서문에
이론상, 신뢰할 수 있는 로드 밸런싱 메커니즘이 있으면, 1 대의 서버를 쉽게 n 대로 확장할 수 있습니다. 그러나, 이 n 대의 머신이 여전히 동일 데이터베이스를 사용하는 경우, 곧 데이터베이스가 시스템의 성능 병목과 신뢰성 병목이 됩니다
그렇다면, 어떻게 데이터베이스의 처리 능력을 향상시킬까요?
리소스의 관점에서 보면, 두 가지 사고방식しか 없습니다:
-
수직 확장: 단일 머신의 구성을 향상시킵니다 (하드디스크, 메모리, CPU 등). 그러나 마찬가지로 단일 머신의 성능 병목에 직면합니다
-
수평 확장: 머신을 추가하고, 수를 단일 데이터베이스 인스턴스에서 복수 인스턴스로 확장합니다
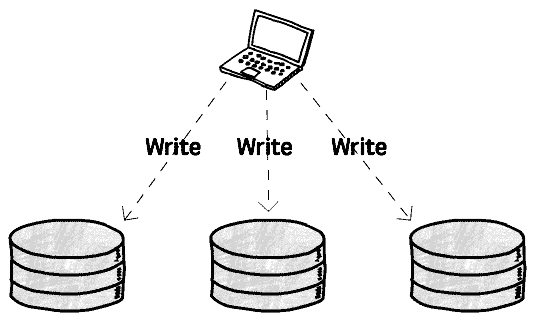
이렇게 보면, 몇 개의 데이터베이스를 추가하고, 애플리케이션 층으로부터의 트래픽을 공동으로 분담하면, 단일 데이터베이스에서 복수 데이터베이스로의 확장이 완료되는 것처럼 보입니다:
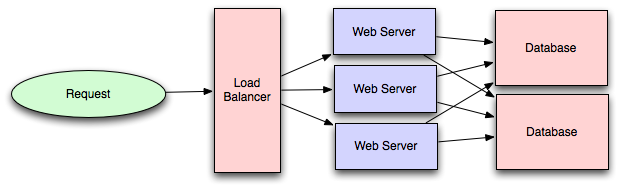
정말로 이렇게 간단할까요?
一.일관성 문제
동일 데이터가 여러 복사본 존재하는 경우, 그 일관성을 어떻게 보장할지 고려해야 합니다
(일관성 패턴 에서 인용)
데이터베이스와 애플리케이션 서비스의 최대 차이는, 애플리케이션 서비스는 스테이트리스일 수 있는 (또는 공유 상태를 외부로 추출할 수 있음. 예를 들어 데이터베이스에 배치) 반면, 데이터베이스 조작은 반드시 스테이트풀하다는 점입니다. 데이터베이스를 확장할 때, 데이터의 일관성을 고려해야 합니다
구체적으로, 일관성은 3 종류로 분류되며, 엄격함은 순차적으로 감소합니다:
-
강일관성 (Strong consistency): 쓰기 후, 즉시 읽을 수 있음
-
최종일관성 (Eventual consistency): 쓰기 후, 최종적으로 읽을 수 있음이 보장됨
-
약일관성 (Weak consistency): 쓰기 후, 읽을 수 있을지 확실하지 않음
二.Replication
따라서, 단일 데이터베이스에서 복수 데이터베이스로 확장하려면, 최소한 하나의 데이터 업데이트 동기화 메커니즘이 필요합니다. 이를*Replication(복제)*라고 합니다:
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
(Replication (computing) 에서 인용)
즉, 복제 (쓰기 조작) 를 통해 복수 데이터 복사본의 정보 일관성을 보장하는 것입니다. 예를 들어, 데이터베이스 인스턴스 A 에 데이터를 쓸 때, 같은 데이터를 인스턴스 B, C, D 등에도 써야 합니다
三.복제 방식
비동기 복제
구체적으로, 쓰기 완료 후, 다른 인스턴스에 데이터 업데이트를 알릴 수 있습니다. 이를 비동기 복제 (Asynchronous replication) 라고 합니다:
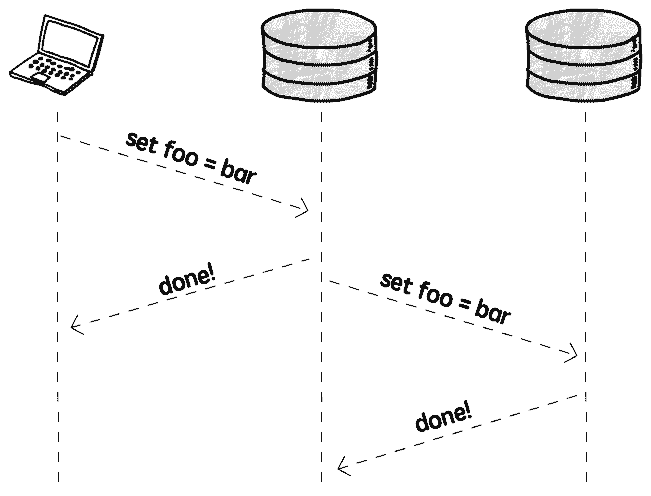
이 모드에서, 클라이언트는 복제 조작의 완료를 기다릴 필요가 없으며, 추가적인 성능 영향이 없습니다. 그러나 문제가 있습니다:
-
데이터丢失 리스크가 있음
-
복제 지연 (Replication lag) 이 존재하므로, 강일관성을 보장할 수 없음
인스턴스 A 가 쓰기 완료 후, 다른 인스턴스에 알리기 전에 다운된 경우, 데이터丢失가 발생합니다:
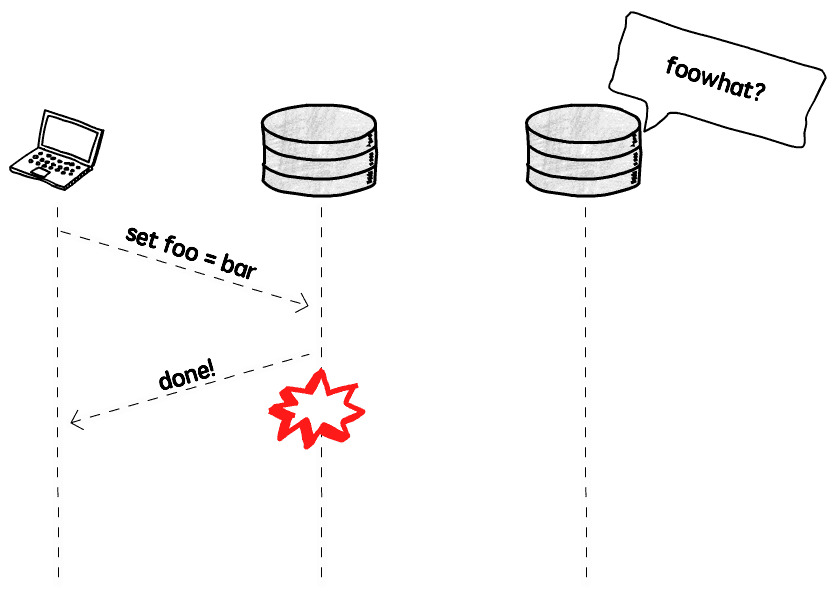
한편, 복제 조작은 비동기로 완료되므로, 데이터 업데이트는 실제로 지체됩니다:
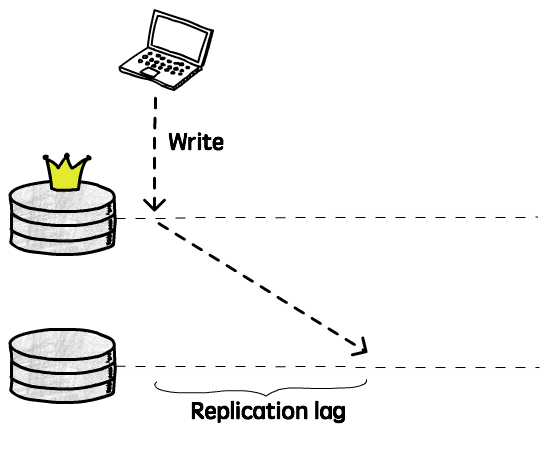
현재 인스턴스에서 이전 쓰기 조작이 완료된 후, 해당 조작이 다른 인스턴스에 적용될 때까지의 시간차를 복제 지연 (Replication lag) 이라고 합니다. 이 기간 동안, 클라이언트가 다른 인스턴스에서 읽는 것은 여전히 구데이터이며, 분명히강일관성의 요구를 만족하지 않습니다 (최종일관성만 보장 가능)
동기 복제
엄격한 일관성 요구를 달성하려면, 동기 복제 (Synchronous replication) 를 고려해야 합니다:
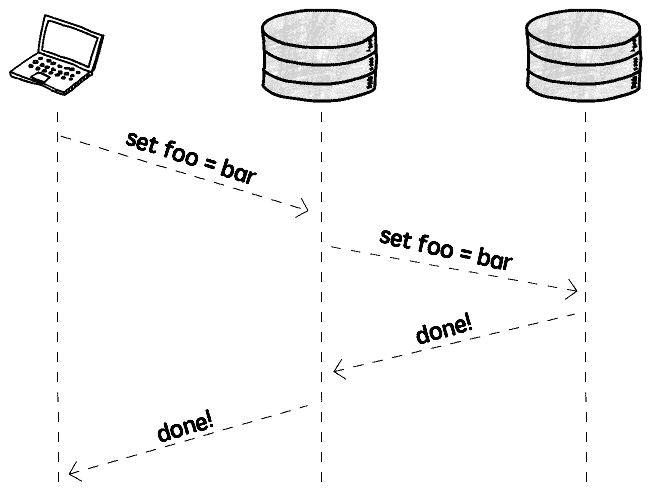
쓰기 조작 발생 시, 즉시 조작을 다른 모든 인스턴스에 동기화하고, 복제 완료 후에야 쓰기 완료로 간주하여, 엄격한 일관성을 확보합니다
그러나동기 복제는 성능과 가용성에 영향을 미치며, 대가는 매우 높습니다:
-
성능 영향: 복제 프로세스 전체의 완료를 기다려야 함
-
가용성 영향: 하나의 인스턴스라도 고장 (네트워크 등의 이유) 이 나면, 쓰기 조작 전체가 실패함
게다가, 데이터베이스 인스턴스 수가 많을수록, 이 두 방면의 영향은 커집니다
준동기 복제
特殊的으로, 두 가지 방식을 결합하여 사용할 수 있습니다. 이를 준동기 복제 (Semi-synchronous replication) 라고 합니다:
Some databases and replication tools allow us to define a number of followers to replicate synchronously, and the others just use the asynchronous approach. This is sometimes called semi-synchronous replication.
즉, 일부 데이터베이스 인스턴스에 동기 복제를 요구하고, 나머지는 비동기 복제를 사용합니다
P.S.PostgreSQL 은 이 모드를 지원합니다
四.토폴로지 구조
토폴로지 구조상, 복제는 3 종류로 분류할 수 있습니다:
-
단일 주구조 (Single leader replication)
-
복수 주구조 (Multi leader replication)
-
무주구조 (Leaderless replication)
단일 주구조
가장 일반적인 1 주 다종 구조입니다:
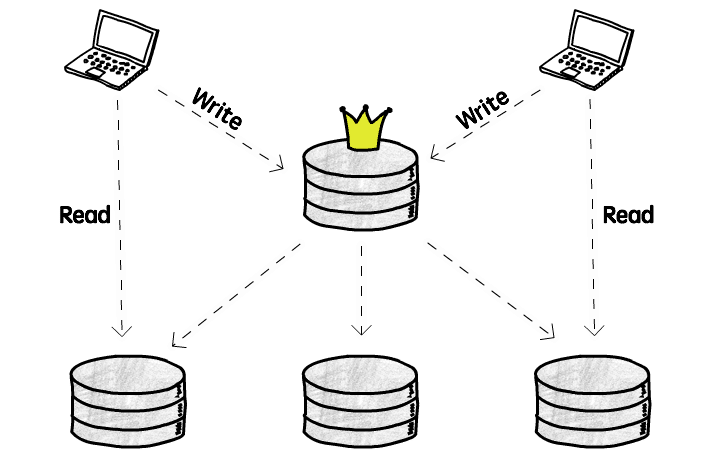
이 구조에서, 쓰기 조작 (추가/삭제/변경) 은 주庫에서만 발생하며, 주庫가 쓰기 조작을 다른 모든 종庫에 복제합니다. 종庫는 읽기 조작 (조회) 만 지원합니다
모든 클라이언트가 같은 庫에 쓰기 때문에, 쓰기 조작 충돌의 큰 문제를 잘 회피할 수 있습니다. 그러나 주의가 필요합니다:
-
쓰기 조작의 압력을担는 것은 여전히 단일 庫: 쓰기 집중 (write-intensive) 의 애플리케이션에는 적합하지 않음. 그러나 다행히 대부분의 애플리케이션은 읽기 집중입니다
-
주庫への 액세스 지연 문제: 주庫는 1 개しか 없으며, 특정 지리적 위치에 배치해야 하므로, 일부 영역에서 쓰기 조작 (주庫への 액세스) 을 발행하면, 높은 지연을 부담해야 함
더 나쁜 상황으로, 주庫가 다운된 경우, 즉시 종庫 중에서 후계자를 선출하여, 주庫의职责을担아, 이 메커니즘의 정상적인 가동을 보장해야 합니다
그러나, 이고장 전환 전략은 그다지 쉽게 구현할 수 없습니다. 난점은 다음과 같습니다:
-
주庫가 정말로 다운된 것을 어떻게 확정하는가?
-
신임 주庫를 어떻게 선택하는가?
-
쓰기 조작을 신임 주庫에 어떻게 전송하는가?
실제, 고지연과 사용 불가를 구분할 수 없으며, 일반적으로 타임아웃하면 사용 불가로 간주합니다 (정말로 다운되었는지 여부와 관계없이). 그 후, 고장 전환预案을 기동하고, 신임 주庫의 선택을 시작합니다
1 개 선출하는 것은 어렵지 않습니다. 핵심은, 선택된 신임 주庫가 다른 모든 종庫에 그 지위를 인정받아야 한다는 것입니다 (즉 합의 문제). 예를 들어, 사전에接班順序를 결정해 둡니다
신임 주庫가 선출된 후, 모든 쓰기 조작을 전송해야 합니다. 예를 들어, 라우팅 제어를 허용하기 위해, 배포 메커니즘을 1 층 추가합니다
게다가, 비동기 복제를 채택한 경우, 구주庫가 회복한 후, 다른 종庫에 복제되지 않은 데이터와, 오프라인 기간 중에 신임 주庫가 쓴 데이터가 충돌할 가능성이 있습니다. 이 경우, 일반적으로 LWW(last-write-win) 전략을 채택하고, 구데이터를 직접 폐기하지만, 마찬가지로 리스크가 존재합니다
特殊的으로, 흥미로운 상황으로 구주庫가 회복하여 자신이 아직 주庫라고 생각하는 경우, 분열 (Split-brain) 이 발생합니다:
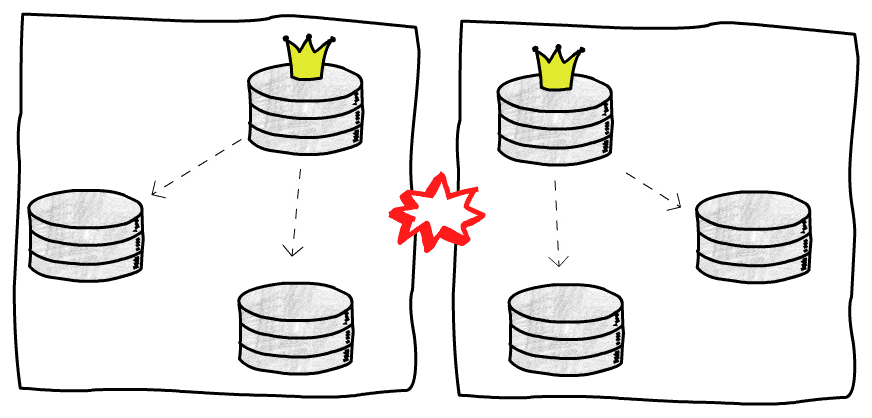
P.S.네트워크 장애도 이러한 상황을 초래할 수 있습니다. 예를 들어 2 개의 클러스터 간에 네트워크 장애가 발생하여, 서로 액세스할 수 없게 되고, 모두 상대 팀이 다운되었다고 생각하여, 각각에서 대선 을 시작합니다
간단한 처리 방법은 STONITH(Shoot The Other Node In The Head) 로, 복수의 주庫가 존재하는 것을 발견하면, 직접 1 개를 정지합니다
복수 주구조
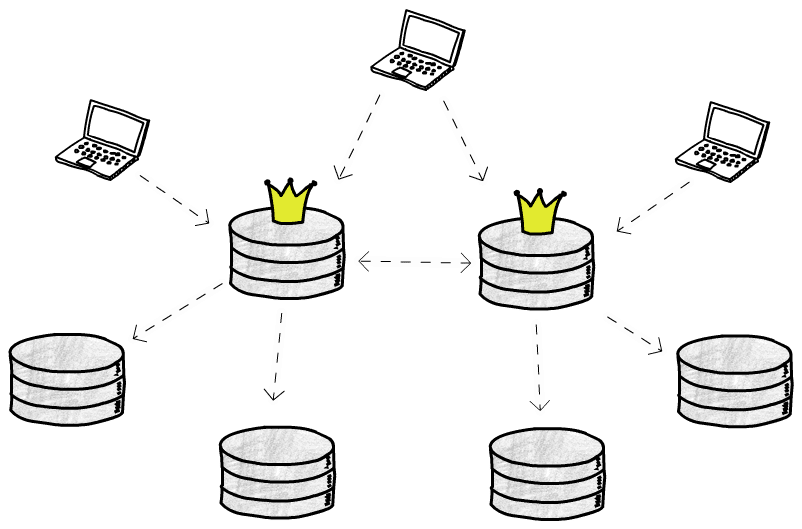
이제 쓰기 가능한 주庫가 복수 있어, 쓰기 조작을 분담할 수 있고,多地에配備할 수도 있습니다. 단일 주구조의 2 개 문제는 쉽게 해결됩니다. 그러나, 큰 문제가 발생했습니다
쓰기 조작이 동시에 (비동기 복제의) 복수의 庫에서 발생할 수 있으므로, 쓰기 충돌을 어떻게 해결할지를 고려해야 합니다. 일반적으로 3 가지 사고방식이 있습니다:
-
충돌 회피: 예를 들어 콘텐츠 특징으로 庫를 나누어存储하고, 서로 간섭하지 않음. 예를 들어 국내 국외의 2 개 주庫에 대해, 모든 국내 데이터への 쓰기 조작이 국내 주庫에 떨어지고, 모든 ��외 데이터への 쓰기 조작이 국외 주庫에 떨어지는 것을 보장할 수 있으면, 충돌은 존재하지 않습니다
-
LWW(last-write-win) 전략: 각 쓰기 조작에 타임스탬프를 붙이고, 최신 버전만 유지
-
사용자에게 해결을 위임: 충돌을 기록하고, 애플리케이션이 사용자에게 제시하며, 사용자가 어느 것을 보존할지 결정
P.S.일부 데이터베이스 (CouchDB 등) 는, 모든 충돌 값을 쓰고, 읽기 시 일련의 값을 반환하는 것을 지원합니다
게다가, 복수 주구조 하의 또 하나의 난제는 DDL(Data Definition Language) 의 복제입니다. 즉 Schema 에 대한 쓰기 조작. 구체적은 DDL replication 참조
무주구조
물론, 주庫를 구분하지 않는 구조도 있으며, 모든 庫가 읽기 쓰기 가능합니다
「전주구조」처럼 보이므로, 예측 가능한 것으로, 쓰기 충돌은 매우 일반적이 됩니다. 따라서, 전략을 조정하여「전주구조」가 되는 것을 회피해야 합니다:
-
쓰기: 클라이언트는 동시에 복수의 데이터베이스에 쓰고, 몇 개 성공하면 쓰기 완료로 간주
-
읽기: 클라이언트는 동시에 복수의 데이터베이스에서 읽고, 각 庫가 데이터와 그 버전 번호를 반환하며, 클라이언트가 버전 번호에 기반하여 어느 데이터를 채택할지 결정
주庫가 없다는 것은, 고장 전환을 고려할 필요가 없음 을 의미하며, 단일 庫 고장은 전체에 영향이 없고, 신임 주庫를 선택하는 다양한 번거로운 문제는 존재하지 않게 됩니다
동시에, 주庫가 없다는 것은 데이터 동기화 메커니즘이 없어지고, 읽은 구값을 자동으로 수정할 수 없음 을 의미합니다:
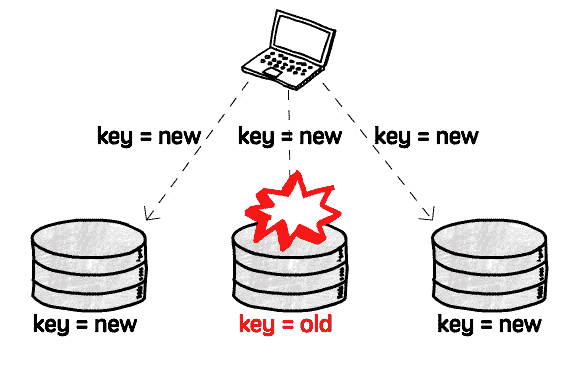
따라서, 추가의 오류 수정 메커니즘이 필요합니다. 클라이언트가 구값을 읽었을 때 신값을 다시 씁니다 (Read repair 라고 불립니다). 또는, 독립된 프로세스가专门负责 구값을 찾아내고 수정합니다
또 하나의 핵심 요소는, 읽기/쓰기 조작의 목표 庫의 수량입니다. 최소한 몇 개의 庫への 쓰기 성공 후, 최소한 몇 개의 庫에서 성공적으로 읽어야 신값을 읽을 수 있음이 보장될까요?
w 개의 庫への 쓰기가 성공하고, 이어 r 개의 庫의 데이터를 성공적으로 읽은 경우, w + r > 庫의 총수 를 만족해야 합니다
五.구체적 구현
구체적으로, 몇 개의 데이터를 1 개의 庫에서 다른 庫로 복사하는 3 가지 방식이 있습니다:
-
스테이트먼트 기반의 복제: 쓰기 조작 스테이트먼트를 그대로 다른 庫에 전송하여 실행
-
로그 전송식 복제: 물리 복제라고도 불리며, 데이터베이스 로그를 다른 庫에 전달하고, 로그에서 완전히 일관된 데이터를 회복. 예를 들어 PostgreSQL 이 제공하는 Streaming Replication
-
행 기반의 복제: 논리 복제라고도 불리며, 복제 전용의 로그를 전달하고, 행마다 복제. 예를 들어 MySQL 이 제공하는 Mixed Binary Logging Format
스테이트먼트마다 복제하는 문제점은, 모든 스테이트먼트의 실행 결과가 확정であるとは限らない 것입니다. 예를 들어 CURRENT_TIME(), RANDOM() 입니다. 일부 데이터베이스는 복제 시 이러한 값을 치환하지만, 그래도 트리거 및 사용자 정의 함수가 확정한 실행 결과를 갖는 것을 보장할 수 없습니다. 한편, 트랜잭션 조작이 모든 데이터베이스 상에서 아톰성을 확보해야 합니다. 모두 완료하거나, 모두 전혀 실행되지 않거나 중 하나입니다
로그 전송식 복제는 데이터의 완전한 일관성을 보장할 수 있지만, (스토리지 엔진 향의) 로그는 일반적으로, 데이터베이스 버전을 넘어 사용할 수 없습니다. 다른 버전의 데이터베이스에서는, 데이터의 물리存储 방식이 변화할 가능성이 있기 때문입니다. 게다가, 로그 전송은 복수 주구조에는 적합하지 않습니다. 복수의 로그를 1 개로 머지할 수 없기 때문입니다
행 기반의 복제는 전 2 가지 방식의 조합으로, 복제 전용의 로그를 채택하고, 스토리지 엔진과의 결합이 없어지므로, 따라서 데이터베이스 버전을 넘어 사용할 수 있습니다. 스테이트먼트마다의 복제와 비교하여, 행마다의 복제는 더 많은 정보를 기록할 필요가 있습니다 (예를 들어, 1 개의 스테이트먼트가 100 행에 영향한 경우, 행마다 모두 기록할 필요가 있습니다)
아직 댓글이 없습니다