一.ネットワークの信頼性から語る
マシン間は物理接続(ケーブル、電話線、電波、衛星、赤外線ビームなど)を通じて信号を伝達し、情報交換を行うことができます:
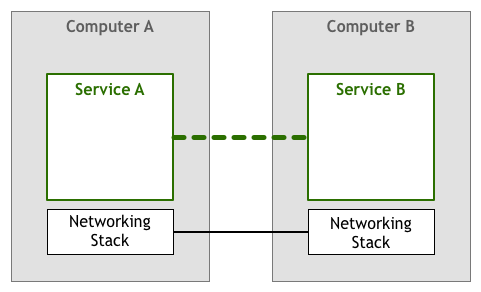
しかし、データ伝送中にはいくつかの異常状況が発生する可能性があります。例えば:
-
データ損失:データパケットはバッファがすでにいっぱいのルーターに到達し、捨てられる可能性があります
-
順序エラー:一組のデータパケットは閑忙度の異なる複数のルーターを経由し、不同程度的な遅延が発生し、最後に到達する順序は送信時の順序と一致しない可能性があります
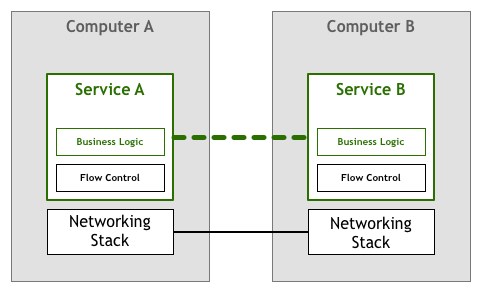
したがって、少なくともパケット損失再送信、順序再構成などの制御機制が必要です。早期にはこの部分の作業はネットワークサービス/アプリケーションによって完了されました(アプリケーション層でビジネスロジックと共存):
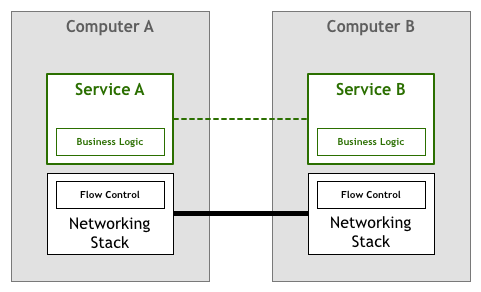
後に、この部分の作業はネットワークスタック(オペレーティングシステムのネットワーク層)に下沉し、TCP/IP などの標準ネットワークプロトコルによってデータ伝送の信頼性が保証されました(下図の太い線):
二.マイクロサービスアーキテクチャ下の信頼性課題
ネットワークプロトコルが提供する信頼性保証は小型の多マシン相互接続シーンにとっては十分ですが、大規模な分散型シーン(例:マイクロサービ���アーキテクチャ)では、全体の信頼性を保証するためにより多くの機制を導入する必要があります。例えば:
-
Service Discovery 機制:サービス登録照会機制を通じて、1 つのマイクロサービスが別のマイクロサービスを見つけることを可能にし、それによって動的スケーリング、および障害転送を許可
-
遮断機制(Circuit Breaker pattern):遮断保護を提供(電表のブレーカー落下のよう)、あるサービスが使用不可になることで連鎖故障を引き起こすのを防止。例えば操作が成功しないことで狂ったように再試行し、リクエストが堆積し、さらに関連リソースを使い果たし、システム中の無関係な部分もこれによって故障する
同様に、この部分の作業も早期にはマイクロサービスによって完了されました(マイクロサービス内でビジネスロジックと共存):
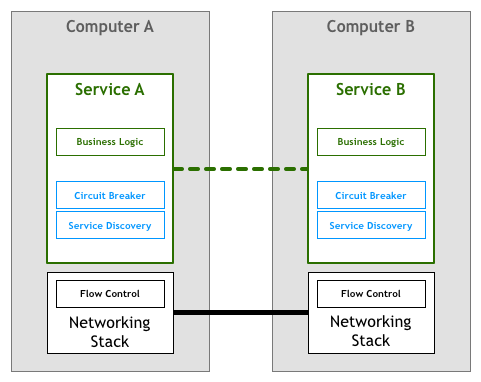
続いて Finagle、Proxygen などのオープンソースライブラリが現れ、専門のライブラリによってこれらの作業を完了し、各サービスで同じ制御ロジックを繰り返す必要がなくなりました:
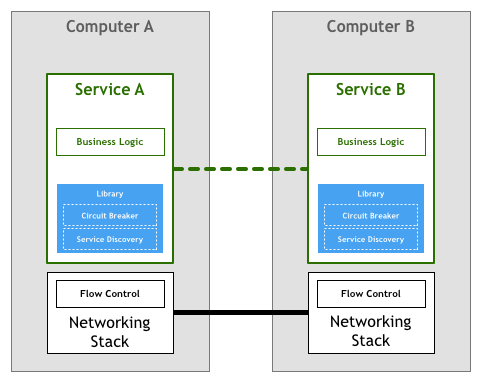
しかし、システム中のサービス数の増加に伴い、この方式もいくつかの問題を露呈しました:
-
糊部分のリソース投入:サードパーティライブラリをシステムの残りの部分と接続するためにリソースを投入する必要がある
-
ライブラリがマイクロサービスの技術選択を制限:これらのライブラリは通常プラットフォーム固有で、特定のランタイムまたはプログラミング言語のみをサポートし、マイクロサービスの技術選択に制限をもたらす。畢竟、マイクロサービスの大きな特徴の 1 つは 異なるプログラミング言語を使用して異なるサービスを作成することを許可 すること
-
ライブラリの維持コスト:ライブラリ自体も継続的な維持アップグレードが必要で、更新のたびにすべてのサービスを再デプロイする必要がある。サービスに何の変更もない場合でも
このように見ると、ライブラリは理想的な解決策ではないようだ
三.マイクロサービス制御をネットワークスタックに下沉?
アプリケーション層で解決するのが適切でないなら、同じようにネットワークスタックに下沉できるだろうか?
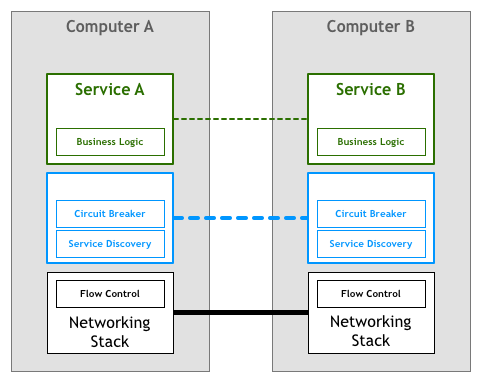
一般的な基礎通信機制とは異なり、これらのアプリケーションサービス関連の制御機制を下層ネットワークスタックに実装させるのは非常に困難で、そのまま下沉するのは通じない
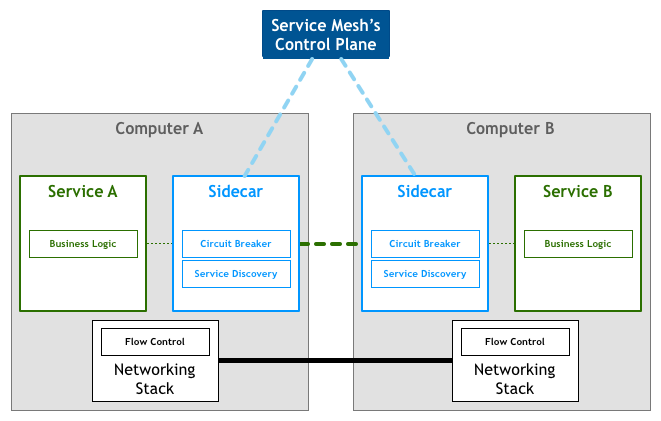
Sidecar
(サービス)内部でも、下でもないので、最後に横に置かれた:
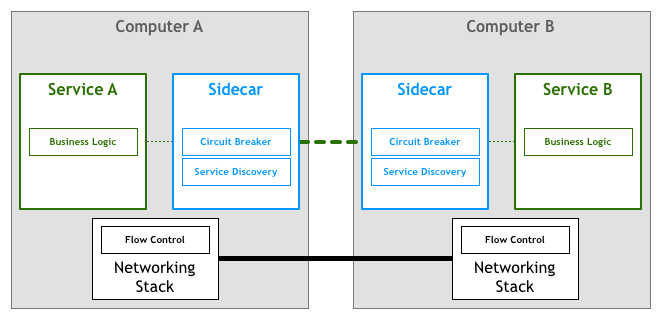
つまり、プロキシを通じてこれらのネットワーク制御を実現し、すべての出入トラフィックがプロキシを経由する。これを Sidecar と呼ぶ:

Sidecar は補助プロセスとして、アプリケーションと一緒に実行され、追加機能を提供
問題はネットワークプロキシを通じて完璧に解決されたように見え、業界にもいくつかのオープンソース方案が現れた:
しかし、これらの方案はすべて特定の基礎コンポーネント上に構築されており、例えば Nerve と Synapse は Zookeeper に基づき、Prana は Eureka に基づき、異なる基礎コンポーネントに適応できない
では、十分に柔軟で、基礎コンポーネントに依存しない解決策はあるだろうか?
ある。Service Mesh と呼ぶ
四.Sidecar から Service Mesh へ
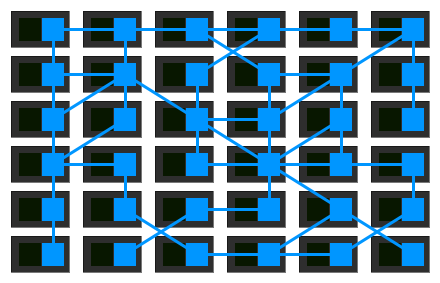
各サービスにプロキシ Sidecar を 1 つ配套し、サービス間はプロキシを通じてのみ相互通信すると、最終的にこのようなデプロイモデルが得られる:
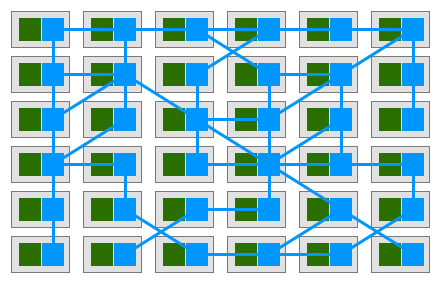
つまり、プロキシ間が相互に接続して網状のグリッドを形成し、これを Service Mesh(サービスグリッド)と呼ぶ:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It's responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application.
サービス間通信を処理するための専用インフラストラクチャ層。現代のクラウドネイティブアプリケーションを構成する複雑なサービストポロジを通じてリクエストの信頼性の高い配信を担当
具体的には、Service Mesh は Service Discovery、負荷分散、暗号化、観測/追跡、認証および認可、および遮断機制などのサポートを提供できる:
The mesh provides critical capabilities including service discovery, load balancing, encryption, observability, traceability, authentication and authorization, and support for the circuit breaker pattern.
Sidecar から Service Mesh へ、鍵はより高い視点でこれらのプロキシを捉え、それらが形成するネットワークが持つ価値を発見すること:
五.Service Mesh + デプロイプラットフォーム
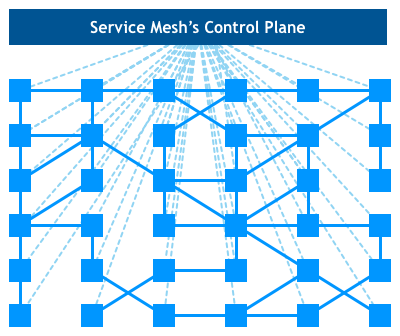
続いて、Service Mesh は自然に(Service を掌握する)デプロイプラットフォームと火花を散らした(例:Istio + Kubernetes)、さらに制御層(Control Plane)を派生し、このインフラストラクチャ層を設定可能にした:
最終的に制御層 + データ層の上下構造を形成:

その中で、インスタンス間のネットワークトラフィックを管理する部分をデータ層(Data Plane)と呼び、データ層の動作は制御層(Control Plane)が生成する設定項目によって制御され、制御層は通常 API、CLI および GUI などの多种方式でアプリケーションを管理
つまり:
コメントはまだありません