서문에
JavaScript 의 문자열 처리는 어려워 보이지 않지만, emoji 를 만날 때까지:
[caption id="attachment_1801" align="alignnone" width="626"]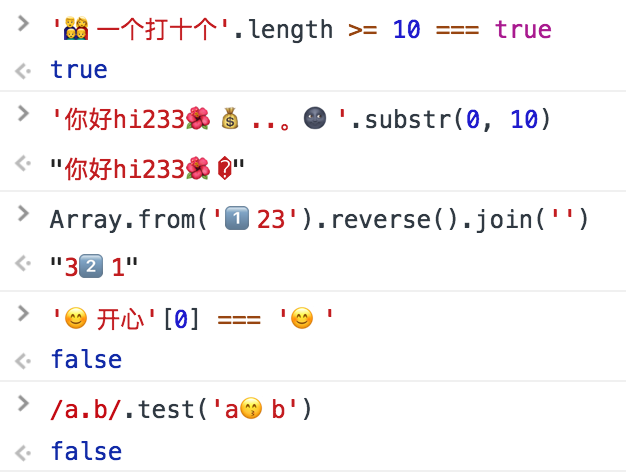 javascript-emoji-issues[/caption]
javascript-emoji-issues[/caption]
??무슨 일이 일어난 것인가?도대체 어떻게 된 것인가?
Unicode 부호화부터 설명해야 합니다……
一.Unicode 부호화
The Unicode codepoint range goes from U+0000 to U+10FFFF which is over 1 million symbols, and these are divided into groups called planes. Each plane is about 65000 characters (16^4). The first plane is the Basic Multilingual Plane (U+0000 through U+FFFF) and contains all the common symbols we use everyday and then some. The rest of the planes require more than 4 hexadecimal digits and are called supplementary planes or astral planes.
즉, Unicode 가 지원하는 부호화 범위는 U+0000 에서 U+10FFFF 로, 100 만 개가 넘는 기호에 대응할 수 있습니다(0x10FFFF === 1114111). 이러한 기호들은 16 개의*평면(panel)*으로 그룹화되어 있어, 각 평면에 65536(16^4 === 65536)개가 배치됩니다
그 중에서,常用 기호들은 모두 첫 번째 평면(U+0000 에서 U+FFFF)에 배치되어 있으므로, *기본 다언어 평면(Basic Multilingual Plane, 약칭 BMP)이라고 불립니다. 나머지 평면 중의코드 포인트 값(codepoint, 즉 기호에 대응하는 Unicode 부호화 값)*은 모두 4 자리(16 진수)보다 크며, *보조 평면(supplementary plane)*이라고 불립니다
P.S. 보조 평면에는매우 대단해 보이는이름도 있어, astral plane(성계?성계 위면?)이라고 불립니다
I have no idea if there's a good reason for the name "astral plane." Sometimes, I think people come up with these names just to add excitement to their lives.
더욱이, 기본 다언어 평면 내의 65536 개 위치의 입주율은 100% 가 아니며, 일부 위치를专门 비워 불시의 수요에 대비하고 있습니다. 예를 들어, 새로운 특수한 의미의 기호를 추가하거나 확장하기 위해서입니다
예를 들어 UTF-16 중의*서로게이트 페어(surrogate pairs)*의 개념으로, 2 개의 4 자리(16 진수)작은 코드 포인트 값으로 1 개의 큰 코드 포인트 값(4 자리보다 큼)을 나타냅니다. 기본 다언어 평면에서 보조 평면으로의 매핑의 일종입니다. 이것이 가능한 이유는 다음과 같습니다:
基本多言語平面内、U+D800 から U+DFFF までのコードポイント区間は Unicode 文字にマッピングされないよう永久に保留されています。UTF-16 はこの保留された 0xD800-0xDFFF 区間のコードポイントを利用して補助平面の文字のコードポイントを符号化します。
二.JavaScript 중의 Unicode
JS 중의 Unicode 문자에는 3 종류의 표현 방법이 있습니다:
'A' === '\u0041' === '\x41' === '\u{41}'
그 중에서 \x 는 U+0000 에서 U+00FF 까지만 사용되며, \u 는 임의의 Unicode 문자(U+0000 에서 U+10FFFF)에 적용할 수 있지만, 4 자리보다 큰(U+FFFF 보다 큼)경우, 꽃괄호({})로 16 진수 시퀀스를 감싸야 합니다:
The \x can be used for most (but not all) of the Basic Multilingual Plane, specifically U+0000 to U+00FF. The \u can be used for any Unicode characters. The curly braces are required if there are more than 4 hexadecimal digits and optional otherwise.
주의, \u{} 이스케이프 구문은 ES 2015 에서 정의되었으며, UnicodeEscapeSequence 라고 불립니다. 이전에는 2 개의 작은 Unicode 로 1 개의 큰 Unicode 를 나타냈습니다. 예를 들어:
'' === '\u{1F4A9}'
'' === '\uD83D\uDCA9'
\uD83D\uDCA9 가 서로게이트 페어로, <H,L> 의 형태를 하고 있으며, 이둘의 변환 관계는 다음과 같습니다:
let C, L, H;
C = 0x1F4A9;
// 公式:大 Unicode 转代理对儿
H = Math.floor((C - 0x10000) / 0x400) + 0xD800;
L = (C - 0x10000) % 0x400 + 0xDC00;
[H, L].map(v => '\\u' + v.toString(16).toUpperCase()).join('')
"\uD83D\uDCA9"
더욱이, JS 에서는 16 비트 부호 없는 정수 값을 1 문자로 간주하므로, 1 개의 emoji 는 여러 문자로 간주될 수 있습니다:
The phrase code unit and the word character will be used to refer to a 16-bit unsigned value used to represent a single 16-bit unit of text.
Unicode character only refers to entities represented by single Unicode scalar values: the components of a combining character sequence are still individual "Unicode characters", even though a user might think of the whole sequence as a single character.
P.S. JavaScript 의 Unicode 지원 및 ES 규범의 관련 내용에 대해서는, JavaScript's internal character encoding: UCS-2 or UTF-16? 참조
正規表現中의 Unicode
큰 Unicode(U+FFFF 보다 큼)가 JS 중에서 2 개의 작은 Unicode(서로게이트 페어)로 표현된다면, 당연히 이러한 정규 표현식을 쓰고 싶어집니다:
> /[\uD83D\uDCA9-\uD83D\uDE0A]/.test('')
Uncaught SyntaxError: Invalid regular expression: /[\uD83D\uDCA9-\uD83D\uDE0A]/: Range out of order in character class
이러한 range 를 식별할 수 없다는 오류가 발생하지만, 어떻게 정규 표현식으로 큰 Unicode 문자 범위를 기술할 수 있을까요?
JS 는 u flag 를 제공하여 이 문제를 해결합니다:
u Unicode; treat pattern as a sequence of Unicode code points
/[\uD83D\uDCA9-\uD83D\uDE0A]/u.test('')
/[-]/u.test('')
유사하게, .(닷은 임의의 문자에 매치)가 서로게이트 페어 형태의 큰 Unicode 에 매치하고 싶다면, u flag 를 활성화해야 합니다:
> /foo.bar/.test('foobar')
false
> /foo.bar/u.test('foobar')
true
P.S././u 는 서로게이트 페어 형태의 emoji 에만 매치할 수 있으며, 다른 형태는 불가능합니다. 예를 들어:
> /foo.bar/u.test('foo2??bar')
false
P.S. 더 많은 관련 예제에 대해서는, Astral ranges in character classes 참조
fromCodePoint 과 fromCharCode
String.fromCodePoint 와 String.fromCharCode 의 차이는, 전자가 더 큰 범위의 16 진수 Unicode 부호화를 지원한다는 것입니다. 예를 들어:
> String.fromCodePoint(0x1F4A9)
""
> String.fromCharCode(0x1F4A9)
"?"
하지만 fromCodePoint 는 ES 2015 규범에서 정의되었으며, 호환성은 fromCharCode 보다 좋지 않습니다. 0x0000-0xFFFF 범위의 65536 개 Unicode 문자에 대해서는, fromCharCode 의 사용을 권장합니다
三.emoji 부호화
Unicode 와 유사하게, emoji 도 일종의 부호화 규칙이며, 대응하는 규범이 있고, 많은 버전이 존재합니다:
Emoji 12.0
Emoji 11.0
Emoji 5.0
Emoji 4.0
Emoji 3.0
Emoji 2.0
Emoji 1.0
그 중에서 12.0 은 2019 년에 릴리스 예정이며, 최신의 11.0 은 2018-02-07 에 릴리스되었습니다
HTML, CSS 규범과 유사하게, 신버전 규범에서 추가된 emoji 가 모두 구현된 것은 아니며, HTML, CSS 보다 심각한 호환성 문제에 직면하고 있습니다:
-
규범 버전:emoji 규범의 릴리스가 빈번하며, 여러 버전이 공존
-
플랫폼 차이:Web 브라우저 환경 외에, emoji 는 플랫폼의 네이티브 지원(각종 화면 표시 디바이스)에 의존
-
Unicode 에의 의존:emoji 는 Unicode 를 기초로建立되었으며, Unicode 규범에 의존
예를 들어, SMS 에서 Web 페이지 입력 상자에 복사 붙여넣기하면, emoji 가 표시되지 않거나 문자 깨짐이 발생할 수 있습니다. native 와 Web 브라우저가 지원하는 emoji 규범 버전 또는 구현 정도에 차이가 있기 때문입니다. 더욱이, Unicode 신규범은 이미 정의된 emoji 규범과 충돌할 가능성이 있으며, 이 경우 당연히 emoji 규범이 양보해야 합니다:
Unicode 12.0 is the new version of the Unicode Standard planned for release in March 2019. See Emoji 12.0 for a more complete list of potential emojis for 2019.
Note: All emojis listed throughout 2018 are candidates only, and subject to change before a final release.
emoji 가 직면하는 환경은 얼마나 엄격할까요? 그림과 같습니다:
[caption id="attachment_1802" align="alignnone" width="625"] emoji-unicode-platform[/caption]
emoji-unicode-platform[/caption]
emoji 규범 자체로 돌아가면, 이렇습니다:
1F600 ; emoji ; L1 ; secondary ; x # V6.1 () GRINNING FACE
1F48F ; emoji ; L1 ; none ; j # V6.0 () KISS
왼쪽 끝은 Unicode 코드 포인트 값으로, Unicode 규범에 정상적으로 등록되면, U+1F48F 는 KISS 이모티콘에 대응합니다:
> '\u{1F48F}'
""
이렇게 Unicode 와 일대일로 대응하는 emoji 외에, Unicode 대가족에加入하는 것 외에도, 몇 가지 특수한 emoji 가 있습니다:
-
variation selector-16:불가시 문자(
U+FE0F)로, 그 앞의 문자를 emoji 로 표시해야 함을 나타냅니다 -
zero width joiner:제로 폭 접속 부호로, 제로 폭 스페이스(
U+200D)이며, 여러 emoji 를 1 개의 emoji 로 결합하는 데 사용됩니다 -
tone modifier:피부색 수식으로, 일종의 구문으로, 앞의 emoji 의 피부색을 변경할 수 있습니다. 구문 형식은
<emoji>\ud83c[\udffb-\udfff]로,U+D83C뒤에 다른 값을 붙여 다른 피부색 제어를 나타냅니다 -
keycap:키캡 기호로, 키캡 스타일의
0-9,#와*로,U+20E3로 끝납니다 -
unofficial emoji flag:매우 비규칙적인 국기 emoji 가 존재하며, 검은 깃발(
U+1F3F4)로 시작하여, 취소 기호(U+E007F)로 끝납니다
예를 들어:
// \ufe0f 让黑心字符显示成 emoji,连续两个也没关系
'???' === '\u2764\ufe0f\ufe0f'
'\u2764\ufe0f' === '??'
'\u2764' === '?'
// 零宽连接符\u200d 合成复杂表情, + ?? + + = ?????
'?????' == '\ud83d\udc69\u200d\u2764\ufe0f\u200d\ud83d\udc8b\u200d\ud83d\udc69'
// 肤色修饰,黑 baby、白 baby
'' === '\ud83d\udc76\ud83c\udfff'
'' === '\ud83d\udc76\ud83c\udffb'
// 键帽样式
'#??' === '\u0023\ufe0f\u20e3'
// 非官方国旗
'' ==='\ud83c\udff4\udb40\udc67\udb40\udc62\udb40\udc73\udb40\udc63\udb40\udc74\udb40\udc7f'
四.JavaScript 里的 emoji
그렇다면JS 중에서, 1 개의 emoji 는 도대체 몇 개의 Unicode 문자를 포함하고 있는가?
> '?'.length
1
> ''.length
2
> '1??'.length
3
> ''.length
4
> '???'.length
11
> ''.length
14
1 개의 emoji 리터럴의 길이는 1 에서 14(더 긴 것이 존재할 가능성도 있습니다)까지 다양합니다……따라서, 이러한 상황이 발생합니다:
> '???我们是一家人'.slice(0, 1)
"?"
> '???我们是一家人'.substr(0, 2)
""
slice(0, 1) 로 첫 번째 emoji 를 잘라내려고 기대했지만, 표시할 수 없는 문자를 얻어버렸고, 심지어 substr(0, 2) 로一家 4 구에서 Man()을 분해해 버렸습니다……이것은 어떻게 하면 좋은가?
일부 emoji 에 대해서는, 매우 간단한 처리 방법이 있습니다. Array.from 입니다:
> Array.from('').length
1
문자열을 배열로 변환할 때 서로게이트 페어를 함께 유지하므로, length 는 정확해지지만, 이 방법은 만능이 아닙니다:
> Array.from('???').length
7
P.S. 유사하게, Unicode 부호화 변환을 지원하는 bestiejs/punycode.js 에도 유사한 문제가 있습니다:
> punycode.ucs2.decode(' ').length
1
> punycode.ucs2.decode('???').length
7
즉, JS 의 Unicode 에 대한 네이티브 지원만으로는, emoji 를 포함한 문자열을 올바르게 처리할 수 없습니다. 따라서, 일부 장면에서 문제에 직면합니다:
-
폼 검증의 글자 수 제한
-
기사 요약 잘라내기
-
문자열 반전
-
문자 단위 처리
-
정규 표현식 매치
-
……기타 emoji 를 포함한 텍스트 처리 장면
예를 들어:
> '???一个打十个'.length >= 10 === true
true
> '你好 hi233..。'.substr(0, 10)
"你好 hi233?"
> Array.from('1??23').reverse().join('')
"32??1"
> '开心'[0] === ''
false
> /a.b/.test('ab')
false
P.S. JavaScript 중의 Unicode 의 더 많은 문제에 대해서는, JavaScript has a Unicode problem 참조
五.해결 방안:emoutils.js
위에 열거한 일련의 문제를 해결하려면, emoji 를 식별하는 방법을 생각할 수밖에 없습니다. 현재(2018/09/15)그런 도구 라이브러리는 존재하지 않는 것 같습니다
손으로 만듭니다. 詞法分析 과 유사하게, 문자 단위로 매치하여, emoji 부호화 규칙에 부합하는 Unicode 조합을 골라냅니다. 상세한 내용은 아래 소스 코드 참조
Github 주소:https://github.com/ayqy/emoji-utils
온라인 Demo(테스트 case):https://ayqy.github.io/emoji/index.html
API
6 개의 심플한 API 를 제공합니다:
// 是不是一个 emoji
isEmoji(str)
// 是否包含 emoji
containsEmoji(str)
// 字符串转 Unicode 数组
str2unicodeArray(str)
// 计算长度
length(str)
// 子串截取
substr(str = '', start = 0, len = Infinity)
// 字符串转数组,相当于 split('')
toArray(str)
내부에서 공개되지 않은 방법:
// 尝试匹配开头的 emoji,失败返回''
matchOneEmoji(str, matched = '')
欠陥
하지만, 이러한 도구 함수들은100% 신뢰할 수 없습니다. 왜냐하면:
Not all browsers, UIs, etc even render ????? as a single symbol. The code assumes the joiners are used between characters appropriately which could be very problematic.
따라서, emoutils.js 의구현은 3 가지 가정에 기반하고 있습니다:
-
모든 서로게이트 페어는 emoji 이다(실제로는, 일부 서로게이트 페어는 emoji 가 아니다)
-
피부색 제어는 모든 emoji 에 유효하며, emoji 에만 유효하다(일반 텍스트 기호에는 무효)
-
joiner 로 연결된 emoji 는 모두 1 개로 간주한다. 표시상에서 1 개의 emoji 로 합성될 수 있는지 여부는 묻지 않는다
첫 번째 가정에 대해, 서로게이트 페어 형태는 반드시 emoji 라고 할 수 없으며, 순수한 텍스트일 수도 있습니다. 예를 들어:
'\ud835\udc00' === ''
뒤의 두 가정도 몇 가지 badcase 를 일으킵니다. 예를 들어(Chrome Console 환경):
// 尝试制造黑色笑脸,未遂
'\ud83d\ude0a\ud83c\udfff' === ''
// 尝试人工合成新物种,失败
'\u0023\ufe0f\u20e3\u200d\ud83d\ude0a' === '#???'
'\ud83d\ude0a\u200d\ud83d\ude0a' === '?'
이러한 case 들은 모두 1 개의 emoji 로 식별되지만, Chrome Console 환경에서의 표시는 2 개입니다. 왜냐하면:
-
emoji 부호화의 구문 규칙에 부합
-
하지만 합법적인 emoji 라고 할 수 없다
-
합법적이라도, 현재 플랫폼이 지원한다고 할 수 없다
emoutils.js 는 첫 번째 점을 만족하는 것을 독립 표시의 합법적인 emoji 로 가정하며, emoji 규범 버전 및 플랫폼 지원성을 고려하지 않았기 때문에, 이러한 badcase 가 존재합니다. badcase 가 가져올 수 있는 영향은:
-
isEmoji/containsEmoji()가''와 유사한 텍스트 문자를 오판단 -
length()가 실제 표시 문자 길이보다 작다 -
substr()/toArray()가 실제 예상과 일치하지 않는다
따라서 이 도구 라이브러리가 식별할 수 있는 문자 세트는 emoji 의 초집합으로, 추가된 일부는 서로게이트 페어 형태의 텍스트, 및 emoji 부호화 규칙에 부합하지만 emoji 규범 중에서 정의되지 않은 문자 시퀀스입니다. 그럼에도 불구하고, 실제 응용에서는 대다수의 장면에 대응하기에 충분합니다
P.S. emoji 를 정확하게 처리해야 하는 장면에 대해서는, emoji-regex 의 검토를 권장합니다
참고 자료
-
[Finally moving past "".length === 2](https://medium.com/ @jtenclay/finally-moving-past-length-2-86054156b180)
-
Can you use String.fromCodePoint just like String.fromCharCode
아직 댓글이 없습니다