零.배경
서버 측이 여러 프론트엔드 장비에서의 사용자 경험을 지원해야 할 때, 종종기존 API 와某一端 UI 가 긴밀하게 결합된 상황에 직면한다
예를 들어 PC 단 페이지를 위해 설계된 API 가 모바일 단을 지원해야 할 때, 기존 인터페이스는 설계부터 구현까지 데스크톱 UI 표시 요구와 강하게 관련되어 있어 모바일 단의 표시 요구에 간단히 적응할 수 없다
一.현황
하나의 백엔드 API 계층이 여러 프론트엔드 (PC 단, 모바일 단 등) 를 대상으로 할 때, 일반적으로 일단 한 단을 지원한 후 더 많은 기능을 추가하여其它 단을 지원한다
It's tempting to design a single back-end API to support all clients with a reusable API.
여러 프론트엔드 UI 가 요구하는 API 가 유사하다면 이렇게 해도 문제없다 (기존 API 를 약간 강화하면 다른 프론트엔드 경험을 지원할 수 있음). 하지만모바일 단 UI 경험은 일반적으로 PC 단과 다르다
Valuable services support many variations in clients, such as mobile versus web and different forms of web interface.
예를 들어:
-
화면 공간이 작아 표시할 수 있는 데이터도 적다
-
여러 연결을 설정하면 전력 소비가 증가하고, 프론트엔드에서 데이터 집계 비용이 높다
-
인터랙션 방식 차이가 크고, 백엔드 API 가 지원해야 하는 기능도 다르다. 예를 들어 PC 단은 폼 입력, 모바일 단은 QR 코드 스캔……
따라서 모바일 단은 일반적으로:
-
다른 (또는 더 적은) API 호출을 수행한다. 예를 들어 집계 등
-
다른 (또는 더 적은 양의) 데이터를 표시한다
또한, 하나의 백엔드 API 는 일반적으로 여러 프론트엔드 애플리케이션을 지원해야 하며, 이때 단일 백엔드가 버전 이터레이션의 병목이 될 수 있다. 각 버전의 작업량이 방대하기 때문이다 (N 개의 프론트엔드 애플리케이션과 연동). 이로 인해 방대한 독립 백엔드 팀이 생겨 여러 프론트엔드 팀에 API 를 제공하고, 각 프론트엔드 팀은 해당 팀과 변경 사항을 조율해야 하며, 해당 팀은 여러 프론트엔드 팀의 요구 우선순위를 균형 잡아야 한다……继而크로스팀 협업 비효율, 리소스 조정 어려움 등의 문제에 직면한다
二.BFF 의 유래
이상의种种로 인해, 우리는 하나의 큰 백엔드가 여러 단의 경험에 통일적으로 API 지원을 제공하는 것을 기대하지 않고, 각 사용자 경험에 대응하는 하나의 백엔드 (one backend per user experience) 를 주며, Backend For Frontend (BFF) 라고 하며, 사용자 경험 적응층으로 번역한다
Consequently it's often best to define different back-end services for each kind of front-end client.
개념적으로, 각 프론트엔드 애플리케이션을 두 부분으로 나눈다: 클라이언트 애플리케이션과 서버 측 부분 (BFF). 그 중, BFF 는 특정 사용자 경험을 대상으로 하며,这部分 UI 를 구현하는 프론트엔드 팀이 구현 및 유지보수를 담당한다 (즉 UI 와 대응하는 BFF 는 같은 팀이 담당)
These back ends should be developed by teams aligned with each front end to ensure that each back end properly meets the needs of its client.
같은 팀인 장점은:
-
UI 에 기반하여 API 를 정의하거나 조정하기 쉽다
-
클라이언트, 서버 측의 릴리스 프로세스를 단순화한다 (의존 항목이 줄어듦)
-
하나의 BFF 는 하나의 UI 에만 집중하여 더 작고 더 유연하다
서비스의 관점에서 보면, BFF 는 실제로 단일 서비스가 지원하는 소비자 (프론트엔드 애플리케이션을 지칭) 의 수를 제한하여它们을 더 사용하기 쉽고 (프론트엔드 요구에 더 부합) 변경하기 쉽게 하며, 프론트엔드 애플리케이션을 개발하는 팀이 더 많은 자율권을 보유하도록 돕는다:
The simple act of limiting the number of consumers they support makes them much easier to work with and change, and helps teams developing customer-facing applications retain more autonomy.
三.구체적인 구현
BFF 와 사용자 경험을 1:1 로 요구한다. 즉 하나의 큰 백엔드를 여러 개의 작은 백엔드로 분할해야 한다
세분화 입자도
분할해야 한다면 무엇을 기준으로 분할해야 하는가? 어느 정도까지 세분화해야 하는가?
3 가지 분할 방식이 생각난다:
-
사용자 경험 레벨 (UI 레벨): 각 UI 인터랙션에 대응하는 하나의 BFF. 예를 들어 PC 단 1 개, 모바일 단 3 개 (예를 들어 작은 화면 휴대폰, 중간 화면 휴대폰, 큰 화면 휴대폰의 3 개 UI 인터랙션 차이가 크다면 3 개의 BFF 로 분할할 필요 있음)
-
단 레벨: 각 프론트엔드 장비에 대응하는 하나의 BFF. 예를 들어 PC, Android, iOS, 시계, 차량용 기기 등
-
팀 레벨: 각 프론트엔드 팀에 대응하는 하나의 BFF. 기존 조직 구조에 따라 분할
사용자 경험 레벨 분할을 권장한다. 단 레벨 분할은 여러 단의 UI 가 유사하다면 인터페이스는 아마도 직접 재사용할 수 있어 분할할 필요가 없고, 조직 구조는 유연하게 조정할 수 있어 기술 방안을 제한해서는 안 되기 때문이다
하류 서비스 (마이크로서비스) 와 연동
각 BFF 는 여러 하류 서비스와 연동해야 하므로 필연적으로 몇 가지 문제가 존재한다:
-
기술 스택이 다른 여러 하류 서비스와 어떻게 연동하는가?
-
이러한 호출을 어떻게 관리하고 어떻게 조합하는가?
-
某 호출이 실패할 때 어떻게 가용성을 보장하는가?
통일된 RPC 프로토콜은 하류 서비스 기술 스택의 차이를 평평하게 할 수 있다. 비동기 호출 관리에 대해서는 RxJava, Finagle 등의 이벤트 메커니즘을 활용하여 이러한 비동기 플로우 제어를 단순화할 수 있다. 일부 호출이 실패할 때의 가용성 문제는 BFF 계층에서 폴트톨러런스를 수행하고, 동시에 프론트엔드가 불완전한 응답 내용을 받아들일 수 있음을 보장함으로써 해결할 수 있다
재사용 문제
분할한 후 여러 BFF 간에 중복 코드가 발생하기 쉽다. 특히 일부 공통 백엔드 로직 (인증, 인가, 속도 제한 등)
BFF 간 코드 중복을 제거하기 위해 일반적으로 두 가지 방법을 채택한다:
-
여러 BFF 를 하나로 통합
-
BFF 위에 Edge API service 추가
여러 BFF 를 하나로 통합하면 다시 처음 문제로 돌아간다. 유연성을 위해 분할했는데 재사용을 위해 통합하다니……헛수고다. 다른 옵션은*게이트웨이 서비스 (Edge API service)*를 추가하여 공통 로직을 넣고 BFF 가 비즈니스 로직에 집중하도록 하는 것이다:
It validates and authenticates incoming requests; it enforces rate limits to protect the platform from undue load, and it routes requests to the appropriate upstream services. Factoring these high-level features into the edge service is a huge win for platform simplicity.
재사용 문제 자체로 돌아가면, 우리는 중복을 제거하고 싶지만 BFF 간 긴밀한 결합을 초래하는 것을 원하지 않는다. 따라서 절충적인 태도가 있다: BFF 간 중복을 허용하고, 단일 BFF 내 중복을 제거. 즉 일정 수준의 BFF 간 중복을 허용한다
물론 재사용의 전제는 여러 BFF 의 기술 스택이 같고, 이후 중복 부분을 식별하여 리팩토링하는 것이다. 구체적으로 공통 부분을 추출해야 하는 단계가 되면 몇 가지 선택이 있다:
-
공통 라이브러리 추출
-
독립 service 로 추출
-
하류 서비스로下沉
하지만공통 라이브러리는 일반적으로 결합의 주요 원인이다. 예를 들어 하류 서비스를 호출하는 공통 로직은 BFF 간 결합을 유발한다. 독립 service 방안이 상대적으로 더 낫다. 새로운 service 를 도메인 모델로 개념화할 수 있다. 유사하게 공통 로직을 하류 서비스로下沉시켜 평급 하류 서비스를 의존 관계가 있는 트리 구조로 만들 수도 있다
어떻게 재사용 문제를 해결하든, 재용이 필요할 때에만 수행해야 한다. 일반 원칙은:
Creating an abstraction when you're about to implement something for the 3rd time.
四.적용 장면
모바일 장비에 비해 PC 장비 성능은 충분히 좋으므로 여러 하류 서비스를 직접 호출할 수 있다 (비용이 높지 않음). BFF 를 거치지 않아도 되는가?
실제로 프론트엔드 애플리케이션에 직접面向하는 하류 서비스와 비교하여 BFF 의 의미는 다음을 구현하는 데 적합하다는 것이다:
-
서버 측 템플릿
-
데이터 집계 (여러 인터페이스 호출 통합), 편성 (프론트엔드가 원하는 형태로 포맷), 트리밍 (프론트엔드가 필요로 하지 않는 정보 제거)
-
집계 호출 결과 캐시
-
某 UI 경험 (모바일 단 등) 에 특정 기능 제공
-
제 3 자가 사용하는 API. 제 3 자 제한으로 인해 추가된 로직 유지 용이
BFF 는 하류 서비스 위에 위치한 계층이며 사용자 경험 입자도로 세분화되어 있으므로 하류 서비스보다 더 유연하며, 특히 제 3 자에게 커스텀 API 를 제공하는 등의차별화 장면에 적합하다
五.업계 실천
BFF 이념에 따라 큰 백엔드를 프론트엔드 경험에 따라 분할한다. 아래 그림과 같다:
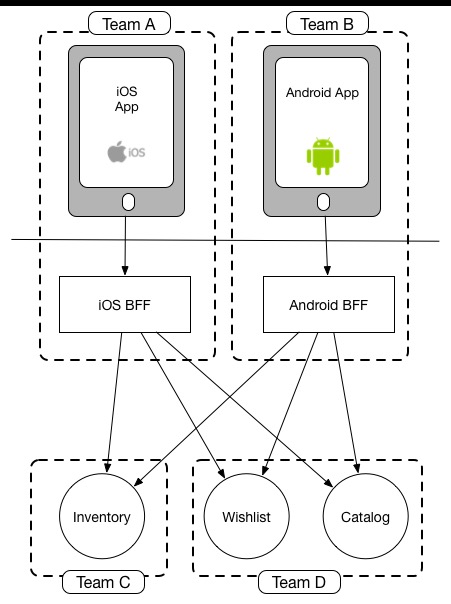
구체적인 실천에서 BFF 는 일반적으로 그림과 같지 않다. 주요 변화는:
-
비즈니스 라인에 따라 BFF 분할
-
게이트웨이 계층 추가, 라우팅, 인증, 모니터링, 속도 제한/서킷 브레이커, 보안 등 기능 구현
비즈니스 라인에 따라 분할된 BFF 는 하류 기초 서비스 위에 구축된비즈니스형 마이크로서비스와 같다. 다만 이러한 마이크로서비스는 대응하는 비즈니스의 프론트엔드 팀이 개발 유지보수를 담당한다. 광의로는 더 세분화된 BFF 로 이해할 수 있다. 즉 각 비즈니스에 대응하는 하나의 BFF (더 이상 사용자 경험 차이에 따라 분할하지 않음)
게이트웨이 계층은 공통 경계 서비스를 구현하여 인증, 속도 제한 등을 수행하고 BFF 가 비즈니스 관련 부분에 더 집중하도록 한다:
前端体验
--------------------
^ ^
| |
网关
------------
BFF BFF
----- -----
^ ^ ^ ^
/ \ / \
--------------------
下流服务
더甚者는 게이트웨이 계층도 분할하여 BFF 와 1:1 로 대응시킨다:
前端体验
--------------------
^ ^
| |
网关 网关
----- -----
BFF BFF
----- -----
^ ^ ^ ^
/ \ / \
--------------------
下流服务
P.S.또한 BFF 를 도입하지 않고 전달 서비스만 추가하여 데이터 집계, 편성, 트리밍 등 문제를 해결하는 것도 있다. GraphQL 과 유사하지만 무의미한 데이터 투과가 발생하기 쉽기 때문에 일반적으로 전체 커버리지 는 아니다 (모든 데이터 요청이 전달 서비스를 거치는 것은 아님):
前端体验
--------------------
^ ^
| |
传递服务 |
-------- |
^ ^ |
/ \ |
--------------------
下流服务
탐색
실천에서 BFF 의 탐색 방향은 주로 3 가지가 있다:
-
안정성: BFF 의 신뢰성 보장. 예를 들어 로그, 오류 분석, 모니터링, 알림 등 수단을 통해
-
동질: BFF 와 프론트엔드 경험에 동일한 기술 스택 사용. 예를 들어 Node 기반 동질 방안
-
일체화: 한편으로는 하류 서비스向け mock 방안을 제공하고, 다른 한편으로는 동질, 비동질 애플리케이션 공존 허용
BFF 모드에서는 프론트엔드 개발자가 일정 수준의 풀스택 지식 (서버 측 스킬, 운영, 보안 등 지식) 을 습득해야 하므로, 자연스럽게 동질 또는 일체화 방안을 통해 개발 경험을 향상시키고 진입 장벽을 낮추며 기술을 무감각하게 만들고자 한다
越来越多的 개발자가 프로세스, 빌드, 환경, 배포 등 various 일에 더 이상 관심 갖지 않아도 되기를 바라며, 기술 무감각화 (Techless) 를 실현하여 모든 개발자가 조용히 즐겁게 코딩할 수 있기를 바란다.
六.장점
관심사 분리
BFF 모드의 가장 큰 장점은*관심사 분리 (separation of concerns)*이다. 하류 서비스는 비즈니스 도메인 모델에 집중할 수 있고, 프론트엔드 UI 는 사용자 경험에 집중할 수 있다:
백엔드는 비즈니스 도메인에 집중할 수 있으며, 더 도메인 모델의 관점에서 문제를 생각할 수 있다. 페이지 관점의 데이터는 프론트엔드형 풀스택 엔지니어에게 맡긴다. 도메인 모델과 페이지 데이터는 두 가지 사고 모드이며, BFF 를 통해 잘 디커플링하여 서로를 더 전문적이고 효율적으로 만든다.
분업의 관점에서 보면:
BFF 모드는 단순한 기술 아키텍처가 아니라, 사회적 분업 관점에서 BFF 는 다원적 가치 지향의分层 아키텍처이며, 각 층에는 충분한 공간이 있다.
자주권
팀 관점에서 보면, 전통적인 전후단 분리의 주요 문제는:
-
서비스의 확장성과 복잡성
-
전후단 팀의 다대일 관계. 프론트엔드 팀은 필연적으로 세분화되어야 하기 때문이다 (기술 구현 차이로 인해专人负责 필요)
-
크로스팀 협업 비용. 예를 들어 프론트엔드 UI 개발 과정에서 백엔드 API 가 변경될 수 있다 (크로스팀 조정 커뮤니케이션 비용 존재)
BFF 모드에서는 API 의 owner 는 대응하는 사용자 경험을 구현하는 프론트엔드 팀이다. 즉프론트엔드 팀이 API 의 자주권을 가진다. 신속하게 변경을 조정할 수 있다
프론트엔드와 BFF 팀 일체화의 또 다른 장점은클라이언트 구현인지 서비스 구현인지 유연하게 선택할 수 있다는 것이다 (예를 들어 공통성이 강한 것은 서비스 구현, 또는 신속한 릴리스 심사 통과를 위해 서비스 구현도 가능). 크로스팀 조정 불필요
아직 댓글이 없습니다