前置き
UC Berkeley は 2019 年 2 月 10 日に Serverless に関する論文を発表し、業界でここ数ヶ月 Serverless に対する熱い議論を巻き起こしました
バークレーの研究者たちは、Serverless はほぼすべてのシステム管理操作を処理でき、開発者がより簡単にクラウドを利用できるようにすると考えています。クラウドプログラミングを大幅に簡素化すると同時に、アセンブリ言語から高級プログラミング言語への進化に似た変遷を表しています:
Serverless cloud computing handles virtually all the system administration operations needed to make it easier for programmers to use the cloud. It provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages.
さらにServerless がクラウドコンピューティングの未来を主導すると考えています:
Just as the 2009 paper identified challenges for the cloud and predicted they would be addressed and that cloud use would accelerate, we predict these issues are solvable and that serverless computing will grow to dominate the future of cloud computing.
一.10 年前の 6 つの予言
10 年前(2009 年 2 月 10 日)、UC Berkeley は Cloud Computing に関する論文でクラウドコンピューティングの 6 大潜在優位性を指摘しました:
-
必要に応じて無限の計算リソースを提供可能
-
クラウドユーザーはリソースを予測する必要がない
-
即時使用即時支払いの短期計算リソースを提供
-
超大規模データセンターが形成する規模の経済がコストを大幅に削減
-
リソースの仮想化を通じて操作を簡素化し利用率を向上
-
マルチプレックスを通じてハードウェア利用率を向上
P.S.これらの予言に関する詳細情報は、[バークレー研究者たち眼中的 Cloud Computing](/articles/伯克利研究员们眼中的 cloud-computing/) を参照
現在に至るまで、これらの優位性は基本的にすべて実現されました。しかし操作の複雑さは依然としてクラウドユーザーを悩ませており、マルチプレックスの優位性も完全に発揮されていません:
-
クラウドコンピューティングは物理インフラストラクチャの管理負担を軽減しましたが、同様に管理が必要な大量の仮想リソースを生み出しました
-
マルチプレックスはバッチ処理のシーン(例えば MapReduce や高性能計算)で威力を発揮できますが、ステートフルなサービス(例えばデータ管理システムなどの企業アプリケーション)では効果を発揮しにくいです
P.S.マルチプレックス は通信分野で広く使用されているリソース共有技術で、時分割多重(Time-division multiplexing)、周波数分割多重(Frequency-division multiplexing)などを含みます
その理由は市場がより低いレベルのリソース抽象化方式を選択し、クラウドユーザーは物理ハードウェアを使用するようにリソーススタック全体を制御し、依然として以下を考慮する必要があります:
-
可用性冗長(単一障害点を回避)
-
遠隔地災害対策
-
ロードバランシング
-
弾力的スケーリング
-
監視
-
ログ(デバッグまたはパフォーマンス診断用)
-
システムアップグレード(セキュリティパッチなど)
-
移植性(新しいインスタンスへの移行)
二.Serverless Computing 登場
概念定義
易用性方面的なニーズを認識した後、Amazon は 2015 年に AWS Lambda サービス、つまり*クラウド関数(cloud functions)をリリースし、続いてサーバーレスコンピューティング(serverless computing)*の理念に対する広範な注目を引き起こしました:
Serverless suggests that the cloud user simply writes the code and leaves all the server provisioning and administration tasks to the cloud provider.
サーバー関連の設定管理作業をすべてクラウドプロバイダーに任せ、ユーザーのクラウドリソース管理負担を軽減します
したがって、Serverless Computing は computing するために server が不要だと言うのではなく、ユーザーにとって server を管理するために大きな精力を費やす必要がない ということです。同様に、Serverless サービスは(自動的に)弾力的にスケーリングでき、明示的にリソースをプロビジョニングする必要がなく、使用状況に応じて課金されます
另一方面、Serverless はさらに一種のパラダイムシフトをもたらしました——プロバイダーに完全に操作を委ねることを許可し、これにより細粒度のマルチテナントマルチプレックスを可能にしました:
Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplex- ing.
Serverless の核心は FaaS(Function as a Service) ですが、クラウドプラットフォームは通常 BaaS (Backend as a Service) などの特定アプリケーション要件を満たすために Serverless フレームワークも提供します。したがって、簡単に理解できます:
Serverless computing = FaaS + BaaS
基本アーキテクチャ
Serverless レイヤーはアプリケーションレイヤーと基礎クラウドプラットフォームレイヤーの間に位置し、クラウドプログラミングを簡素化するために使用されます:
[caption id="attachment_2050" align="alignnone" width="625"]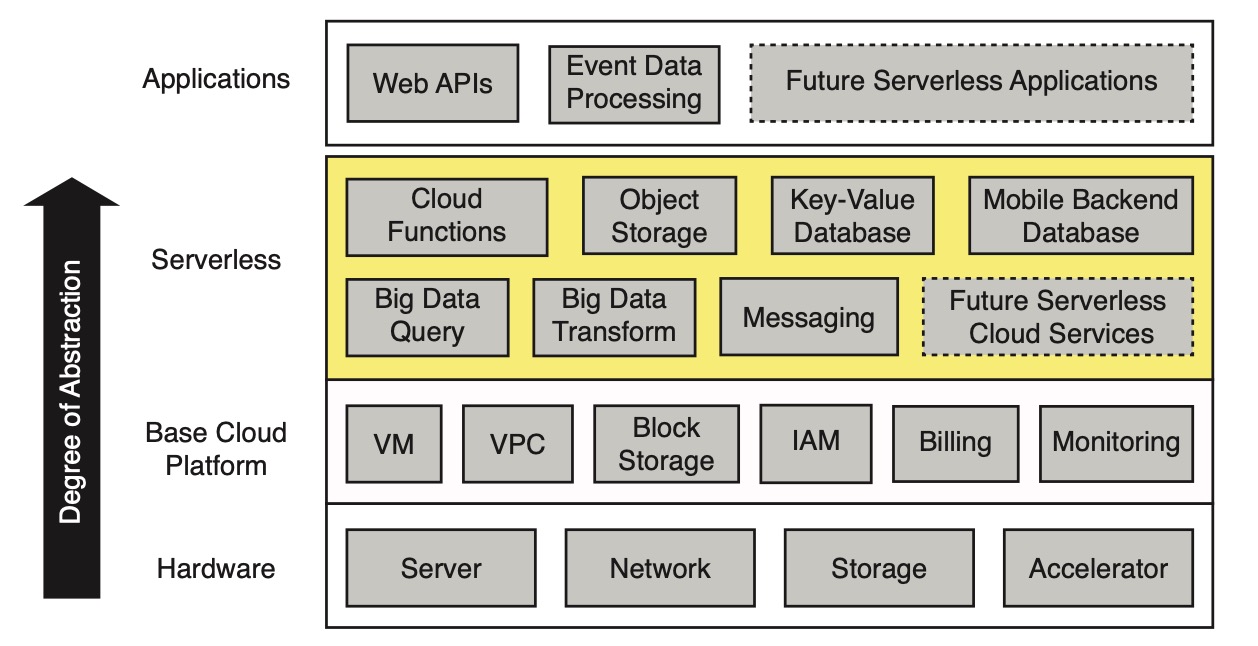 Architecture of the serverless cloud[/caption]
Architecture of the serverless cloud[/caption]
その中で、クラウド関数(Cloud functions、例えば FaaS)は通常計算を提供し、特定の BaaS 製品エコシステム(例えばオブジェクトストレージ、データベース、メッセージメカニズムなど)で補完されます。基礎プラットフォームには仮想マシン(VM)、専用ネットワーク(VPC)、仮想化データブロックストレージ、ID およびアクセス管理(IAM)、および課金と監視が含まれます
Serverless と Serverful
ユーザーは Serverless プラットフォームで高級言語でいくつかのクラウド関数を書くだけで、その関数の実行をトリガーするイベントを選択するだけです。その後のことは Serverless システムが処理し、インスタンス選択、スケーリング、デプロイ、フォールトトレランス、監視、ログ、セキュリティパッチなどすべて気にする必要がなく、クラウドリソースの易用性を向上させることでアプリケーション開発を簡素化します
クラウドの背景下で、クラウド開発者にとって、伝統的な方式(Serverful Computing)は底辺のアセンブリ言語を使用しているようなもので、c = a + b のような簡単な計算でさえ一連の操作を経る必要があります:
-
1 つまたは 2 つのレジスタを選択(リソースをプロビジョニングまたは利用可能なリソースを見つける)
-
値をレジスタにロード(コードとデータをロード)
-
算術演算を実行(計算を実行)
-
計算結果を保存(結果を返却または保存し、最後にリソースを解放)
一方 Serverless 方式は Python などの高級言語でプログラミングするようなもので、これらの煩雑な操作を免除されます
したがって、Serverless が最も潜在的な場所はクラウド開発者に高級言語への前進に似たこのようなメリットをもたらせることです:
The aim and opportunity in serverless computing is to give cloud programmers benefits similar to those in the transition to high-level programming languages.
高級プログラミング環境のいくつかの特性は Serverless に自然な類似点があります。例えば、自動��的なメモリ管理は開発者をメモリリソースの管理作業から解放しますが、Serverless は開発者をサーバーリソースの管理作業から解放する必要があります
正確に言えば、Serverless と Serverful の最も重要な違いは:
-
計算とストレージを分離:ストレージと計算を別々にスケーリングし、独立してプロビジョニングし、独立して価格設定。通常ストレージは別のクラウドサービスによって提供され、計算はステートレス
-
リソース割り当てを管理せずにコードを実行可能:ユーザーはコードを提供し、クラウドは自動的にリソースをプロビジョニングして実行
-
使用に応じて課金し、割り当てられたリソースに応じて課金しない:コード実行の関連次元(例えば実行時間)に応じて課金し、クラウドプラットフォームの関連次元(例えば割り当てられた VM のサイズと数量)に応じて課金しない
三.重要な特徴
聞くところによると以前のいくつかのパターンとあまり大きな違いがないようです:
-
既存のいくつかの PaaS 製品、例えば Firebase、Heroku、Parse などは Serverless のようだ
-
80 年代の Web ホスティング環境も Serverless が主張するメリットを提供できたのではないか?
-
10 年前の Google AppEngine のように聞こえるが、これは Serverless 理念が出現する前にすでに市場に拒絶された呀
では、以前のこれらのパターンと比較して、Serverless の重要な特徴は何でしょうか?
スケーラビリティ
スケーラビリティ方面では、AWS Lambda は負荷状況を正確に追跡でき、必要に応じて迅速に拡張し、閑散時にはゼロリソース、ゼロコストまで縮小できます。さらに細かい粒度で課金(100ms)でき、伝統的な弾力的スケーリングサービスは通常時間単位で課金します
最も重要なのは、Serverless の出発点はコードが実際に実行された時間に応じて課金することで、プログラム実行のために予約されたリソースではない ことです:
In a critical departure, it charged the customer for the time their code was actually executing, not for the resources reserved to execute their program.
この違いはクラウドプロバイダーが弾力的スケーリングという点でクラウドユーザーとリスクを共担し、利益を共有できることを保証し(skin in the game)、続いて効率的なリソース割り当てを促進します
強力な隔離性
Serverless は強力なパフォーマンスとセキュリティ隔離性依靠してマルチテナントがハードウェアを共有することを實現します
クラウド関数に対して、VM 隔離は現在の標準方案ですが、VM をプロビジョニングするには数秒かかる可能性があるため、クラウドプロバイダーは関数実行環境の作成を加速するためにいくつかの精細な技術を使用します。例えば AWS Lambda は即座にテナントに割り当て可能な VM を管理するホット VM プール(a "warm pool" of VM)と、すでに関数を実行中または実行準備ができているインスタンスを管理するアクティブインスタンスプール(an "active pool" of instances)を維持しています
リソースライフサイクルの管理とマルチテナント装箱戦略(multi-tenant bin packing)は高利用率を実現する鍵 で、Serverless にとって極めて重要です。大多はコンテナ、単一コア、ライブラリ OS(library OS)または言語 VM などの技術を利用してマルチテナント隔離のオーバーヘッドを削減します。例えば Google App Engine が使用する gVisor、AWS Lambda 中の Firecracker VM、および CloudFlare Workers プラットフォームが Web ブラウザサンドボックス技術を採用して JavaScript クラウド関数間のマルチテナント隔離を実現します
プラットフォーム柔軟性
PaaS サービスは通常特定のユースケースと密接に関連していますが、Serverless はユーザーが自分のライブラリを使用することを許可し、サポートできるアプリケーションは PaaS よりも広範です
しかも、Serverless は現代化された大規模データセンターで実行され、サポートできる実行規模は古い共有 web ホスティング環境よりもはるかに大きいです
サービスエコシステムサポート
クラウド関数(例えば FaaS)は Serverless モードを成功裡に普及させ、その一部は公有クラウド以来存在するいくつかの BaaS サービス(例えば AWS S3)に帰せられます。これらの BaaS サービスはすべて特定分野面向、高度に最適化された Serverless 実装と見なすことができ、クラウド関数はより汎用的な Serverless 表現形式です:
| Service | Programming Interface | Cost Model |
|---|---|---|
| Cloud Functions | Arbitrary code | Function execution time |
| BigQuery/Athena | SQL-like query | The amount of data scanned by the query |
| DynamoDB | puts() and gets() | Per put() or get() request + storage |
| SQS | enqueue/dequeue events | per-API call |
四.核心優位性
クラウドプロバイダーにとって、Serverless は業務成長を促進し、クラウドプログラミングを簡素化し、新規ユーザーを惹きつけ、既存ユーザーがクラウドリソースを十分に活用するのを助けます。さらに、実行時間が短く、メモリ占有が低く、ステートレスの特性は統計的复用に有利 です。これらのタスクを実行する時、クラウドプロバイダーは使用されていないリソースをより簡単に見つけられます。さらに那些あまり人気がないマシン(例えば古いマシン)をより良く利用することもできます。インスタンスタイプはクラウドプロバイダーによって決定されるため、これら 2 点は既存リソースの基礎上で即座に収益を増加できます
クラウドユーザーにとって、プログラミング生産性を向上させる之外、大多数のシーンではコストも節約できます。底辺サーバーの利用率が向上したためです。いかなるクラウドインフラストラクチャもない状況でも直接関数をデプロイでき、デプロイ時間を節約するだけでなく、クラウドユーザーにアプリケーション自身の問題に集中させ、資金も節約できます。関数はイベントが発生した時にのみ実行され、細かい粒度の課金方式(現在は 100ms)は実際に使用した分に応じて課金することを意味し、予約されたリソースに応じて課金するのではありません
研究角度から見ると、Serverless は一種の新しい汎用計算抽象で、クラウドコンピューティングの未来になると期待されています。Serverless はクラウドデプロイレベルを x86 マシンコードから高級プログラミング言語に引き上げ、アーキテクチャイノベーショ��を実現します。もし ARM または RISC-V が x86 よりコストパフォーマンスが高い場合、Serverless も簡単に命令セットを変更できます。さらにクラウドプロバイダーは(プログラミング)言語面向の最適化および特定分野の特殊アーキテクチャを研究することで Python などの言語で書かれたプログラムを加速できます
P.S.99% のクラウド計算機は x86 アーキテクチャ(x86 マイクロプロセッサ + x86 命令セット)を使用しています
五.既存 Serverless プラットフォームの局限性
現在、クラウド関数は API サービス、イベントストリーム処理および限られた ETL(Extract-Transform-Load、データ処理)を含む多種の作業に成功裡に適用されています。では、なぜより多くの汎用サービスを担持できないのでしょうか?
その理由は:
-
細粒度操作のストレージサポートが不足:現在のクラウドストレージサービスはクラウド関数のニーズを満たせない
-
細粒度調整が不足:マルチタスク調整メカニズムがない
-
標準通信モード下でパフォーマンスが非常に悪い:マルチタスク間でデータを共有、集約できない
-
パフォーマンスが予測不可能:伝統的な VM ベースのインスタンス起動遅延よりも低いが、某些アプリケーションにとって新しいインスタンスを起動する遅延は依然として高すぎる
細粒度操作のストレージ不足
Serverless プラットフォームのステートレス性は共有細粒度状態を必要とするアプリケーションをサポートすることを難しく実現させ、現在主にクラウドストレージサービスに制限されています
オブジェクトストレージサービス(例えば AWS S3、Azure Blob Storage、Google Cloud Storage)は迅速に拡張でき、安価な長期オブジェクトストレージを提供しますが、非常に高いアクセスコストと遅延が存在します。近期テスト表明読書/書き込み小オブジェクトは少なくとも 10ms 必要で、10 万 IOPS(毎秒読書書き込み回数、Input/Output Operations Per Second)を維持するコストは 30 ドル/分で、AWS ElastiCache インスタンスより 3 から 4 桁高く、ElastiCache インスタンスはサブミリ秒級読書書き込み遅延しかなく、その IOPS は甚至 100K を超えられます
KV データベース(例えば AWS DynamoDB、Google Cloud Datastore、Azure Cosmos DB)はすべて高 IOPS サポートを提供しますが、すべて非常に高価で、迅速に拡張できません。クラウドプロバイダーは人気のあるオープンソースプロジェクト(例えば Memcached または Redis)に基づくメモリストレージインスタンスも提供しますが、フォールトトレランスサポートが不足し、Serverless プラットフォームのように自動的にスケーリングできません
Serverless インフラストラクチャ上に構築されたアプリケーションはプロビジョニング透明なストレージサービスを必要とし、つまり計算と共に自動的にスケーリングするストレージサービスです。異なるアプリケーションは永続性、可用性、遅延、パフォーマンスなどに対して異なる要求を持つ可能性があるため、臨時と永続化の 2 種類の Serverless ストレージオプションが必要になる可能性があります
細粒度調整が不足
ステートフルなアプリケーションをサポートするために、Serverless フレームワークはマルチタスクを調整する方式を提供する必要があります。例えば、A タスクが B タスクの出力を使用する場合、A は入力準備ができた時を知る方法が必要です。A と B が異なるノード上にある場合でも。多くのデータ一貫性を保証するプロトコルも同様の調整メカニズムを必要とします
既存のクラウドストレージサービスはすべて通知能力がなく、クラウドプロバイダーは独立した通知サービス(例えば SNS、SQS)を提供しますが、非常に高い遅延(時々数百 ms)が存在し、細粒度調整の使用コストも非常に高いです。いくつかの関連改善研究(例えば Pocket)がありますが、まだクラウドプロバイダーに採用されていません
したがって、アプリケーションは通知能力を持つ VM ベースのシステム(例えば ElastiCache、SAND)を管理するか、または自分の通知メカニズムを実装する必要があります。例えばクラウド関数間が長期実行されている VM ベースのランデブーサーバー(rendezvous server)を通じて通信するように。この制限はいくつかの新しい Serverless 変体の探索を引き起こしました。例えば名前付き関数インスタンスは直接アドレッシングを通じてその内部状態にアクセスすることを許可します(例えば Actors as a Service)
標準通信モード下でパフォーマンスが非常に悪い
ブロードキャスト(broadcast)、集約(aggregation)、shuffle メカニズムなどの分散システム中の一般的な通信モードはクラウド関数環境で複雑さが急増します:
[caption id="attachment_2051" align="alignnone" width="1004"]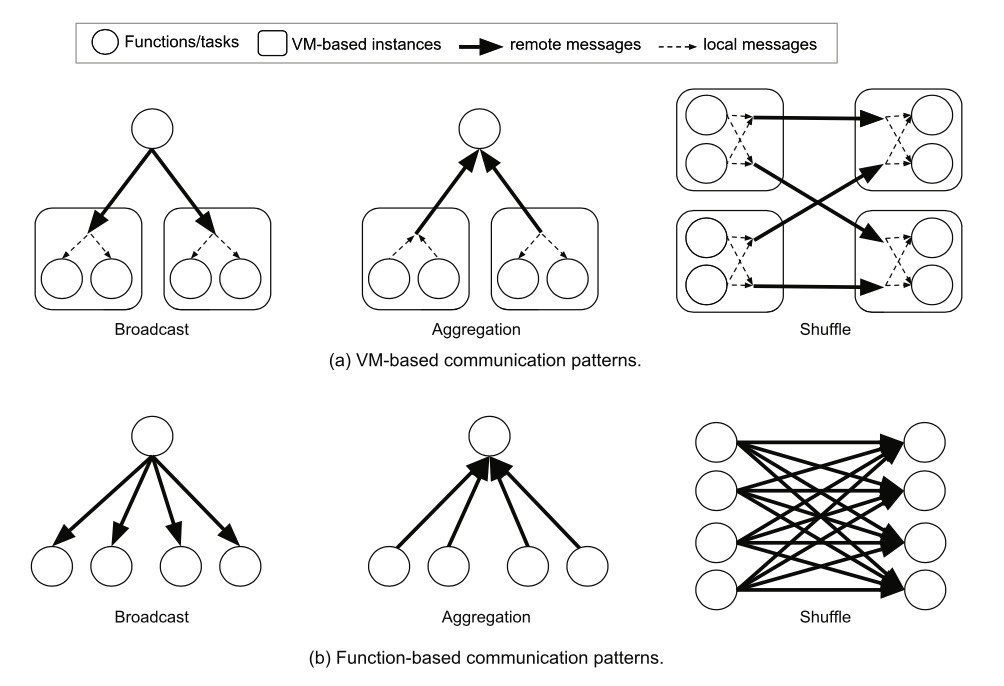 communication patterns for distributed applications[/caption]
communication patterns for distributed applications[/caption]
その理由は VM インスタンスはデータを送信する前とデータを受信した後にタスク間でデータを共有、集約またはマージする機会があるが、Serverless 下ではないからです
具体的に、VM ベースの方案では、同一インスタンス上で実行されているすべてのタスクはブロードキャストを通じて伝送されたデータを共有でき、または其它のインスタンスに部分結果を送信する前にローカル集約を行えます。したがって、ブロードキャストと集約の通信複雑さは O(N) で、N はシステム中の VM インスタンスの数量です。一方クラウド関数環境では、通信複雑さは O(N × K) で、K は各 VM 上の関数数量です
shuffle メカニズム下ではこの差異はさらに大きく、VM ベースの方案ではすべてのローカルタスクはデータを一緒にマージできるため、2 つの VM 間では 1 つのメッセージのみを伝送する必要があります。送信側と受信側数量が等しいと仮定すると、N^2 条のメッセージを送信する必要がありますが、クラウド関数方案下では (N × K)^2 条のメッセージを送信する必要があります。クラウド関数が持つ CPU コア数量は VM よりもはるかに少ないため、K は通常 10 から 100 で、さらにアプリケーションはクラウド関数の位置を制御できないため、実際には等效の VM 方案より 2 から 4 桁多くのデータを送信する可能性があります
P.S.これらの通信モードは多く機械学習と大データ分析アプリケーション中で使用されます
パフォーマンスが予測不可能
コールドスタート遅延に影響する要因は 3 点あります:
-
クラウド関数を起動するために必要な時間
-
その関数に必要なソフトウェア環境を初期化する時間、例えば Python ライブラリをロード
-
ユーザーコード中の特定アプリケーション初期化の時間
後者 2 つのオーバーヘッドと比較して、前者はあまり問題ではありません。例えばクラウド関数を起動するには 1 秒しかかかりませんが、すべてのアプリケーションライブラリをロードするには数十秒かかる可能性があります
もう一つの阻害要因はハードウェアリソースの変動性です。*クラウドプロバイダーは底辺サーバーを柔軟に選択できる(甚至異なる時代の CPU に遭遇する可能性がある)*ためです。この問題に対して、クラウドプロバイダーはリソースを最大限に利用することとパフォーマンス予測可能性の間でバランスを取る必要があります
六.理想的な Serverless Computing
より多くのアプリケーションが Serverless の恩恵を受けるためには、主に抽象、システム、ネットワーク、セキュリティ、アーキテクチャなどの方面の挑戦に直面しています
抽象
リソースニーズ
開発者はクラウド関数のメモリサイズと実行時間のみを制限でき、CPU、GPU または其它のタイプのアクセラレータなどの其它のリソースニーズを制御できません
一つの方式は開発者にこれらのリソースニーズを明示的に指定させることですが、クラウドプロバイダーが統計的复用を通じて高利用率を実現することをより難しくします。クラウド関数スケジューリングにさらに多くの制約を課すためです。しかも Serverless 精神に反します。クラウドアプリケーション開発者のリソース管理負担を増加させるためです
もう一つのより良い選択は抽象レベルを向上させることで、クラウドプロバイダーがリソースニーズを推論し、開発者が指定しないようにします。例えばクラウドプロバイダーは静的コード分析、上一次実行状況の分析またはソースコードの動的コンパイルを通じて実現できます。適切なメモリを自動的にプロビジョニングするのは魅力的に聞こえますが、挑戦に満ちています。特に高級言語が自動ガベージコレクションメカニズムを持つ場合、いくつかの研究はこれらの言語ランタイムは Serverless プラットフォームと統合されるべきだと提案しています
データ依存
現在のクラウド関数プラットフォームは 2 つのクラウド関数間のデータ依存関係を知りません。これらの関数間で大量のデータを交換する必要がある可能性があります。さらに理想的でないノード分布を引き起こし、より非効率的な通信モードを引き起こす可能性があります
一つの解決策はクラウドプロバイダーがアプリケーションにその計算グラフを指定できる API を公開し、より良いノード分布決定をサポートし、通信を最低限に抑え、进而パフォーマンスを向上させることです。実際、多くの汎用分散フレームワーク(例えば MapReduce、Apache Spark、Apache Beam/Cloud Dataflow)、並列 SQL エンジン(例えば BigQuery, Azure Cosmos DB)およびオーケストレーションフレームワーク(例えば Apache Airflow)はすでに内部でこのような計算グラフを生成しています。原則的に、これらのシステムは改造を通じてクラウド関数環境で実行でき、計算グラフをクラウドプロバイダーに公開できます
P.S.AWS Step Functions はすでにこれを行っており、ステートマシン言語と API を提供しています
システム
高性能、プロビジョニング透明かつ経済的なストレージ
臨時と永続化の 2 種類のストレージニーズに対して、臨時ストレージは主にクラウド関数間で状態を伝達する時の速度と遅延問題を解決するために使用されます
臨時ストレージを提供する一つの方案は最適化されたネットワークスタックを持つ分散メモリサービスを構築し、マイクロ秒級遅延を保証することです。オペレーティングシステムがプロセスに透明なメモリプロビジョニングを提供するように、自動的にスケーリングし、アプリケーションライフサイクルと共に作成/解放し、セキュリティ隔離も提供する必要があります。但目前 RAMCloud、FaRM は低遅延と高 IOPS を保証できますが、マルチテナント隔離を提供しておらず、Pocket は自動的にスケーリングできず、ストレージを事前に割り当てる必要があります
しかも、統計的复用を通じて、臨時ストレージは現在の Serverful モードメモリ効率よりも高く、VM インスタンス中アプリケーションが使い切れないその部分のメモリも利用できます
OLTP(On-Line Transaction Processing)などのデータベース機能はますます BaaS 形式で提供される可能性がありますが、Serverless アプリケーションよりも長い永続化ストレージを必要とするアプリケーションに対して、高性能な Serverless 永続ストレージも実装すべきです
永続化ストレージに対して、SSD ベースの分散ストレージを利用して分散メモリキャッシュで補完できます。例えば Anna KV データベースは、複数の既存のクラウドストレージサービスを結合することで高コストパフォーマンスと高性能を実現しますが、この設計の鍵点是如何に大量尾部アクセス分布の状況下で低尾部遅延(tail latency)を実現することです。此时メモリキャッシュ能力は SSD 能力よりもはるかに低い可能性があります。さらに、マイクロ秒級アクセス時間を実現することが期待される新しいストレージ技術を利用することも可能な解決策です
Serverless 臨時ストレージと同様に、永続化ストレージサービスもプロビジョニング透明、セキュリティ隔離であるべきです。異なるのは、Serverless 永続化ストレージは明示的にリソースを解放するのみで、伝統的ストレージシステムと同じです。もちろん、永続性を保証する必要があり、書き込まれたいかなるデータも障害中で保留できる必要があります
調整/シグナルサービス
クラウド関数間は通常生産者 - 消費者モードを使用して状態を共有し、消費者は生産者のデータが利用可能になったことを即座に知る必要があります
同様に、ある関数は某种の条件を満たす時に別の関数にシグナルを送信する必要があるか、または複数の関数も協力して作業したい可能性があります。例えばデータ一貫性メカニズムを実装します。此类シグナルシステムはマイクロ秒級遅延、信頼できる伝送およびブロードキャストまたはグループ通信から恩恵を受けます。しかもクラウド関数インスタンスは個別にアドレッシングできないため、教科書的な分散システムアルゴリズム(例えば consensus または leader election)を実装するために使用できません
起動時間を最小化
起動時間は 3 部分に分かれます:
-
クラウド関数関連リソースをスケジューリングおよび起動して実行
-
クラウド関数コードを実行するために必要なアプリケーションソフトウェア環境(例えばオペレーティングシステム、ライブラリ)をダウンロード
-
アプリケーションの特定起動タスクを実行、例えばデータ構造およびライブラリをロードおよび初期化
リソーススケジューリングと初期化および VPC と IAM ポリシーの構成は大きな遅延とオーバーヘッドを引き起こします。クラウドプロバイダーは近期軽量級隔離メカニズムを開発することで起動時間を短縮することに焦点を当てています
一つの辦法は単一コアを利用してオーバーヘッドを節約することです:
-
伝統的オペレーティングシステムのようにハードウェアを動的に検出、ユーザー構成を適用、データ構造を割り当てるのではなく、ハードウェアを事前構成し、データ構造を静的に割り当てることでこれらのコストを圧縮
-
さらに、単一コアはアプリケーションに必要なドライブとシステムライブラリのみを含み、伝統的オペレーティングシステム空間占有よりもはるかに低い
しかし単一コアは特定アプリケーション向けにカスタマイズされており、複数の標準カーネルをリアルタイムで実行する時、さらに効率的な向上を実現できない可能性があります。例えば同一 VM 中の異なるクラウド関数時カーネルコードページングを共有できないか、またはプリキャッシュを通じて起動時間を短縮できません
もう一つの方法はアプリケーション実際に呼び出す時に動的に増分的にライブラリをロードすることです。例えば Azure Functions 中の共有ファイルシステム
特定アプリケーション初期化は開発者が責任を持ちますが、クラウドプロバイダーはその API 中で準備完了シグナルを提供し、クラウド関数を过早に呼び出すことを回避できます。さらに、クラウドプロバイダーは起動タスクを事前に実行できます。特に顧客無関のタスク(例えば VM と人気オペレーティングシステムおよび関連ライブラリを起動)に適用されます。マルチテナント間でホットインスタンスプール(warm pool)を共有できるためです
ネットワーク
前面で言及したように、ブロードキャスト、調整、shuffle などの人気通信メカニズムはクラウド関数環境で深刻なオーバーヘッドをもたらします。例えば K 個のクラウド関数を 1 つの VM インスタンスにパッケージングすると、クラウド関数版は VM 版より K 回(甚至更多)多くのメッセージを送信し、shuffle シーンでは甚至 K^2 回のメッセージ通信が必要です
この問題を解決する 3 つの方式があります:
-
クラウド関数にマルチコアを提供し、VM インスタンスに類似し、こうすれば複数のタスクはデータを送信する前またはデータを受信した後にマージ/共有データできます
-
開発者に一部のクラウド関数を同一 VM インスタンス上に明示的に配置することを許可し、アプリケーションに箱から出してすぐに使える分散通信メカニズムを提供し、クラウドプロバイダーがクラウド関数を同一 VM インスタンスに割り当てることを可能に
-
アプリケーションに計算グラフを提供させ、クラウドプロバイダーに関連クラウド関数を同一 VM インスタンスに割り当て(co-locate)、通信オーバーヘッドを最小限に抑えることを可能に
しかし前 2 つの方式はクラウドプロバイダーがクラウド関数を割り当てる柔軟性を低下させ、データセンターの利用率を低下させます。しかも Serverless Computing 精神に反します。クラウド開発者にシステム管理を考慮させることを強制するためです
セキュリティ
Serverless は以前の安全责任划分を乱し、多くの責任をクラウドユーザーからクラウドプロバイダーに移転しましたが、それらを根本的に変更したわけではありません。しかし、Serverless はアプリケーション間マルチテナントリソース共有の固有リスクにも対処する必要があります
ランダムスケジューリングと物理隔離
物理的共同駐在(co-residency)はクラウド環境下でハードウェアレベルのサイドチャネルと Rowhammer 攻撃の鍵で、此类攻撃はまず被害者と同一物理ホスト上にある必要があります
クラウド関数の短命性能はある程度攻撃者が並行実行されている被害者を識別する能力を制限できます。ランダムまたは敵対者感知(adversary-aware)スケジューリングアルゴリズムは攻撃者と被害者が同一ホストにあるリスクを低下させ、物理的共同駐在攻撃をより困難にします。しかしこれらの安全措置は割り当て(VM)方式の起動時間、リソース利用と通信最適化と衝突する可能性があります
細粒度の安全環境
クラウド関数は細粒度構成を必要とし、秘密鍵、ストレージオブジェクトおよびローカル臨時リソースへのアクセスを含みます。既存の Serverful アプリケーションからセキュリティポリシーを変換し、クラウド関数中の動的使用のために(これらのポリシーを)十分に表現できるセキュリティ API を提供する必要があります。例えば、クラウド関数はいくつかのセキュリティ特権を別のクラウド関数またはクラウドサービスに委譲する必要がある可能性があります
暗号化保護された安全環境中、機能に基づくアクセス制御メカニズムは此类分散セキュリティモデルの自然な選択である可能性があります。多方設定中で情報フロー制御を使用してクロス関数アクセス制御を行うことを提案します。例えばクラウド関数のために短期鍵と証明書を動的に作成しますが、セキュリティメカニズム分散管理上の其它問題(例えば不对等と証明書失効)は悪化します
システムレベルから見ると、ユーザーは関数レベルの細粒度セキュリティ隔離を必要とし、少なくともオプションとして。関数レベルサンドボックスを提供する難点は较短い起動時間を保証することで、重複関数呼び出しに対して実行環境を共有状態的方式でキャッシュしないことです。ローカルインスタンススナップショットを通じて、各関数がクリーンな状態から開始できるようにするか、または軽量級仮想化技術(例えばライブラリオペレーティングシステム、単一コア、マイクロ VM など)を採用し、起動時間を数十ミリ秒まで短縮できますが、その安全性が伝統的 VM の程度に達せるかは不明です。積極的な面は、Serverless 中のプロバイダー管理と短期インスタンスはより迅速に脆弱性を修正できることです
物理的共同駐在攻撃���防護したいユーザーにとって、一つの解決策は物理隔離を要求することです。クラウドプロバイダーは顧客に高級オプションを提供し、専用物理ホスト上でクラウド関数を起動できます
曖昧な Serverless
クラウド関数は通信中でアクセスパターン(access patterns)とタイミング情報(timing information)を漏洩する可能性があります
serverful アプリケーションに対して、通常データをバッチで取得し、ローカルにキャッシュします。クラウド関数は短命で、クラウド環境中で広く分布しているため、ネットワーク伝送モードは機密情報(例えば自社従業員)を漏洩する可能性があります。データがエンドツーエンドで暗号化されていても、Serverless アプリケーションを多くの小関数に分解する傾向はこの安全隐患を悪化させます。主要なセキュリティ問題は外部攻撃者から来ますが、従業員からの攻撃も曖昧アルゴリズムを通じて防護できます。しかし、このようにするオーバーヘッドは通常非常に高いです
アーキテクチャ
ハードウェア異質性、価格設定および管理のしやすさ
クラウドコンピューティング中で支配的な x86 マイクロプロセッサはパフォーマンス上でほとんど向上していません(2017 年単一プログラムパフォーマンス向上は僅か 3%)。この傾向が続く場合、20 年以内にパフォーマンスは倍増できません。同様に、チップ当たりの DRAM 容量もすでに限界に近づいており、現在販売中の 16Gbit DRAM がありますが、32G DRAM のチップを製造できないようです。唯一慰められるのは、この亀の歩みような変化はサプライヤーが古いマシンが損耗する時に余裕を持って交換でき、Serverless 市場にはほとんど影響がないことです
汎用マイクロプロセッサのパフォーマンス問題はより高速な計算に対するニーズを減少させません。2 つの方向があります。高級スクリプト言語(例えば JavaScript または Python)で書かれた関数に対して、ハードウェアとソフトウェアの共同設計を通じて言語特定のカスタムプロセッサを生成でき、その実行速度は 1 から 3 桁速くなります。もう一つの方向は*特定分野アーキテクチャ(DSA、Domain Specific Architectures)*です。DSA は特定問題分野向けにカスタマイズでき、該分野に対して顕著なパフォーマンスと効率向上がありますが、其它分野ではパフォーマンスが良くありません。グラフィック処理ユニット(GPU、Graphical Processing Units)は長らくグラフィック処理を加速するために使用されてきました。機械学習分野の DSA も見始めています。例えばテンソル処理ユニット(TPU、Tensor Processing Units)で、TPU は CPU より 30 倍速くなります。これは多くの实例中の一例で、DSA を使用して単独分野向けの汎用プロセッサを強化することが常態になります
ハードウェア異質性に対して、同様に 2 つの方向があります:
-
Serverless クラウドは多種のインスタンスタイプを含み、価格設定は使用された具体的なハードウェアに依存
-
クラウドプロバイダーは言語に基づくアクセラレータと DSA を自動的に選択可能。この自動化はクラウド関数が使用するソフトウェアライブラリまたは言語に基づいて暗黙的に完了できます。例えば CUDA コードは GPU を使用し、TensorFlow コードは TPU を使用。または、クラウドプロバイダーはクラウド関数のパフォーマンスを監視し、次回実行時にそれらをより適切なハードウェアに移行できます
x86 の SIMD 命令に対して、Serverless は異質性に直面しています。AMD と Intel は各クロックサイクルで実行される操作数を増加し、新規命令を追加することで、x86 命令集中のこの部分を迅速に改善しています。SIMD 命令を使用するアプリケーションに対して、最近の Intel Skylake マイクロプロセッサ(512 ビット幅 SIMD 命令)上で実行するのは古い Intel Broadwell マイクロプロセッサ(128 ビット幅 SIMD 命令)上で実行するよりもはるかに速いです。現在 AWS Lambda 中これら 2 種類のマイクロプロセッサは同じ価格で供給されていますが、Serverless ユーザーはより速い SIMD ハードウェアを使用したいことを表明する方法がありません。私たち看来、コンパイラーは哪种のハードウェアが最も適切かの建議を提供すべきです
アクセラレータがクラウド環境中でますます普及するにつれ、Serverless クラウドプロバイダーは異質性の困境を無視できなくなります。特に合理的な救済措置が存在するためです
七.Serverless に対する 6 つの誤解
クラウド関数は毎分の価格がより高いため、Serverless は Serverful より高価
Serverless の価格設定は単にリソースインスタンスではなく、可用性冗長、監視、ログ記録およびスケーリングなどのすべてのシステム管理機能を含むためです。しかも、Serverless スケーリング粒度はより精細で、実際に使用される計算量はより効率的である可能性があります。より重要なのは、Serverless はクラウド関数を呼び出さない時支払い不要のため、Serverful よりもはるかに安くなる可能性があります
Serverless は予測不可能なコストを生み出す可能性がある
某些のユーザーにとって、即時使用即時支払いはコストが予測不可能であることを意味し、これは多くの組織の予算管理方式と矛盾します。例えば予算承認時に未来 1 年間の Serverless サービスコストを知りたい。クラウドプロバイダーはパッケージ価格設定(bucket-based pricing)を提供することでこのニーズを緩和できます。電話会社が特定使用量に対して固定レートパッケージを提供するように、甚至 Serverless 普及後、歴史状況に基づいて Serverless サービスコストを予測できます
Serverless は Python などの高級言語を使用してプログラミングするため、異なる Serverless プラットフォームに簡単に移植可能
異なるプラットフォーム下では、関数呼び出し、パッケージング方式が異なるだけでなく、多くの Serverless アプリケーションは標準化されていない BaaS 製品/サービスエコシステム(例えばオブジェクトストレージ、KV データベース、ログと監視など、移植性を実現するため)に依存しています。標準化 API を形成する必要があります。例えば Google の Knative プロジェクトはこの方向に探索しています
Serverless 下では、サプライヤー绑定(vendor lock-in)程度がより強い
アプリケーション移植が困難であればサプライヤーとの強绑定が存在しますが、フレームワークが提供するクロスクラウドサポートはこの強绑定を緩和できます
クラウド関数は極めて低い遅延パフォーマンス要求を持つアプリケーションに対処できない
Serverful インスタンスは此类シーンに対処できるのはそれらが常に実行され���いるためで、リクエストを受信した後に迅速に応答できます。しかしクラウド関数の起動遅延がアプリケーションにとって満足できない場合、いくつかの戦略を採用して緩和できます。例えば定期的にクラウド関数を実行することでウォームアップ
所謂弾力的サービスは Serverless の実際の柔軟性要求を満たせるものは少ない
「弾力的」(elastic)は Serverless 中では容量を迅速に変更でき、ユーザー介入越少越好で、使用しない時に 0 まで縮小できることを指します。クラウドプロバイダーが提供するものは通常有限弾力性(例えば Redis インスタンスを整数個のみインスタンス化可能、容量を明示的に構成する必要あり、甚至数分間需要変化に応答する必要あり)のみで、これらの要求に達しておらず、したがって多くの Serverless 優位性を失っています
明確な技術定義と指標がないため、「弾力的」という言葉は曖昧不清です
八.まとめと予測
簡素化されたプログラミング環境を提供することで、Serverless はクラウドをより使いやすくし、さらに多くのユーザーを惹きつけます。Serverless は FaaS と BaaS 製品を含み、クラウドプログラミングの重要な成熟を表します。現在 Serverful がアプリケーション開発者にもたらす手動管理とリソース最適化の負担を省きます。この成熟は 40 多年前にアセンブリ言語から高級言語へ向かったのと同じです
Serverless のアプリケーションは暴増すると予測され、ハイブリッドクラウドローカルアプリケーションはますます少なくなります。某些のデプロイメントは法規制約とデータ管制規則により現状を維持する可能性があります
すでに一定の成功を収めていますが、まだ多くの挑戦が存在します。これらの問題を克服できれば、Serverless をより広範なアプリケーション中で普及させられます。第一歩は Serverless 臨時ストレージで、合理的なコストで低遅延、高 IOPS(の臨時ストレージサービス)を提供する必要がありますが、経済的な長期ストレージを提供する必要はありません。第二类アプリケーションは Serverless 永続ストレージから恩恵を受けます。それらは確かに長期ストレージを必要とするためです。新しい不揮発性メモリス technology は此类ストレージシステムに役立つ可能性があります。其它アプリケーションは低遅延のシグナルサービスおよび人気通信メカニズムのサポートから恩恵を受けます
Serverless 未来の 2 つの重大な挑戦はセキュリティを向上させ、専用プロセッサから来る可能性のあるコストパフォーマンス改善に適応することです。Serverless がすでに持っているいくつかの特性はこれらの挑戦に対処するのに役立ちます。例えば:
-
物理的共同駐在はサイドチャネル攻撃の必要条件で、Serverless 中では(同一物理マシン上にあるかどうか)を確認するのが難しく、防護措置を講じるのも容易です。例えばクラウド関数をランダムに分布
-
高級言語(例えば JavaScript、Python または TensorFlow)でプログラミングするクラウド関数は、プログラミング抽象レベルを向上させ、底辺ハードウェアイノベーションにより有利です
最後に、Serverless Computing が次の 10 年間で:
-
新しい BaaS ストレージサービスが出現し、より多くのタイプのアプリケーションが Serverless 下で実行できるようになります。此类ストレージはローカルデータブロックストレージのパフォーマンスに達し、臨時的と永続化的の 2 種類に分かれます。伝統的 x86 マイクロプロセッサと比較して、serverless 下コンピューターハードウェアの異質性ははるかに大きいです
-
serverful よりセキュリティプログラミングが容易になります。高級プログラミング抽象、およびクラウド関数の細粒度隔離のおかげです
-
Serverless の課金モデルは改善されます。そのコストが serverful より高い理由がないためです。したがって 绝大多数のいかなる規模で実行されるアプリケーションも Serverless 下でコストは高くなく、甚至低くなります
-
Serverful は BaaS サービスを促進するために使用されます。Serverless 上で実装するのが困難なアプリケーション(例えば OLTP データベースまたはキューなどの通信メカニズムなど)は、クラウドプロバイダーサービスセットの一部として提供される可能性があります
-
serverful は消失しませんが、その重要性は Serverless が現在の制限を突破するにつれて徐々に低下します
-
Serverless はクラウド時代のデフォルト計算モードになり、很大程度上で serverful を取代し、Client-Server 時代を終了させます
コメントはまだありません