서론
읽기/쓰기 분리、데이터베이스 분할、비정규화、NoSQL 채택……이러한 확장 수단을 모두 도입해도 데이터 응답이 점점 더 느려진다면,还有什么 해결책이 있을까요?
있습니다, 캐시를 추가합니다. 캐시 계층을 이용하여 불균일한 부하와 트래픽 피크를 흡수합니다:
Popular items can skew the distribution, causing bottlenecks. Putting a cache in front of a database can help absorb uneven loads and spikes in traffic.
一.어디에 추가할까?
이론상, 데이터 계층 이전의 임의의 계층에 캐시를 추가하면 트래픽을 차단할 수 있으며, 최종적으로 데이터베이스에 도달하는 작업 요청을 줄일 수 있습니다:
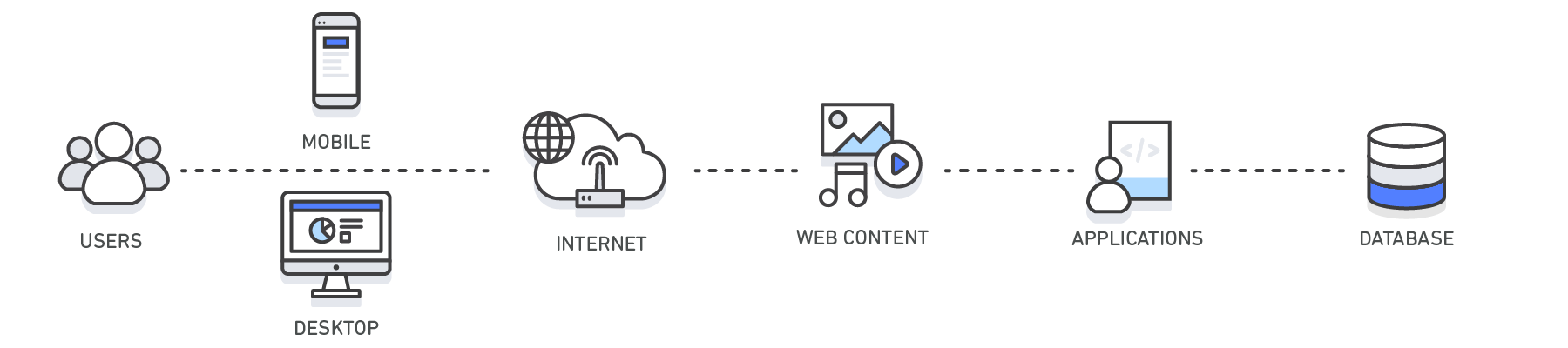
캐시의 위치에 따라 4 가지로 분류됩니다:
-
클라이언트 캐시: [HTTP 캐시](/articles/http 캐시/), 브라우저 캐시 등 포함
-
Web 캐시: 예를 들어 CDN, 리버스 프록시 서비스 등
-
데이터베이스 캐시: 일부 데이터베이스는 내장 캐시 지원을 제공합니다. 예를 들어 쿼리 캐시 (query cache)
데이터베이스의 부하를 줄이기 위해, 애플리케이션과 데이터 저장소 사이에 키 - 값 저장소를 버퍼 계층으로 추가합니다:
A cache is a simple key-value store and it should reside as a buffering layer between your application and your data storage.
메모리 내에 캐시된 데이터로 일부 요청에 응답하고 실제로 데이터베이스 쿼리를 실행할 필요가 없으므로 데이터 응답 속도를 향상시킵니다
二.무엇을 저장할까?
일반적인 두 가지 캐시 모드가 있습니다:
-
Cached Database Queries: 원본 데이터베이스 쿼리 결과를 캐시
-
Cached Objects: 애플리케이션 내의 데이터 모델을 캐시. 예를 들어 재구성된 데이터셋, 또는 전체 데이터 모델 클래스 인스턴스
원본 데이터베이스 쿼리 결과를 캐시
쿼리 문에서 key 를 생성하고, 데이터베이스 쿼리 결과를 캐시합니다. 예를 들어:
key = "user.%s" % user_id
user_blob = memcache.get(key)
if user_blob is None:
user = mysql.query("SELECT * FROM users WHERE user_id=\"%s\"", user_id)
if user:
memcache.set(key, json.dumps(user))
return user
else:
return json.loads(user_blob)
이 모드의 주요 결함은 캐시 만료 처리가 어렵다는 것입니다. 데이터와 key (즉 쿼리 문) 사이에 명확한 연관성이 없기 때문에, 데이터가 변경된 후, 캐시의 모든 관련 항목을 정확하게 삭제하기 어렵습니다. 생각해보세요, 하나의 셀이 변경되면 어떤 쿼리 문에 영향을 줄까요?
그럼에도 불구하고, 이것은 가장 일반적인 캐시 모드입니다. 타협할 수 있기 때문입니다. 예를 들어:
-
쿼리 문과 직접 연관된 데이터만 캐시하고, 정렬, 통계, 필터링 등의 계산 결과는 모두 저장하지 않음
-
정확함을 추구하지 않고, 영향을 받을 수 있는 모든 캐시 항목을 삭제
데이터 객체를 캐시
또 다른 접근 방식은 애플리케이션 내의 데이터 모델 객체를 캐시하는 것입니다. 이렇게 하면 원본 데이터와 캐시 사이에 논리적 연관성이 생겨, 캐시 업데이트의 난제를 쉽게 해결할 수 있습니다
데이터가 어떻게 쿼리되고, 어떻게 가공 변환되든, 최종적으로 얻은 데이터 모델 객체만 캐시하고, 원본 데이터가 변경되면 해당 데이터 객체 전체를 제거합니다
애플리케이션에게 데이터 객체는 원본 데이터보다 관리 및 유지보수가 쉽습니다. 따라서, 원본 데이터가 아닌 데이터 객체를 캐시하는 것을 권장합니다
三.어떻게 조회할까?
일반적인 캐시 데이터 액세스 전략은 6 가지입니다:
-
Cache-aside/Lazy loading: 예약 캐시
-
Read-through: 직독식
-
Write-through: 직쓰기식
-
Write-behind/Write-back: 백쓰기식
-
Write-around: 우회쓰기식
-
Refresh-ahead: 갱신식
Cache-aside

예약 캐시 모드에서는 캐시와 데이터베이스 사이에 직접적인 관계가 없습니다 (캐시가 옆에 있으므로 Cache-aside 라고 함). 애플리케이션이 필요한 데이터를 데이터베이스에서 읽어와 캐시에 채웁니다
데이터 요청은 우선 캐시를 통과하고, 캐시 미스 시에만 데이터베이스를 쿼리하고 결과를 캐시합니다. 따라서 캐시는 온디맨드입니다 (Lazy loading). 실제로 액세스된 데이터만 캐시됩니다
주요 문제는 다음과 같습니다:
-
캐시 미스 시 3 단계가 필요하며, 지연을 무시할 수 없습니다 (콜드 스타트의 경우 수동으로 예열 가능)
-
캐시가 오래될 수 있습니다 (일반적으로 TTL 을 설정하여 강제로 업데이트)
Read-through

직독 모드에서는 캐시가 데이터베이스 앞에 있고, 애플리케이션은 데이터베이스와 직접 상호작용하지 않고, 캐시에서 직접 데이터를 읽습니다
캐시 미스 시, 캐시가 데이터베이스 쿼리를 담당하고, 스스로 캐시합니다. 예약 캐시와의 유일한 차이점은 데이터베이스 쿼리 작업을 캐시가 담당한다는 점입니다. 애플리케이션이 아닙니다
Write-through

직독 모드와 유사하게, 캐시도 데이터베이스 앞에 있고, 데이터는 먼저 캐시에 쓴 다음 데이터베이스에 씁니다. 즉, 모든 쓰기 작업은 먼저 캐시를 통과해야 합니다
일반적으로 직독식 캐시와 결합하여 사용되며, 쓰기 작업은 캐시 계층이 하나 더 많습니다 (추가 지연이 존재하지만), 캐시 데이터의 일관성을 보장합니다 (캐시가 오래되는 것을 방지). 이때, 캐시는 데이터베이스의 프록시처럼 작동하여 읽기/쓰기 모두 캐시를 통과하고, 캐시가 데이터베이스를 쿼리하거나 쓰기 작업을 데이터베이스에 동기화합니다
Write-behind/Write-back

백쓰기식 캐시는 직쓰기식과 매우 유사하며, 쓰기 작업도 마찬가지로 먼저 캐시를 통과하지만, 유일한 차이점은 데이터베이스에 비동기 쓰기로, 배치 처리 및 쓰기 작업 병합을 허용합니다
마찬가지로 직독식 캐시와 결합하여 사용할 수 있으며, 직쓰기식의 쓰기 작업 성능 문제도 존재하지 않지만, 최종 일관성만 보장합니다
Write-around
소위 우회쓰기식 캐시는 쓰기 작업이 캐시를 통과하지 않고 (우회하여), 애플리케이션이 직접 데이터베이스에 씁니다. 읽기 작업만 캐시합니다. 예약 캐시 또는 직독 캐시와 결합하여 사용할 수 있습니다:

Refresh-ahead
사전 갱신. 캐시가 만료되기 전에, 최근 액세스된 항목을 자동으로 갱신 (재로드) 합니다. 프리로드로 지연을 줄일 수도 있지만, 예측이 정확하지 않으면 오히려 성능이 저하될 수 있습니다
四.가득 차면 어떻게 할까?
물론, 캐시 공간은 매우 제한적이므로, 제거 전략 (Eviction Policy) 도 필요합니다. 캐시에서 사용될 가능성이 낮은 항목을 제거합니다. 일반적인 전략은 다음과 같습니다:
-
LRU (Least Recently Used): 가장 일반적인 전략. 프로그램 실행 시의 국소성 원리에 따라, 일정 기간 내에 동일한 데이터에 액세스할 확률이 높으므로, 최근에 사용되지 않은 데이터를 제거합니다. 예를 들어 항공권 예약에서, 일정 기간 내에 동일한 경로를 조회할 확률이 높음
-
LFU (Least Frequently Used): 사용 빈도에 따라, 가장 덜 자주 사용되는 데이터를 제거합니다. 예를 들어 입력기의 대부분은 단어 빈도에 따라 연상함
-
MRU (Most Recently Used): 일부 시나리오에서는 최근에 사용한 항목을 삭제해야 합니다. 예를 들어 읽음, 다시 알림 안 함, 관심 없음 등
-
FIFO (First In, First Out): 선입선출. 가장 일찍 액세스된 데이터를 제거
이러한 전략은 결합하여 사용할 수도 있습니다. 예를 들어 LRU + LFU 로 종합적으로 고려합니다. 구체적인 시나리오에 따라 다릅니다
아직 댓글이 없습니다