서두
데이터베이스 계층의 확장 문제를 해결하기 위해, 우리는 이미 두 가지 방안을 논의했습니다:
-
Replication: 단일 데이터베이스에서 다중 데이터베이스로 확장하여 더 많은 요청량을 처리
-
Partitioning: 단일 데이터베이스 (테이블) 을 다중 데이터베이스 (테이블) 로 분할하여 단일 데이터베이스의 성능 병목 현상 타파
(다중 머신) 다중 데이터베이스 다중 테이블의 지원 하에, 급증하는 요청량, 데이터량은 더 이상 문제가 아닙니다. 그러나 데이터량 외에도, 단일 데이터베이스 성능에 극도로 영향을 미치는 요인이 하나 있습니다——데이터 조직 방식
예를 들어, 관계형 데이터베이스에서 데이터 엔티티는 2 차원 테이블 (엔티티 테이블이라 함) 로 설명됩니다:
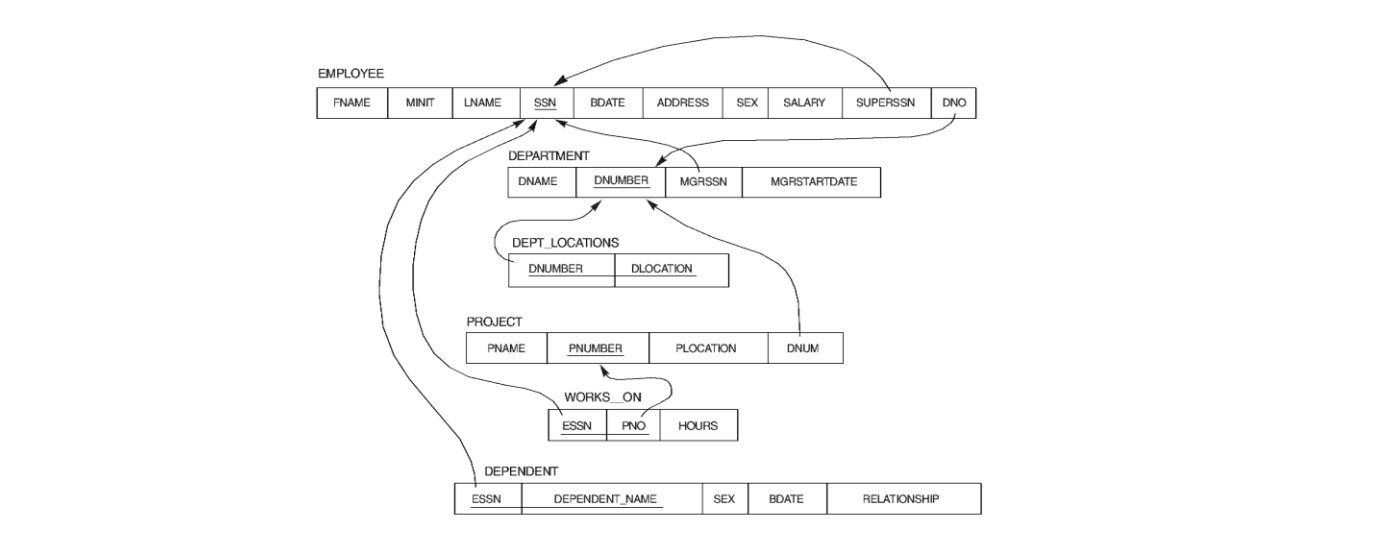
엔티티 간의 복잡한 연관 관계 (다대다) 도 2 차원 테이블 (관계 테이블이라 함) 로 설명됩니다:
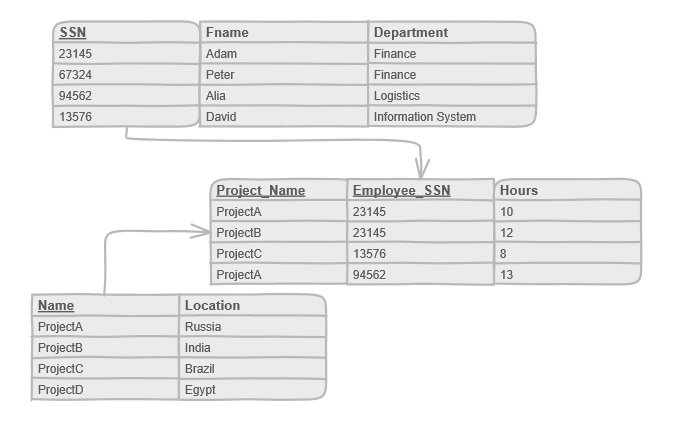
따라서 목표 정보를 얻기 위해 종종 다중 테이블 결합 조회가 필요하며, 관계가 복잡할수록 읽기 성능은 나빠지고, 최종적으로 데이터량과 마찬가지로 단일 데이터베이스 성능 병목 현상이 되어 데이터베이스 계층의 확장 가능성을 제약합니다
그렇다면, 관계형 데이터베이스에서 데이터 읽기 성능을 더욱 향상시킬 방법이 있을까요?
있습니다. (일정程度上) 데이터 조직 방식을 변경하는 것, 즉 비정규화 (Denormalization) 입니다
일.정규화
비정규화를 논의하기 전에, 먼저 정규화가 무엇인지, 무엇을 비정규화하는지 명확히 할 필요가 있습니다
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity.
정규화 (Database normalization) 는 일련의 정규형 (Normal forms) 요구에 따라 데이터 모델을 조직하는 과정으로, 목적은 데이터 중복성을 줄이고 데이터 무결성 을 향상시키는 것입니다
试想, 만약 동일한 정보가 여러 행에서 반복 나타나고, 무관한 정보도 같은 테이블에 모여 있다면, 몇 가지 이상 상황이 발생하기 쉽습니다:
-
갱신 이상: 단일 행만 갱신하면 논리적 불일치가 발생
-
삽입 이상: 일부 정보만 삽입할 수 없으며, 다른 열을 먼저 비워둬야 함
-
삭제 이상: 일부 정보를 삭제할 때, 다른 무관한 정보에도 영향을 미칠 수 있음
이러한 이상 상황을 피하기 위해, 사람들은 몇 가지 제약 규칙을 제안했습니다. 즉 데이터베이스 설계 정규형입니다
이.데이터베이스 설계 정규형
-
1NF: 제 1 정규형 (First normal form) 은 데이터 테이블의 각 필드 값이 더 이상 분할될 수 없음을 요구
-
2NF: 제 2 정규형 (Second normal form) 은 1NF 를 만족하는基础上에서, 모든 비주 속성이 주 키에 완전히 의존할 것을 요구
-
3NF: 제 3 정규형 (Third normal form) 은 2NF 를 만족하는基础上에서, 모든 비주 속성이 어떤 주 키에도 추이 의존하지 않을 것을 요구
P.S.此外,还有 BCNF、4NF、5NF 등, 구체적 내용은 Normal forms 참조
애플리케이션 계층에 비유하면, 설계 정규형은 데이터 계층의 설계 패턴에相當하며, 데이터 테이블을 결합 해제하고, 단일 테이블 정보를 더욱 응집시키며,彼此 경계를 분명하게 하고, 의존 관계를 더욱 명확하게 합니다
일반적으로 3NF 를 만족하는 관계 모드 (Relation schema) 를 정규화된 (Normalized) 이라 하며, 대부분의 경우 위에서 언급한 삽입, 갱신, 삭제 이상을 회피할 수 있습니다. 그러나 이러한 문제를 해결하는 동시에, 정규화는 또 다른 문제도 가져옵니다
삼.정규화의 폐해
이러한 설계 정규형의 제약 하에서, 연관된 정보는 다른 논리 테이블에 저장됩니다:
A normalized design will often "store" different but related pieces of information in separate logical tables (called relations).
예를 들어:
[caption id="attachment_2131" align="alignnone" width="625"]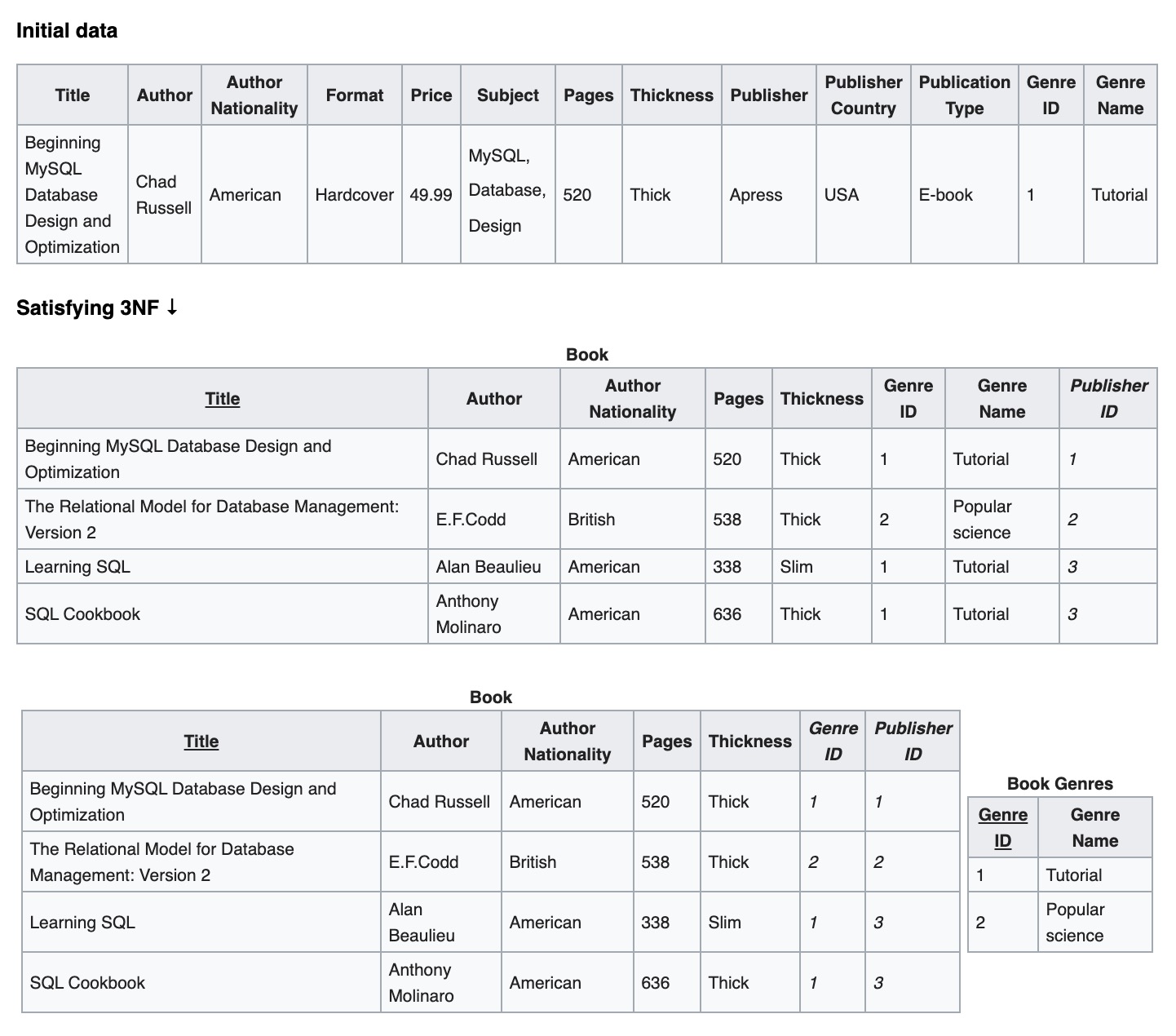 3NF[/caption]
3NF[/caption]
그로 인해 종종 다중 테이블 결합 조회 (join 연산) 가 필요하며, 관계가 복잡할수록 테이블 결합 조회는 느려집니다:
If these relations are stored physically as separate disk files, completing a database query that draws information from several relations (a join operation) can be slow. If many relations are joined, it may be prohibitively slow.
그렇다면, 조회 성능을 개선할 방법이 있을까요?
있습니다. 중복성을 도입하는 것입니다:
-
DBMS 가 추가의 중복 정보를 저장하도록 허용. 예를 들어 인덱스 뷰 (indexed views), 머티리얼라이즈드 뷰 (materialized views).但仍遵从设计范式
-
중복 데이터를 추가하고,
join연산을 줄이며, 설계 정규형을 타파 (즉비정규화)
사.비정규화
소위 비정규화란, 설계 정규형을 준수하는 데이터베이스 (관계 모드) 에 대한 성능 최적화 전략입니다:
Denormalization is a strategy used on a previously-normalized database to increase performance.
P.S.주의, 비정규화는 비정규화 형식 (Unnormalized form) 과 동일하지 않습니다. 비정규화는 반드시 정규화 설계를 만족하는基础上에서 발생합니다. 전자는 모든 규칙을 준수한 후 국소 조정을 수행하고 일부러 일부 규칙을 타파하는 반면, 후자는 규칙을 완전히 무시합니다
중복 데이터를 추가하거나 데이터를 그룹화함으로써, 일부 쓰기 성능을 희생하여 더 높은 읽기 성능을 획득합니다:
In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.
설계 정규형의 제약 하에서, 데이터 테이블에는 중복 정보가 없습니다 (어떤 데이터는某테이블의某셀에만 저장). 어떤 데이터를 얻기 위해 일련의跨表 조회가 필요할 수 있어, 따라서 읽기 작업 성능은 좋지 않지만, 쓰기 작업은 빠릅니다. 데이터 갱신 시 한 곳만 수정하면 되기 때문입니다
비정규화는 이러한 제약을 타파하고, 어떤 데이터를 다른 곳에 여러 부 복사 저장하여 데이터 검색 속도를 높입니다:
The opposite of normalization, denormalization is the process of putting one fact in many places.
구체적 조작
구체적으로, 일반적인做法는 다음과 같습니다:
-
파생 데이터 저장:Redux Store 에 계산 속성을 추가하는 것과 유사. 빈번하게 반복 계산하는 결과를 저장. 예를 들어 일대다 관계에서, "다"의 수를 "일"의 속성으로 저장
-
사전 결합 (pre-joined) 으로 집계 테이블 생성: 빈번하게
join하는 테이블을 미리join해둠 -
하드코드 값 채택: 의존 테이블의 상수 값 (또는 빈번하게 변화하지 않는 값) 을 직접 현재 테이블에 하드코드하여
join연산 회피 -
상세 정보를 주 테이블에 통합: 데이터량이 크지 않은 상세 테이블의 경우, 전부/부분의 상세 정보를 주 테이블에 추가하여
join연산 회피
P.S.비정규화 구체적做法에 대한 더 많은 정보는, When and How You Should Denormalize a Relational Database 참조
오.비정규화의 대가
그러나 필요하지 않은 한, 일반적으로 비정규화는 권장되지 않습니다. 그 대가는 비쌉니다:
-
데이터 무결성 보장을 상실: 정규형을 타파하는 것은,之前通过 정규화 해결한 갱신, 삽입, 삭제 이상 문제가 다시 나타날 것을 의미합니다. 즉, 중복 데이터의 일관성은 DBA 자신이 보증해야 하며, 인덱스 뷰 등 DBMS 가 보증하는 것과 다릅니다
-
쓰기 속도를 희생: 비정규화는 중복 데이터를 도입하므로, 갱신 시 여러 곳을 수정해야 합니다. 그러나 대부분의 시나리오는 읽기 집중형이며, 쓰기가 조금 느린 것은 문제가 되지 않습니다
-
저장 공간을 낭비: 불필요한 중복 데이터를 저장하므로, 자연스럽게 일부 저장 공간을 낭비합���다. 그러나 공간으로 시간을 바꾸는 것은 일반적으로 허용 가능합니다 (메모리, 하드디스크 등 자원이 이미 상대적으로 저렴해졌기 때문)
P.S.일반적으로 제약 규칙 (constraints) 을 통해 중복 데이터의 일관성을 보증하지만, 이러한 규칙은 일부 작용을 상쇄합니다
아직 댓글이 없습니다