はじめに
私たちは、巨大で、高速で、かつ安価なストレージを同時に所有することはできません。そのため、さまざまなトレードオフの産物が生まれました:
-
CPUレジスタ:非常に高速ですが、安価でも巨大でもありません
-
RAM:それほど高速ではなく巨大でもありませんが、比較的安価です
-
ハードディスク:非常に安価で大容量ですが、読み書きが低速です
そして最終的に、以下のような階層構造が形成されました:

同様に、システム設計においても多くのトレードオフ(権衡取捨)に直面します:
-
パフォーマンスとスケーラビリティ
-
レイテンシとスループット
-
可用性と一貫性
1. パフォーマンスとスケーラビリティ
スケーラブルであるということは、リソースを追加することでパフォーマンスを比例的に向上させることができることを意味します:
A service is scalable if it results in increased performance in a manner proportional to resources added.
パフォーマンスの向上は、より多くのワークロードを引き受けられること、またはより大規模で重いタスク(データ量の増加など)を処理できることに現れます。
P.S. もちろん、リソースの追加は、冗長性の導入など、サービスの信頼性を高めるためである場合もあります。
しかし、リソースの追加は多様性も導入します。一部のノードは他のノードよりも処理能力が高いかもしれませんし、古いノードは処理能力が低いかもしれません。システムはこの不均一性(heterogeneity)に適応しなければならないため、均一性に依存するアルゴリズムは新しいノードを十分に活用できず、結果としてパフォーマンスに影響を及ぼします。
2. レイテンシとスループット
*レイテンシ(Latency)*とは、操作を実行してから結果が生成されるまでに必要な時間を指します:
Latency is the time required to perform some action or to produce some result.
その測定単位は時間であり、秒(seconds)、ナノ秒(nanoseconds)、システムクロックサイクル数(clock periods)などが用いられます。
*スループット(Throughput)*とは、単位時間あたりに処理できる操作の数、または生成できる結果の数を指します:
Throughput is the number of such actions executed or results produced per unit of time.
単位時間あたりに生成されたものによって測定されます。例えば、メモリ帯域幅(memory bandwidth)はメモリシステムのスループットを測定するために使用されます。Webシステムの場合、以下のような測定単位があります:
-
QPS(Queries Per Second):情報検索システム(検索エンジン、データベースなど)における1秒あたりの検索トラフィックを測定するために使用されます。
-
RPS(Requests Per Second):リクエスト-レスポンスシステム(Webサーバーなど)が1秒間に処理できる最大リクエスト数です。
-
TPS(Transactions Per Second):広義には1秒間に実行できるアトミックな操作の数、狭義にはDBMSが1秒間に実行できるトランザクションの数を指します。
P.S. 通常、Webサービスのスループット測定にもQPSが使われますが、より正確な単位はRPSです。
同様に、低レイテンシと高スループットを両立させることはできないため、トレードオフにおける原則は以下のようになります:
Generally, you should strive for maximal throughput with acceptable latency.
レイテンシが許容範囲内であることを確保した上で、最大のスループットを追求します。
3. 可用性と一貫性
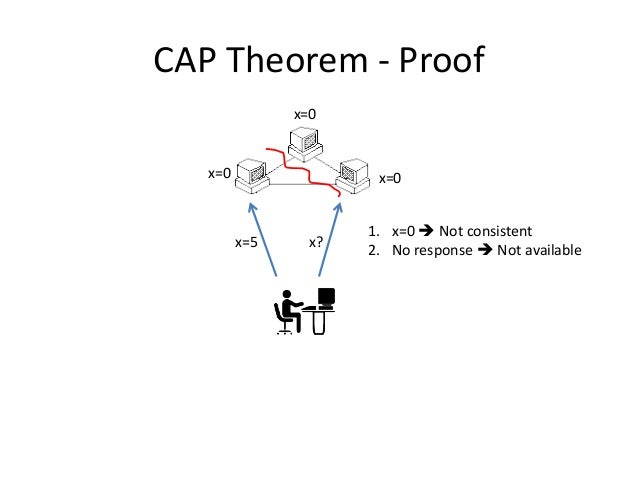
可用性と一貫性については、有名なCAP定理があります:
Of three properties of distributed data systems - consistency, availability, partition tolerance - choose two. —— Eric Brewer, CAP theorem, PODC 2000
分散コンピュータシステムにおいて、一貫性、可用性、パーティション耐性の3つのうち2つしか選ぶことができません(しかもパーティション耐性は必須です):
-
一貫性(Consistency):読み取りを行うたびに、最新の書き込み結果が得られるか、エラーが発生します。
-
可用性(Availability):すべてのリクエストが正常なレスポンスを受け取りますが、返される情報が最新であることは保証されません。
-
パーティション耐性(Partition Tolerance):ネットワーク障害によって一部がダウンしても、システムは実行を継続できます。
ネットワークは完全に信頼できるわけではないため、パーティション耐性を保証する必要があります(Pは必須)。一部のノードでネットワーク障害が発生したとき、2つの選択肢があります:
-
操作のキャンセル:一貫性を確保できますが、可用性が低下します(ユーザーがタイムアウトエラーを受け取る可能性があります)。これはCP(Consistency and Partition Tolerance)であり、アトミックな読み書きが必要なシーンに適しています。
-
操作の継続:可用性を保証しますが、一貫性のリスクがあります(返される情報が古い可能性があります)。これはAP(Availability and Partition Tolerance)であり、結果整合性(Eventual consistency)が許容されるシーンに適しています。
つまり、Pが満たされなければならないという前提のもと(ネットワーク障害はシステム外の制御不能な要因であり、選択の余地はありません)、CとAの間で取捨選択を行うしかありません。一貫性を保証する(可用性を犠牲にする)か、可用性を保証する(一貫性を犠牲にする)かのどちらかです。すなわち:
Possibility of Partitions => Not (C and A)
(10. Why do some people get annoyed when I characterise my system as CA? より引用)
P.S. もちろん、中央集権型システム(RDBMSなど)ではネットワークの信頼性の問題が存在しないため、この場合はCとAを両立させることができます。
4. 一貫性モデル
同一データに対して複数のコピーが存在する場合、その一貫性をどのように保証するかを検討する必要があります。厳格な一貫性とは、最新のデータを読み取るか、エラーが発生するかのどちらかを意味します。
しかし、すべてのシーンでこのような一貫性の要件を達成する必要があるわけではないため、弱一貫性や結果整合性などの妥協の産物が登場しました。
弱一貫性
書き込みが終わった後、必ずしも読み取れるとは限りません。
*弱一貫性モデル(Weak consistency)*は、VoIP、ビデオチャット、リアルタイムマルチプレイヤーゲームなどのリアルタイム性が求められるシーンに適しています。VoIPで回線が切断されて再接続した際、切断中の通話内容は受信されません。
結果整合性
書き込みが終わった後、データを非同期で複製し、最終的に読み取れることを保証します。
*結果整合性モデル(Eventual consistency)*は、DNSやメールなどの高可用性システムに適しています。
強一貫性
書き込みが終わった後、データを同期的に複製し、即座に読み取れるようにします。
*強一貫性モデル(Strong consistency)*は、ファイルシステムやRDBMSなど、トランザクションメカニズムが必要なシーンに適しています。
5. 可用性モデル
可用性の保証に関しては、主に2つの方法があります:フェイルオーバーとレプリケーション。
フェイルオーバー
ノードがダウンした際、迅速に別のノードで代用することで、ダウンタイムを短縮します。具体的には、2つのフェイルオーバーモードがあります:
-
アクティブ-パッシブ(主従フェイルオーバー):アクティブなサーバーのみがトラフィックを処理し、稼働中のアクティブサーバーと待機中のパッシブサーバーの間でハートビートパケットを送信します。ハートビートが途切れた場合、パッシブサーバーがアクティブサーバーのIPアドレスを引き継いでサービスを復旧させます。ダウンタイムの長さは、パッシブマシンがホットスタートかコールドスタートかによって決まります。
-
アクティブ-アクティブ(主主フェイルオーバー):両方のサーバーがトラフィックを処理し、負荷を共同で分担します。
アクティブ-パッシブモードでは、(切り替え時に)データ紛失のリスクがあり、どちらの方法であっても、フェイルオーバーはハードウェアリソースと複雑さを増大させます。
レプリケーション
主従レプリケーションと主主レプリケーションに分けられ、主にデータベースで使用されますが、ここでは詳細は割愛します。
可用性指標
可用性は通常、「9」の数で測定されます。これは、実行時間に対するサービス稼働時間の割合を表します。
3つの9は、可用性が99.9%であることを意味します:
| 期限 | ダウンタイムの上限 |
|---|---|
| 毎年 | 8時間45分57秒 |
| 毎月 | 43分49.7秒 |
| 毎週 | 10分4.8秒 |
| 毎日 | 1分26.4秒 |
4つの9は、99.99%の可用性です:
| 期限 | ダウンタイムの上限 |
|---|---|
| 毎年 | 52分35.7秒 |
| 毎月 | 4分23秒 |
| 毎週 | 1分5秒 |
| 毎日 | 8.6秒 |
特に、複数のコンポーネントで構成されるサービスの場合、全体の可用性はそれらが直列か並列かによって決まります:
// 直列
Availability (Total) = Availability (Foo) * Availability (Bar)
// 並列
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
可用性が100%に満たない2つのサービスを組み合わせる場合、直列であれば全体の可用性は低下し(99.9% * 99.9% = 99.8%)、並列であれば全体の可用性は向上します(1 - 0.1% * 0.1% = 99.9999%)。
コメントはまだありません