서론
데이터베이스의 처리 능력을 향상시키기 위해, 단일 데이터베이스를 복수 데이터베이스로 확장하고, 업데이트 동기화 메커니즘 (즉 Replication) 으로 복수 데이터의 일관성을 보증합니다. 이렇게 하면 데이터베이스의 확장 난제는 이미 순조롭게 해결된 것처럼 보입니다
그러나, Replication 방안에서는, 각 데이터베이스가 완전한 데이터를 보유하며, 전량 데이터에 기반하여 추가·삭제·갱신·검색 서비스를 제공하므로, 단일 데이터베이스의 성능 병목은 여전히 존재하며, 시스템 확장성을 제한하는 중요한 요인이 됩니다
一.단일 데이터베이스의 성능 병목
단일 머신의 하드웨어 리소스는 제한되어 있으므로, 단일 데이터베이스의 처리 능력도 제한되어 있습니다:
-
용량 제한: 데이터량이 단일 데이터베이스에 수용할 수 없을 정도로 커질 수 있습니다
-
성능 제한: 단일 데이터베이스의 읽기/쓰기 성능도 데이터량의 영향을 받으며, 쿼리/갱신이 점점 더 느려집니다
머신/데이터베이스를 추가하는 것만으로는, 단일 머신/단일 데이터베이스의 성능 문제를 직접 해결할 수 없습니다. 더욱이 데이터베이스의 경계를 깨고, 단일 데이터베이스를 복수 데이터베이스로 분할해야 합니다 (단순히 복수 복사하는 것만이 아닙니다)
P.S.이론상, Web 애플리케이션 계층도 동일한 문제에 직면하지만, 1 개의 Web 서비스가 단일 머신에 배포할 수 없을 정도로 방대해졌다는 이야기는 들은 적이 없습니다. 이는Web 서비스는 설계 당초부터 책임 분할과 결합 해소를 고려하고 있기때문으로, 각 부분이 독립적으로 배포·확장할 수 있도록 하기 위함입니다. 20 년 전의 SOA(서비스 지향 아키텍처, 마이크로서비스 아키텍처 (Microservices) 등의 변종을 포함) 부터 그렇습니다
二.파티셔닝 (Partitioning)
단일 데이터베이스의 성능이 시스템 확장성의 병목이 되는 것을 피하기 위해, 통상, 논리 데이터베이스 (또는 그 구성 요소, 예를 들어 데이터 테이블) 를 각각의 독립된 부분으로 분할합니다. 이 방식을*파티셔닝 (Partitioning)*이라고 합니다:
A partition is a division of a logical database or its constituent elements into distinct independent parts.
(Partition (database) 에서 인용)
마이크로서비스 아키텍처에서 모놀리식 애플리케이션를 일련의 소형 서비스로 분할하는 것과 마찬가지로, 파티셔닝에 의해 단일 데이터베이스를 일련의 (데이터 규모가) 더 작은 데이터베이스로 분할하고, 각각이 일부 데이터를 처리하며, 공동으로 트래픽을 부담합니다. 주요 이점은 다음과 같습니다:
-
확장성: 단일 데이터베이스의 데이터를 복수 데이터베이스로 분할한 후, 시스템의 확장성은 단일 데이터베이스의 성능에 제한되지 않게 되며, 데이터베이스 계층의 "무한" 확장이 가능해집니다
-
성능: 단일 데이터베이스의 데이터량이 감소하고, 데이터 조작이 더 빨라지며, 복수 데이터베이스의 병렬 조작까지 가능해집니다
-
보안: (분할된) 기밀 데이터에 대해, 더 강력한 보안 제어를 강구할 수 있습니다
-
유연성: 다른 데이터베이스에 대해 (예를 들어 데이터의 중요성에 따라) 다른 모니터링·백업 전략을 채용하고, 비용을削減하며, 관리 효율을 향상시킬 수 있습니다. 또는,不同类型的 데이터에 대해 다른 스토리지 서비스를 선택할 수 있습니다. 예를 들어, 대형 바이너리 콘텐츠를 blob 스토리지에, 더 복잡한 데이터를 문서 데이터베이스에 저장할 수 있습니다
-
가용성: 데이터를 복수의 바구니에 분산시켜, 단일 장애점을 회피할 수 있으며, 단일 데이터베이스의 장애는 일부 데이터에만 영향을 줍니다
구체적으로는, 3 가지 분할 전략이 있습니다:
-
수평 파티셔닝 (Horizontal partitioning, Sharding 라고도 함): 행별로 분할하여, 다른 행을 다른 테이블에 배치
-
수직 파티셔닝 (Vertical partitioning): 열별로 분할하여, 일부 열을 다른 테이블에 배치
-
기능별 파티셔닝 (Functional partitioning, Federation 라고도 부름): 비즈니스 기능별로 분할하여, 비즈니스 영역 내에서 동일한 경계付けられた 컨텍스트 (Bounded Context) 에 속하는 데이터를 함께 배치
물론, 이 3 가지 전략은 모순되지 않으며, 조합하여 사용할 수 있습니다
P.S.도메인 주도 설계 (Domain-Driven Design) 및 경계付けられた 컨텍스트의 상세 정보는, 분산 데이터 관리 (Decentralized Data Management) 참조
三.수평 파티셔닝
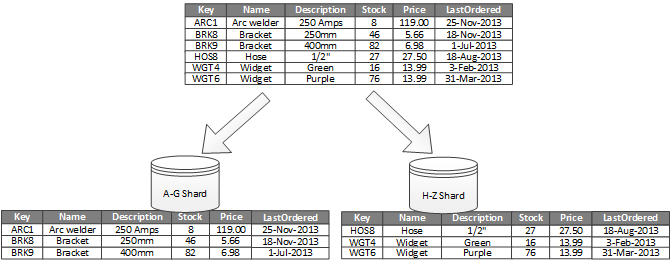
수평 파티셔닝, 즉*샤딩 (Sharding)*입니다. 각 샤드 (shard) 는 원 데이터의 일부이며, 공동으로 완전한 데이터셋을 구성합니다:
A database shard is a horizontal partition of data in a database or search engine. Each individual partition (or server) acts as the single source for this subset of data.
(Shard (database architecture) 에서 인용)
수직 파티셔닝과 비교하여, 수평 파티셔닝의 최대 특징은스키마가保持不变인 것입니다:
Each partition is a separate data store, but all partitions have the same schema.
1 개의 테이블을 가로로 몇 번 잘라, 몇 개의 작은 테이블로 분할하는 것과 같은 것으로, 그들의 테이블 구조 (필드 등) 는 완전히 일치합니다
이 가로 분할은, 단일 데이터베이스가 저장할 필요가 있는 데이터량, 및 부담할 필요가 있는 트래픽/조작을削減하며, 다른 한편으로, 리소스 경합 (contention) 을削減하며, 성능 향상에 도움이 됩니다
shard key 의 선택
구체적인 조작에서는, shard key 를 어떻게 선택할 것인가 (어느 필드의 어느 특징으로 샤딩할 것인가) 가 핵심이며, 부하가 각 샤드에 균등하게 분산되는 것을 가능한 한 보증합니다
균등이란, 각 샤드의 데이터량이 균등한 것을 요구하는 것이 아니라, 트래픽을 균등하게 분할하는 것이 중점입니다 (일부 샤드는 데이터량이 매우 클 수 있지만, 액세스량은 매우 낮을 수 있습니다)
동시에 "핫스팟"의 발생을 회피할 필요가 있습니다. 예를 들어, 사용자 정보를 성의 이니셜로 샤딩하는 것은 실제로는 균등하지 않습니다. 일부 문자는 더 일반적이기 때문입니다. 이 경우, 사용자 ID 의 해시값으로 샤딩하는 것이 더 균등해질 수 있습니다
四.수직 파티셔닝
또 다른 분할 방법은 수직 파티셔닝으로, 일부 열 (필드) 을 다른 테이블로 분할합니다:
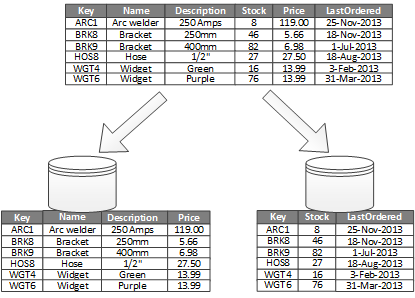
I/O 를削減하고, 성능 비용을 저감하기 위해 자주 사용됩니다. 예를 들어, 사용 빈도에 따라 자주 사용되는 필드와あまり 사용되지 않는 필드를 분리합니다
수평 파티셔닝과 비교하여, 수직 파티셔닝의 중요한 이점은정보를 더 세밀하게 분할하고, 더욱이 몇 가지针对性的인 최적화를 가능하게 하는것입니다. 예를 들어,あまり 변화하지 않는 데이터를 분할하여 캐시에 투입하거나, 사진 등의 대형 바이너리 콘텐츠를 분할하여 단독으로 저장하거나, 일부 기밀 데이터에 대해针对性的인 보안 제어를 강구할 수 있습니다. 다른 한편으로, 세밀한 데이터 분할은 몇 가지 병행 액세스를消除하고, 병행 액세스량을 저감할 수 있습니다
五.기능별 파티셔닝
더욱이, 구체적인 애플리케이션 시나리오에 따라, 비즈니스 기능별로 분할할 수도 있습니다:
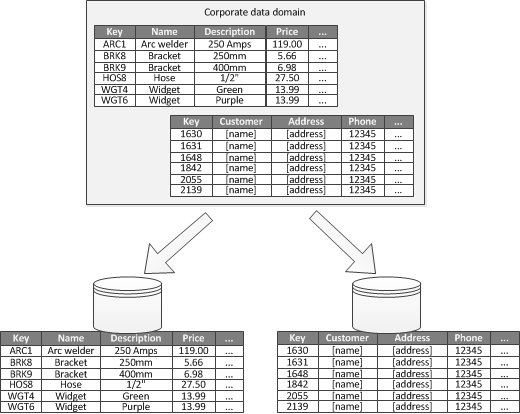
무관한 데이터를 제외하고 (밀접하게 관련된 데이터를 함께 배치), 데이터 분리를 강화하고, 데이터 액세스 성능을 향상시키는 데 도움이 됩니다. 예를 들어, 고객 정보와 상품 재고 정보를 분리합니다
六.파티셔닝의 대가
단일 데이터베이스를 복수 데이터베이스로 분할하면, 데이터베이스의 확장성 난제를 해결할 수 있지만, 몇 가지 새로운 문제도 일으킵니다:
-
테이블 결합 쿼리가 느림: 파티션 횡단 join 을 가능한 한 회피하거나, 또는 병렬 쿼리를 검토
-
전체 테이블 쿼리가 느림: 전량 데이터를 스캔할 필요가 있는 쿼리 조작의 경우, 병렬 최적화가 있어도 느립니다. 수직 파티셔닝, 기능별 파티셔닝에 의해 타겟 파티션을定位하고, 전체 테이블 쿼리를 회피할 수 있습니다. 수평 파티셔닝의 경우, 애플리케이션 계층에서 매핑 테이블을 유지하고, 파티션定位을 고속화할 수 있습니다
-
트랜잭션 조작을 지원하지 않음: 트랜잭션 조작을 애플리케이션 계층에 맡겨 처리
-
부하 불균형으로 인해 파티션 효과가 크게 저하: 모니터링을 추가하고, 분석 예측에 따라 정기적으로 조정하는 것을 검토
확실히, 이러한 문제의 일부에는 매우 아름다운 해결책이 없습니다. 실제 애플리케이션에서는, 특정 시나리오를 향한 트레이드오프가 대부분입니다
참고 자료
-
[How Sharding Works](https://medium.com/ @jeeyoungk/how-sharding-works-b4dec46b3f6)
아직 댓글이 없습니다