一.Scalability とは何か?
Scalability is the property of a system to handle a growing amount of work by adding resources to the system.
(Scalability より引用)
つまり、システムにリソースを追加することで、増加するワークロードに対応することです
では、どのようにリソースを追加するのでしょうか?
二.ハードウェアリソースの拡張
リソースの追加方法には 2 通りあります。垂直拡張と水平拡張です
垂直拡張
垂直拡張(Vertical scaling)とは、単一マシンの構成を向上させ、単一マシンにメモリ、プロセッサ、ハードディスクなどのハードウェアリソースを追加することです。十分な予算を投入すれば、豪華な構成のサーバーを構築できます
しかし、このような単一点強化型の拡張を無限に続けることはできません。すぐに最高構成に達するか(または予算を使い果たすか)するため、完全なソリューションとは言えません
水平拡張
もう一つのリソース追加方法は水平拡張(Horizontal scaling)で、つまりマシンを追加し、数を 1 台から複数台に拡張し、複数サーバーでトポロジ構造を形成します。十分な予算を投入すれば、データセンターを持つことができ、さらには世界中に分散させることもできます
理論上、水平拡張には上限がありません。無限に多くのサーバーを使用して無限に多くのユーザーリクエストをサポートできます。さらに、水平拡張は冗長性(Replication)を導入することになり、単一マシンよりも信頼性が高くなります
しかし、マシンが 1 台から複数台になった後、直面する最大の問題はリソース配分です。これらのマシンをどのように十分に活用するか?つまり、どのように負荷を均衡させるか?
三.負荷分散
負荷分散装置(Load Balancer)はユーザーリクエストを複数のサーバーに配信する役割を果たします。具体的には、パブリックネットワーク Load Balancer がルーティングルールに基づいてインバウンド HTTP リクエストを配信し、データパケットを実際にどのイントラネットサーバーに送信するかを決定します
一般的な配信戦略には以下があります:
-
負荷状況に基づく配信
-
順次均等配分
-
リソース依存状況に基づく配信
もちろん、最も理想的な配分戦略はサーバーの現在の負荷状況に基づく配信です。例えば、新しいリクエストをあまり忙しくないサーバーに任せることですが、問題は負荷状況がそれほど簡単に正確に把握できないことです
最もシンプルな配分戦略はラウンドロビン(Round robin)です。例えば、1 回目の URL リクエスト時に Server1 の IP アドレスを返し、2 回目に Server2 の IP アドレスを返します……しかし、ラウンドロビン作業は平等に扱うことを意味し、各リクエストのワークロードが同じで、各 Server の処理能力も同じと仮定しますが、実際のシナリオではほとんどの場合このような条件を満たしません
P.S.DNS を負荷分散装置として使用することは推奨されません(一連の A レコードを追加)。オペレーティングシステムおよびアプリケーション層の DNS キャッシュがこの順次均等配分のメカニズムを破壊するためです
一方、不同类型的サービスはリソースへの依存状況(帯域幅、ストレージ、計算能力など)が異なる可能性があるため、専用サーバーを採用し、リソース依存状況に基づいて配信することもできます。例えば、gif、jpg、image、video などに異なる専用サーバーを使用し、サブドメインなどの方法で区別します
セッション維持
Load Balancer を 1 層追加することでリソース配分の問題が解決しましたが、また新たな問題をもたらしました:前後の 2 つのリクエストが負荷分散装置によって異なるサーバーに転送される可能性があります。これら 2 つのリクエストに関連がある場合(例えばログインと注文)、前置の状態が失われます(ユーザーがログインした直後に注文をクリックすると、再びログインを要求される可能性があります)
一つの解決方法はスティッキーセッション(Sticky sessions)で、関連するリクエストを同じサーバーに転送します:
Send all requests in a user session consistently to the same backend server.
(Load balancing (computing) より引用)
例えば Cookie にサーバーの識別情報を載せ、その後一連のリクエストをそのサーバーに転送します
P.S.しかし Cookie は無効化される可能性があるため、一般的には複数の方法を総合的に使用してセッションを維持します
もう一つの方案は Session を「アウトソーシング」し、公共の場所に保存して、他のサーバーが共有アクセスできるようにすることです:
Every server contains exactly the same codebase and does not store any user-related data, like sessions or profile pictures, on local disc or memory. Sessions need to be stored in a centralized data store which is accessible to all your application servers.
至此、私たちはいくつかのマシンを追加し、負荷分散装置を通じて複数マシンで共同分担して稼働させました。すべてが完璧に見えます……では、この負荷分散装置がダウンしたらどうでしょうか?
四.冗長性の導入
負荷分散装置を導入した後、すべての��クエストはまず負荷分散装置を経由する必要があり、負荷分散装置はネットワークトポロジ構造における脆弱な単一点となります。一旦发生故障、身後のすべてのサーバーにアクセスできなくなります
冗長な負荷分散装置
単一点障害(Single Point of Failure)を回避するため、負荷分散装置にも冗長性を導入する必要があります(例えば一対の負荷分散装置を使用)。一般的に 2 つのフェイルオーバー(Fail-over)モードがあります:
-
アクティブ - パッシブ(Active-passive):アクティブが作業し、パッシブが待機。アクティブがダウンした後パッシブが引き継ぐ
-
アクティブ - アクティブ(Active-active):同時に作業。一つがダウンしても影響なし
どちらの作業モードを採用しても、冗長性を導入することでダウンタイムを短縮し、システムの信頼性と可用性を向上させることができます
五.データベースの拡張
理論上、信頼できる負荷分散メカニズムがあれば、1 台のサーバーを簡単に n 台に拡張できます。しかし、これら n 台のマシンが依然として同一データベースを使用する場合、すぐにデータベースがシステムのパフォーマンスボトルネックと信頼性ボトルネックになります
同様の方法で、データベースの処理能力を拡張し、いくつかの庫を追加できます。つまり冗長性を導入します。一般的に 2 つのモードがあります:
-
マスタースレーブ複製:マスター庫が直接読み書きし、スレーブ庫はマスター庫がクエリを受信した際に、同じクエリを実行します。マスター庫がダウンした場合、スレーブ庫の中から一つをマスター庫に昇格させます
-
マスターマスター複製:どちらも書き込み可能で、書き込み操作ももう一つの庫に複製されます
データベースに冗長性を導入した後、複数のスレーブ庫に対して負荷分散を行うこともできます(特に読み取り集中のシナリオに適しています):

およびコンテンツの特性に基づくパーティションストレージ(Partitioning):
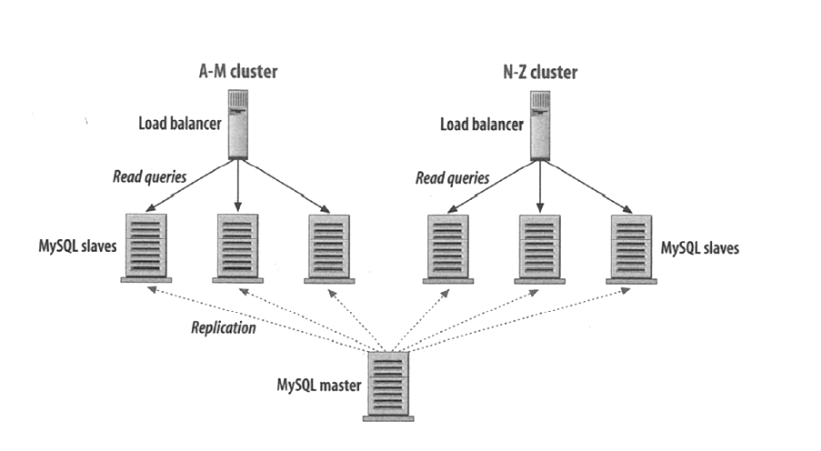
姓名が A-M 始まりのデータを左側のいくつかのデータベースに保存し、N-Z 始まりのものを右側に保存します
同時に、分庫分表(Sharding)、非正規化(Denormalization)、SQL チューニング(SQL tuning)などの方法でクエリを最適化することもできます
ここまでに、データベース層で可能な拡張最適化は限界に達したようです。では、データベースの圧力を軽減する他の方法はあるでしょうか?
六.キャッシュ
もう一つの考え方はデータベース操作を可能な限り減らすことです。例えば Web サービスとデータの間にもう一層メモリキャッシュを追加し、クエリ時に優先的にキャッシュを通し、キャッシュにない場合のみデータベースから取得します
一般的に 2 つのキャッシュモードがあります:
-
クエリ結果のキャッシュ
-
オブジェクトのキャッシュ
すべてのクエリ結果をキャッシュする最大の 문제는、データが変化した後、キャッシュが期限切れかどうかを判定するのが難しいことです:
It is hard to delete a cached result when you cache a complex query (who has not?). When one piece of data changes (for example a table cell) you need to delete all cached queries who may include that table cell.
一方、オブジェクトのキャッシュとは、原始データに基づいて組み立てられたデータモデル(例えば Java クラスインスタンス)をキャッシュすることを指します。利点はデータ変化を把握した後、それと論理的に関連するデータオブジェクトを破棄でき、キャッシュ期限切れの難題を解決できることです
至此、私たちはボトムアップでハードウェアリソース、データベース、キャッシュを含むスケーラビリティ問題について議論しました。では、Web サービス自体はどのように拡張すべきでしょうか?
七.非同期処理
Web サービスにとって、スケーラビリティを向上させる主要な経路は時間のかかる同期作業を非同期処理に変更することです。これにより、これらの作業を複数の Worker に「アウトソーシング」したり、予測可能な部分を事前に完了させたりできます
コメントはまだありません