など)、類似度がどれくらいであれば「移動」が「削除+追加」よりも効率的(操作ステップが少ない)かを判断する必要がある。
React diff
仮想 DOM サブツリーの diff も同様の問題に直面するが、DOM 操作シナリオの特徴を考慮する:
-
局所的な小さな変更が多く、広範囲の変更は少ない(パフォーマンスを考慮し、表示・非表示で回避する)。
-
階層をまたぐ移動は少なく、同階層のノード移動が多い(テーブルのソートなど)。
仮定:
-
異なるタイプの要素は異なるサブツリーに対応すると仮定する(「サブツリーの構造が似ているかどうか下まで見る」ことを考慮しなければ、移動の判断は難しくなくなる)。
-
変更前後の構造には一意の
keyが付与され、それをdiffの根拠とする。同じkeyは同じ要素であると仮定する(比較コストを下げる)。
これにより、tree diff 問題は list diff(文字列編集問題)に簡略化される:
-
新しい方をトラバースし、追加 / 移動を見つける。
-
古い方をトラバースし、削除を見つける。
本質的には非常に弱い文字列編集アルゴリズムである。そのため、diff のオーバーヘッドを考慮しなくても、最終的な実際の DOM 操作だけを見れば、パフォーマンスは(手動の DOM 操作と比較して)最適ではない。
また、念のため React は shouldComponentUpdate フックを提供しており、diff プロセスへの人工的な介入を許可し、誤判定を避けることができる。
状態管理
状態の共有と伝達
-
兄弟 -> 兄弟:共有状態をリフトアップし、上から下への単方向データフローを保証する。
-
子 -> 親:親から事前に関数(コールバック)を
propsとして渡す。 -
? -> 遠い親戚:遠距離の通信は解決が難しく、手動でリレーするか、
contextを通じて共有する必要がある。
状態をリフトアップして共有することで、孤立した状態を減らし、バグの発生面を減らすことができるが、やはり手間がかかる。コンポーネント間の遠距離通信問題には、まだ優れた解決策がない。
もう一つの問題は、複雑なアプリケーションにおいて、状態の変化(setState)が各コンポーネントに散在し、ロジックが分散しすぎて保守上の問題が発生することである。
Flux
状態管理の問題を解決するために Flux パターンが提案された。目標は データを予測可能にすること である。
基本的な考え方
(state, action) => state
具体的な手法
-
明示的なデータを使用し、派生データは使用しない(宣言してから使用し、一時的にデータを作らない)。
-
データとビューの状態を分離する(データレイヤーを抽出する)。
-
連鎖的な更新による連鎖的な影響を避ける(M と V が互いに影響し合い、データフローが不明確になるのを防ぐ)。
構造
action の生成 action の伝達 state の更新
view のインタラクション -----------> dispatcher -----------> stores --------------> views
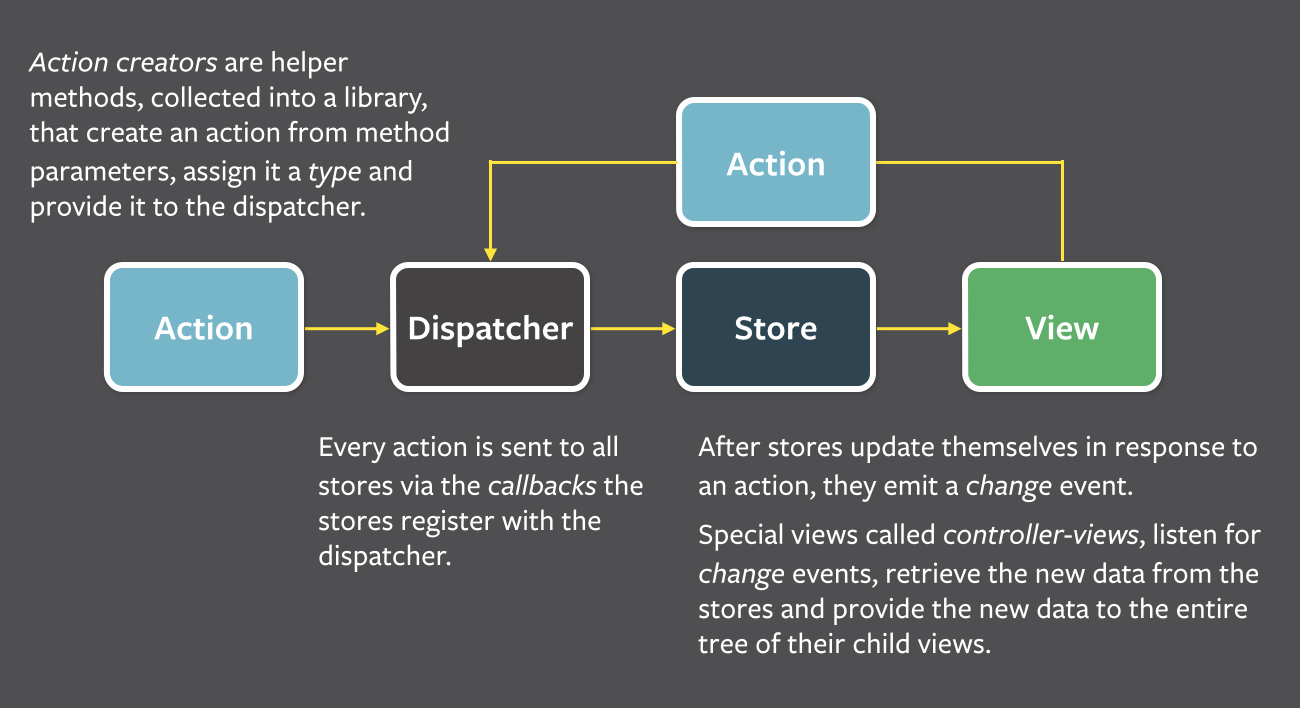
特徴は store が比較的重いことであり、action に基づいて内部の state を更新し、state の変化を view に同期させる責任を持つ。
container と view
container とは、実のところ controller-view のことである:
-
view を制御するための React コンポーネント。
-
基本的な役割は store からの情報を収集し、自身の state に保存すること。
-
propsや UI ロジックを含まない。
Redux の取捨選択
action Flux と同様にイベントであり、type と data (payload) を持つ
同様に手動で action を dispatch する
---
store Flux と機能は同じだが、グローバルに1つしかない。実装上は不変な状態ツリーである
action を配信し、listener を登録する。各 action は層ごとの reducer を経て新しい state を得る
---
reducer arr.reduce(callback, [initialValue]) と同様の役割を果たす
reducer は callback に相当し、現在の state と action を入力として受け取り、新しい state を出力する
call new state
action --> store ------> reducers -----------> view
アプリケーション全体の状態を 不変な状態ツリー で管理する。直接変更することはできず、変化が生じる際は action と reducer を通じて新しいオブジェクトを作成する。
reducer の概念は Node のミドル���ェアや gulp のプラグインに相当する。各 reducer は状態ツリーの小さな一部分を担当し、一連の reducer を連結させる(前の reducer の出力を現在の reducer の入力とする)ことで、最終的な出力 state を得る。
Flux との比較
-
store の数を 1 つに限定している。
-
dispatcher を廃止し、action をすべてのトップレベル reducer に渡し、対応するサブツリーに流す。
-
action に基づいて内部 state を更新する部分を独立させ、各 reducer に分解している。
dispatcher を廃止できたのは、純粋関数である reducer は自由な組み合わせが可能であり、順序を別途管理する必要がないからである。
react-redux
Redux と React には直接の関係はない。Redux は状態管理レイヤーとして、Backbone、Angular、React など、あらゆる UI ソリューションと組み合わせて使用できる。
react-redux は new state -> view の部分を処理する。つまり、新しい state ができた後、どのようにビューを同期させるか?
container
container は特殊なコンポーネントであり、ビューロジックを含まず、store と密接に関連している。ロジックとしての機能は、store.subscribe() を通じて状態ツリーの一部を読み取り、props として下方の通常のコンポーネント(view)に渡すことである。
connect()
一見不思議に見える API だが、主に以下の 3 つのことを行う:
-
container の生成。
-
dispatch と state データを props として下方の通常コンポーネントに注入する責任を持つ。
-
組み込みのパフォーマンス最適化により、不要な更新を避ける(shouldComponentUpdate の組み込み)。
Provider とは何か?
目的:手動で store を各階層に渡す手間を省く。
実装:トップレベルで context を通じて store を注入し、下方のすべてのコンポーネントが store を共有できるようにする。
エコシステム
-
デバッグツール DevTools
-
プラットフォーム React Native
-
コンポーネントライブラリ antd, Material-UI
-
発展 Rax
-
状態管理レイヤー Redux Saga, Dva
コメントはまだありません