一.不変データ構造
データ構造が不変なので、増、削、改などの操作の結果は新しいデータ構造を再作成することしかできません。例えば:
reverse' xs
| length xs <= 1 = xs
| otherwise = last xs : (reverse' (init xs))
List を反転するのはトランプの山を逆順にするようなもので、一番下のカードを抜いて新しい山の上に置き、次に下から 2 番目をその下に置く……したがって、山の反転操作の結果は実際には新しい山を作り出すことです。新しい山は以前のカードで構成されていますが、元の山とは何の関係もなく、状態の破棄 に類似しています。元の山を直接捨てて、維持修正するのではなく、例えば(配列反転の一般的方法、JS で記述):
function swap(arr, from, to) {
let t = arr[from];
arr[from] = arr[to];
arr[to] = t;
}
function reverse(arr) {
for (let i = 0; i < arr.length / 2; i++) {
swap(arr, i, arr.length - 1 - i);
}
return arr;
}
データ構造が可変の場合、配列反転は n/2 回の要素交換で実現できます。両者の違いは、可変データ構造ではデータ構造を拡張可能な再利用コンテナと見なし、データ構造への操作はコンテナ内の値に対する増、削、改です。不変データ構造では、データ構造をデータ定数と見なし、拡張も再利用もできないため、データ構造への操作はよく似ているが少し異なるデータを再作成することに相当します。例えば swap:
swap _ _ [] = []
swap i j xs
| i == j = xs
| i > j = swap j i xs
| otherwise = (take i xs) ++ [xs !! j] ++ (sublist (i + 1) (j - 1) xs) ++ [xs !! i] ++ (drop (j + 1) xs)
where sublist _ _ [] = []
sublist a b xs
| a > b = []
| a == b = [xs !! a]
| otherwise = (drop a . take (b + 1)) xs
1 つの線が 2 つの点で 3 つの区間に分けられ、List 中の 2 つの要素を交換した結果は最初の区間に 2 つ目の点を併せ、中間の区間を併せ、さらに 1 つ目の点と最後の区間を併せることです
(一場関数型思考モードの洗礼 から抜粋)
対応する JS 記述は以下の通り(重要な部分のみ):
function swap(i, j, xs) {
return xs.slice(0, i).concat([xs[j]]).concat(xs.slice(i + 1, j)).concat([xs[i]]).concat(xs.slice(j + 1));
}
非常に面倒で、効率も高くありません。例えば木構造のシナリオでは、1 つのノードを変更するには新しい木を 1 本作成する必要があり、その隣のノードを変更するにはまた新しい木を 1 本作成する必要があります……単にすべてのノード値に +1 するだけで n 本の完全な木を作成する必要があります。実際、局所的な修正には木全体を再作成する必要はなく、完全な木が必要になるまで待ってから作成する方が合理的です。データ構造が不変な場合、これは実現できるでしょうか?
二.データ構造中を穿梭する
木
まず二分探索木を作成:
> let tree = fromList [7, 3, 1, 2, 6, 9, 8, 5]
> tree
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
(fromList および二分探索木の実装は [Monoid_Haskell ノート 9](/articles/monoid-haskell ノート 9/#articleHeader12) から)
木構造は以下の通り:
5
2
1
3
8
6
空
7
9
指定ノードを修正したい場合、2 つのものが必要です:位置インデックスと新しい値。位置インデックスはアクセスパスで表せます。例えば:
data Direction = L | R
type Path = [Direction]
したがって modify 関数のタイプは以下のようになるはずです:
modify :: Tree a -> Path -> Tree a -> Tree a
位置インデックスで目標ノードを見つけ、新しい値に置き換えるだけです。このように実装:
modify EmptyTree _ n = n
modify t [] n = n
modify (Node x l r) (d:ds) n
| d == L = Node x (modify l ds n) r
| d == R = Node x l (modify r ds n)
試遊してみましょう。3 を 4 に変更、アクセスパスは [L, R]:
> modify tree [L, R] (singleton 4)
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
予想通りです。3 を修正した後 1 も修正したい場合は?
3 を修正した後の完全な木を入力として、根ノードから 1 を見つけて 0 に変更できます:
> modify (modify tree [L, R] (singleton 4)) [L, L] (singleton 0)
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
使えますが、2 つの問題があります:
-
3を修正した後に生成される完全な木は余計 -
1は3の左兄弟で、根から再び探す必要はない
実際、私たちが望んでいるのは:
-
中間の余計な完全な木を生成せず、必要な時(例えば一連の修正操作の後)にのみ完全な木を生成
-
完全な木に注目せず、局所的な修正(左右兄弟、親級子級)を便利に行える
1 つの部分木に対して複数回修正を行い、修正完了後に完全な木を生成できるようにするには、どうすればよいでしょうか?
局所的な修正と同時にその構造コンテキスト情報を保持する必要があります。例えば右部分木を修正する場合、注目点は:
8
6
空
7
9
二分木の場合、構造コンテキスト情報は 2 つの部分で構成されます。親ノードと兄弟ノード:
-- 親ノード
5
-- 左兄弟
2
1
3
右部分木にこれら 2 つの情報を加えると、親ノードを根とする完全な部分木を得られます。同様に、親ノードにもその親ノードと兄弟ノードの情報があれば、さらに上に部分木を回復でき、根に到達した時に完全な木を得られます。実際、十分な構造コンテキスト情報を持っていれば、木中で上下左右任意に穿梭 でき、いつでも立ち止まって完全な木を再構築できます
まず構造コンテキスト情報を定義:
data DirectionWithContext a = LeftSibling a (Tree a) | RightSibling a (Tree a) deriving (Show, Eq)
type PathWithContext a = [DirectionWithContext a]
type TreeWithContext a = (Tree a, PathWithContext a)
LeftSibling a (Tree a) で構造コンテキスト情報を記録します。その中で a は親ノードの値を表し、Tree a は右兄弟を表します。これは上に部分木を回復するために必要な最小情報で、少しも余計ではありません。PathWithContext は以前の Path と類似し、同様にアクセスパスを表すために使用されますが、パスの各ステップは方向を記録するだけでなく、対応するコンテキスト情報(親ノードと兄弟ノードを含む)も記録します
次に「任意穿梭」を実装:
goLeft ((Node x l r), ps) = (l, ((LeftSibling x r) : ps))
goRight ((Node x l r), ps) = (r, ((RightSibling x l) : ps))
goUp (l, ((LeftSibling x r):ps)) = (Node x l r, ps)
goUp (r, ((RightSibling x l):ps)) = (Node x l r, ps)
2 歩歩いて試遊してみましょう。まだ以前のシナリオで、まず 3 を探し、次に 1 を探します。つまりまず左へ右へ、次に上へ、最後に左へ:
> let cTree = (tree, [])
> let focus = goLeft (goUp (goRight (goLeft cTree)))
> fst focus
Node 1 EmptyTree EmptyTree
> snd focus
[LeftSibling 2 (Node 3 EmptyTree EmptyTree),LeftSibling 5 (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))]
1 が所在する部分木を見つけ、完全なアクセスパス(5 の左兄弟 2 の左兄弟)を保持しています
完全な木を再構築したい場合、元の道を通って木の根まで戻るだけでよいです。このように:
backToRoot (t, []) = (t, [])
backToRoot t = backToRoot $ goUp t
検証:
> fst $ backToRoot focus
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
自由に穿梭でき、いつでも完全な木を再構築できるようになった後、modify は非常にシンプルになります:
modifyTreeWithContext (EmptyTree, ps) _ = (EmptyTree, ps)
modifyTreeWithContext ((Node x l r), ps) v = ((Node v l r), ps)
もう一度、まず 3 を 4 に変更し、次に 1 を 0 に変更:
> let modified = modifyTreeWithContext (goLeft (goUp (modifyTreeWithContext (goRight (goLeft cTree)) 4))) 0
> fst modified
Node 0 EmptyTree EmptyTree
> fst $ backToRoot modified
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
以前の結果と一致します。あまりはっきりしないので、ツール関数を利用:
x +> f = f x
m = flip modifyTreeWithContext
簡単に変換して、より自然な方法で記述:
> fst $ backToRoot $ cTree +> goLeft +> goRight +> m 4 +> goUp +> goLeft +> m 0
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
木の根から開始し、左へ歩き、右へ歩き、4 に変更し、さらに上へ歩き、左へ歩き、0 に変更します。一連の操作は非常に自然で、データ構造が不変である制限を感じません
List
実際、List もこのより自然な方法で操作できます。構造コンテキスト情報を持っていればよいだけです
List にとって、左右 2 つの方向のみで、木のシナリオよりずっとシンプルです:
type ListWithContext a = ([a], [a])
左右穿梭、完全な List の再構築、要素の修正はすべて簡単に実装:
goListRight (x:xs, ps) = (xs, x:ps)
goListLeft (xs, p:ps) = (p:xs, ps)
backToHead (xs, []) = (xs, [])
backToHead ls = backToHead $ goListLeft ls
modifyListWithContext ([], ps) _ = ([], ps)
modifyListWithContext (x:xs, ps) v = (v:xs, ps)
試遊:
> let list = [1, 3, 5, 7, 8, 10, 12]
> let cList = (list, [])
> m = flip modifyListWithContext
> let modified = cList +> goListRight +> goListRight +> goListRight +> m 4 +> goListLeft +> goListLeft +> m 2
> modified
([2,5,4,8,10,12],[1])
> fst $ backToHead modified
[1,2,5,4,8,10,12]
第 4 の要素を 4 に変更し、第 2 の要素を 2 に変更しました。以前の做法と比較:
modifyList xs i x = take i xs ++ [x] ++ drop (i + 1) xs
> modifyList (modifyList list 1 2) 3 4
[1,2,5,4,8,10,12]
両者の違いは、前者は直感的な方法で要素を遍历、修正することをサポート し、不変の制限を感知しないことです
三.Zipper とは何か
上記で定義した TreeWithContext、ListWithContext はすべて Zipper です。正式な記述は以下の通り:
The Zipper is an idiom that uses the idea of "context" to the means of manipulating locations in a data structure.
「コンテキスト」の思想を使用してデータ構造中の位置を処理します。習慣的な呼び方は Zipper(ジッパー)です。なぜ「ジッパー」と呼ぶのでしょうか?
ListWithContext はジッパーで、非常に形象的です。List をジッパーと見なし、錠前は 1 つのカーソル(cursor、またはポインタと理解)で、カーソルが指す位置の要素が現在要素で、残りの要素はそのコンテキストです。錠前を右へ引き開け、左へ引っ張る(ファイル袋の封口を引く動作を想像)。データ構造操作に対応 すると、右へ新しい要素をアクセスし、最も右端まで引くのが遍历、左へ歴史要素をアクセスし、最も左端まで引くのが完全な List の再構築です
同様に、TreeWithContext もこのように理解できます。左へ右へ引き開け、新しい要素をアクセスし、上へ引っ張り、歴史要素をアクセスし、トップまで引くのが完全な木の再構築です
具体的には、Zipper はその通用程度に基づいて分類できます:
-
特定データ構造向けの Zipper:例えば ListZipper、TravelTree、TravelBTree
-
通用 Zipper:例えば Zipper Monad、Generic Zipper
具体データ構造向けの Zipper はすでに 2 つ実装済みです(xxxWithContext を Zipper に置き換えるだけ)。大まかな思路は:
Zipper, the functional cursor into a data structure, is itself a data structure, derived from the original one. The derived data type D' for the recursive data type D is D with exactly one hole. Filling-in the hole -- integrating over all positions of the hole -- gives the data type D back.
与えられたデータ構造から Zipper 構造を派生させます。具体做法は元のデータ構造を 2 つの部分に拆分し、部分構造(値として)と「穴」付き構造(値の構造コンテキストとして、「穴」があるのは元の完全構造から値が所在する部分構造を掘り出したため)で、両者を拼せるとちょうど元の完全構造になります。下図の通り:
[caption id="attachment_1762" align="alignnone" width="620"]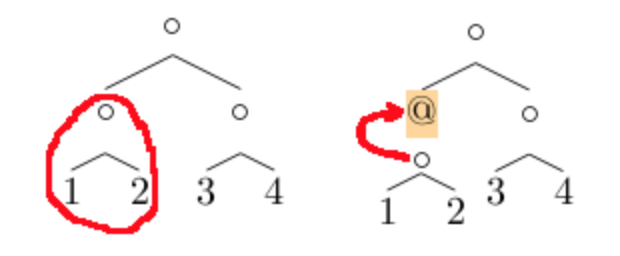 zipper-hole[/caption]
zipper-hole[/caption]
Zipper Monad
The Zipper Monad is a generic monad for navigating around arbitrary data structures. It supports movement, mutation and classification of nodes (is this node the top node or a child node?, etc).
移動、修正の他に、ノードタイプを区別することもできます。基本実装は以下の通り:
import Control.Monad.State
data Loc c a = Loc { struct :: a,
cxt :: c }
deriving (Show, Eq)
newtype Travel loc a = Travel { unT :: State loc a }
deriving (Functor, Monad, MonadState loc, Eq)
構造 + コンテキスト = 位置 で、いくつかの monadic 関数を通じて遍历、修正:
traverse :: Loc c a -- starting location (initial state)
-> Travel (Loc c a) a -- locational computation to use
-> a -- resulting substructure
traverse start tt = evalState (unT tt) start
-- modify the substructure at the current node
modifyStruct :: (a -> a) -> Travel (Loc c a) a
modifyStruct f = modify editStruct >> liftM struct get where
editStruct (Loc s c) = Loc (f s) c
-- put a new substructure at the current node
putStruct :: a -> Travel (Loc c a) a
putStruct t = modifyStruct $ const t
-- get the current substructure
getStruct :: Travel (Loc c a) a
getStruct = modifyStruct id -- works because modifyTree returns the 'new' tree
P.S. 元は Zipper 向けに設計された通用 Monad でしたが、結果として必要ないことがわかりました:
It's designed for use with The Zipper but in fact there is no requirement to use such an idiom.
現在どうやら木構造専用として使われているようです:
Zipper monad is a monad which implements the zipper for binary trees.
Generic Zipper
もう 1 つの通用 Zipper:
Generic Zipper: the context of a traversal
Zipper を遍历操作のコンテキストと見なします。以前の思路とは異なります:
We advocate a different view, emphasizing not the result of navigating through a data structure to a desired item and extracting it, but the process of navigation.
データ構造中の某个位置に移動し、想要的ものをアクセスすることを強調せず、移動のプロセスのみを关注 します:
Each data structure comes with a method to enumerate its components, representing the data structure as a stream of the nodes visited during the enumeration. To let the user focus on a item and submit an update, the enumeration process should yield control to the user once it reached an item.
遍历の角度から見ると、データ構造は枚举過程中にアクセスされたノードが形成するストリームです。したがって、某个ノードを关注して更新したい場合、枚举プロセスはそのノードにアクセスした時に制御権をユーザーに返すべきです。例えば:
Current element: 1
Enter Return, q or the replacement value:
Current element: 2
Enter Return, q or the replacement value:
Current element: 6
Enter Return, q or the replacement value:
42
Current element: 24
Enter Return, q or the replacement value:
q
Done:
fromList [(1,1),(2,2),(3,42),(4,24),(5,120),(6,720),(7,5040),(8,40320),(9,362880),(10,3628800)]
(詳細は ZipperTraversable を参照)
P.S. この思路は [JS 中のジェネレーター](/articles/javascript 生成器/#articleHeader8) に非常に似ています。每歩歩くごとに一息ついて 要素を修正する必要があるか、または遍历を停止するかを見ます:
As Chung-chieh Shan aptly put it, 'zipper is a suspended walk.'
コメントはまだありません