설계 사상
무엇을 표현하려 하는가? React는 애플리케이션을 어떻게 이해하는가?
애플리케이션은 상태 머신이며, 상태가 뷰를 구동합니다.
v = f(d)
v는 뷰(View)
f는 컴포넌트(Component)
d는 데이터/상태(Data/State)
함수형 프로그래밍(FP)과는 어떤 관계인가?
함수형 사고를 프론트엔드에 도입하여, PureComponent의 조합으로 UI를 구현합니다.
가장 큰 장점은 UI를 예측 가능하게 만든다는 것입니다. 동일한 f에 동일한 d를 입력하면 반드시 동일한 v를 얻게 됩니다.
각각의 f를 개별적으로 테스트할 수 있으며, 이들을 조합했을 때 문제가 없음을 보장합니다. 이는 이론적으로 컴포넌트의 품질이 신뢰할 수 있음을 확정하며, 조합된 전체 애플리케이션의 UI 또한 신뢰할 수 있게 합니다.
목표
어떤 문제를 해결하려 하는가? 정체성은 무엇인가?
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
UI 구축을 위한 컴포넌트화된 솔루션을 제공하는 것입니다.
어떤 문제를 해결할 수 있는가?
-
컴포넌트화
-
UI 신뢰성
-
데이터 중심의 뷰 구동
성능 목표
For many applications, using React will lead to a fast user interface without doing much work to specifically optimize for performance.
비용과 수익의 균형점을 찾아, 의도적인 성능 최적화 없이도 성능이 괜찮은(최적은 아니더라도) 애플리케이션을 작성할 수 있게 합니다.
실제로 React가 수행하는 성능 최적화는 주로 다음과 같습니다:
-
이벤트 위임, 전역에서 하나의 이벤트 리스너 관리
-
자체적인 캡처링/버블링 구현으로 IE8 등의 버그를 해결
-
객체 풀(Object Pool)을 통해 이벤트 객체를 재사용하여 가비지 컬렉션(GC) 감소
-
-
DOM 조작 통합 및 횟수 감소
하지만 어떤 경우에도 숙련된 개발자가 직접 작성한 네이티브 DOM 조작 버전보다는 성능이 떨어질 수밖에 없습니다.
가상 DOM
어떤 방식으로 문제를 해결하는가?
DOM 트리 위에 추가적인 추상화 계층을 더합니다.
컴포넌트화 방식: 컴포넌트 클래스 템플릿, 생명주기 훅(hook), 데이터 흐름 방식, 로컬 상태 관리 등을 제공합니다.
런타임: 가상 DOM 트리로 컴포넌트를 관리하며, 실제 DOM 트리와의 매핑 관계를 구축하고 유지합니다.
가상 DOM은 어떤 역할을 하는가?
-
일괄 처리(Batching)를 통한 성능 향상
-
Diff 연산 비용 절감
-
"데이터 바인딩" 구현
구체적인 구현
JSX -> React Element -> 가상 DOM 노드 ..> 실제 DOM 노드
설명 객체
-
컴파일 시점에 JSX를 번역하여
createElement호출로 바꿉니다. -
createElement를 실행하여 React Element 설명 객체를 얻습니다. -
설명 객체를 바탕으로 가상 DOM 노드를 생성합니다.
-
가상 DOM 노드의 상태를 통합하여 실제 DOM 노드를 생성합니다.
가상 DOM 트리의 노드 집합은 실제 DOM 트리 노드 집합의 상위 집합이며, 추가된 부분은 사용자 정의 컴포넌트(Wrapper)입니다.
구조적으로 내부 트리 레이아웃은 숲(Forest) 형태이며, instancesByReactRootID에서 관리됩니다:
-
기존 앱에 React를 도입할 때 여러 개의 루트 DOM 노드가 존재할 수 있습니다.
-
순수 React 애플리케이션의 경우 숲에는 보통 하나의 트리만 존재합니다.
단방향 데이터 흐름
폭포수 모델
props와 state로 컴포넌트들을 조직하며, 컴포넌트 간의 데이터 흐름은 폭포와 유사합니다.
데이터는 항상 조상에서 후손으로(루트에서 잎으로) 흐르며, 역류하지 않습니다.
-
props: 파이프라인 -
state: 수원(Water source)
단방향 데이터 흐름은 상태 폐기 메커니즘에 의해 결정되며, 구체적으로 다음과 같이 나타납니다:
-
상태 변화로 인한 데이터 및 UI 변화는 오직 하위 컴포넌트에만 영향을 미칩니다.
-
뷰를 렌더링할 때는 아래로 흐르고, 폼 상호작용은 위로 전달되어 다시 아래로 흐르는 렌더링을 유발할 수 있습니다.
단방향 데이터 흐름은 뷰 렌더링 과정에 대한 것으로, 후손의 state가 어떻게 변하든 조상에게 직접 영향을 주지 않습니다. 조상의 state를 업데이트하도록 알리지 않는 한 말이죠.
state와 props
state는 최소한의 가변 상태 집합이며, 특징은 다음과 같습니다:
-
프라이빗(Private). 상위가 아닌 컴포넌트 자신이 완전히 제어합니다.
-
가변적(Mutable). 시간에 따라 변합니다.
-
독립적. 다른
state나props로부터 계산될 수 없습니다.
props는 불변(Immutable)이며, 오직 뷰 템플릿을 채우는 데 사용됩니다:
props React Element 설명 객체
-----> 컴포넌트 ---------------------> 뷰
데이터 바인딩?
2가지 단계
-
의존성 수집 (정적 의존성/동적 의존성)
-
변화 감지
최초 렌더링 시 data-view 매핑 관계를 수집하고, 이후 데이터 변화가 확인되면 해당 데이터에 대응하는 뷰를 업데이트합니다.
3가지 구현 방식
| 구현 방식 | 의존성 수집 | 변화 감지 | 사례 |
|---|---|---|---|
| getter & setter | getter | setter로 변화 감지 | Vue |
| 데이터 모델 제공 | 템플릿 해석 | 모든 데이터 조작이 프레임워크 API를 거쳐 변화를 알림 | Ember |
| Dirty Checking | 템플릿 해석 | 적절한 시점에 최신 값과 이전 값을 비교하여 변화 확인 | Angular |
| 가상 DOM diff | 거의 수집 안 함 | setState로 변화를 알림 | React |
의존성 수집의 입도(Granularity) 관점에서 보면:
-
Vue는
getter를 통한 동적 수집으로 입도가 가장 세밀하고 정확합니다. -
Ember와 Angular는 정적 템플릿 해석을 통해 의존성을 찾아냅니다.
-
React는 가장 거칠게 처리하며 의존성을 거의 수집하지 않고 전체 하위 트리를 다시 렌더링합니다.
state가 변하면 해당 하위 트리의 내부 상태를 다시 계산하고, 비교를 통해 변화를 찾아낸 뒤(diff), 적��한 시점에 이를 적용(patch)합니다.
세밀한 의존성 수집은 정밀한 DOM 업데이트의 기초가 됩니다(어떤 데이터가 어떤 요소의 어떤 속성에 영향을 주는지). 프레임워크가 영향을 받는 뷰 요소/속성을 명확히 안다면 추가적인 추측이나 판단 없이 가장 미세한 단위의 DOM 조작을 직접 수행할 수 있습니다.
가상 DOM diff 알고리즘
React는 의존성을 수집하지 않으므로 오직 두 가지 정보만 알고 있습니다:
-
이
state가 어느 컴포넌트에 속해 있는지 -
이
state변화는 오직 해당 하위 트리에만 영향을 미친다는 것
하위 트리 전체는 최종 뷰 업데이트에 필요한 DOM 조작으로 보기에 범위가 너무 크므로, *세분화(diff)*가 필요합니다.
tree diff
트리의 diff는 상대적으로 복잡한(NP) 문제이므로, 간단한 시나리오를 먼저 고려해 봅시다:
A A'
/ \ ? / | \
B C -> G B C
/ \ | | |
D E F D E
diff(treeA, treeA')의 결과는 다음과 같아야 합니다:
1. B 앞에 G 삽입 (insert G before B)
2. E를 F 자리로 이동 (move E to F)
3. F 제거 (remove F)
컴퓨터가 이를 수행하려면 추가와 삭제는 찾기 쉽지만, 이동을 판별하는 것은 복잡합니다. 먼저 트리의 유사도를 수치화(예: 가중치 기반 편집 거리)하고, 유사도가 어느 정도일 때 이동이 삭제+추가보다 유리한지(조작 단계가 더 적은지) 결정해야 합니다.
React diff
가상 DOM 하위 트리의 diff에서도 이런 문제에 직면합니다. DOM 조작 시나리오의 특징을 고려해 보면:
-
국소적인 작은 변화가 많고, 대규모 변화는 적습니다 (성능을 위해 표시/숨김 처리로 회피함).
-
계층을 넘나드는 이동은 적고, 같은 계층 내 노드 이동이 많습니다 (예: 테이블 정렬).
가정:
-
서로 다른 타입의 요소는 서로 다른 하위 트리에 대응한다고 가정합니다 ("하위 트리 구조가 유사한지 깊게 확인"하지 않으므로
이동판별이 쉬워집니다). -
이전과 이후 구조 모두 고유한
key를 가지며, 이를diff의 근거로 삼습니다. 동일한key는 동일한 요소임을 가정합니다 (비교 비용 절감).
이렇게 하면 tree diff 문제는 list diff(문자열 편집 문제)로 단순화됩니다:
-
새로운 것을 순회하며 추가/이동을 찾습니다.
-
이전 것을 순회하며 삭제를 찾습니다.
본질적으로 이는 매우 단순화된 문자열 편집 알고리즘입니다. 따라서 diff 비용을 고려하지 않더라도 실제 최종 DOM 조작 측면에서 성능이 (수동 DOM 조작에 비해) 최적은 아닐 수 있습니다.
또한 React는 만약을 위해 shouldComponentUpdate 훅을 제공하여 사용자가 diff 과정에 직접 개입하여 오판을 방지할 수 있도록 합니다.
상태 관리
상태 공유와 전달
-
형제 -> 형제: 상태를 끌어올려(lifting state up) 위에서 아래로 흐르는 단방향 데이터 흐름을 보장합니다.
-
자식 -> 부모: 부모가 미리 콜백(함수 props)을 전달합니다.
-
? -> 먼 친척: 원거리 통신은 해결하기 어렵습니다. 수동으로 계속 전달하거나 context를 통해 공유해야 합니다.
상태를 끌어올려 공유하면 고립된 상태를 줄이고 버그 발생 범위를 좁힐 수 있지만, 번거롭습니다. 컴포넌트 간 원거리 통신 문제에 대해서는 완벽한 해결책이 없습니다.
또 다른 문제는 복잡한 애플리케이션에서 상태 변화(setState)가 여러 컴포넌트에 흩어져 있어 로직이 분산되고 유지보수에 어려움이 생긴다는 점입니다.
Flux
상태 관리 문제를 해결하기 위해 Flux 패턴이 제안되었습니다. 목표는 데이터를 예측 가능하게 만드는 것입니다.
기본 사고방식
(state, action) => state
구체적인 방법
-
명시적인 데이터를 사용하고, 파생 데이터(Derive data) 사용을 지양합니다 (먼저 선언하고 사용하며, 임시 데이터를 만들지 않음).
-
데이터와 뷰 상태를 분리합니다 (데이터 계층을 추출함).
-
연쇄적인 업데이트로 인한 부수 효과를 피합니다 (모델과 뷰 사이의 상호 영향으로 데이터 흐름이 불투명해지는 것 방지).
구조
action 발생 action 전달 state 업데이트
view 상호작용 -----------> dispatcher -----------> stores --------------> views
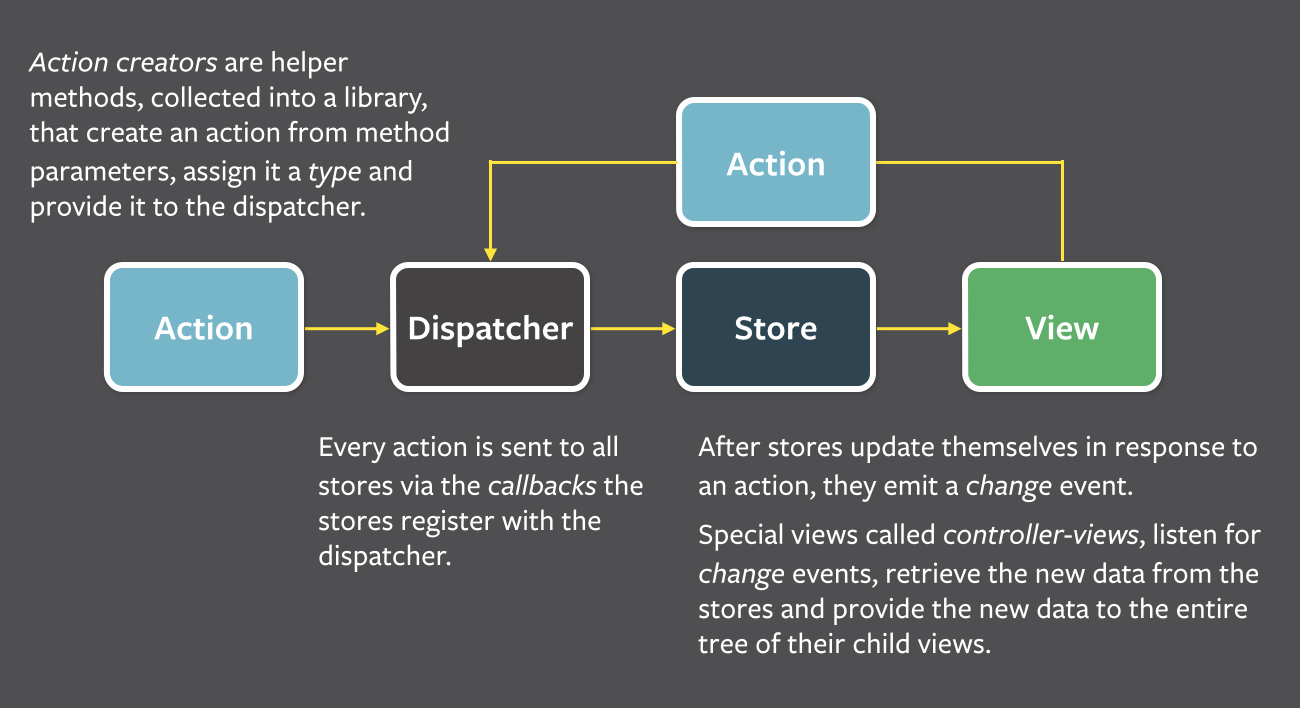
특징은 store가 비교적 무겁다는 점입니다. action에 따라 내부 state를 업데이트하고 state 변화를 view에 동기화하는 역할을 담당합니다.
container와 view
container는 사실 controller-view입니다:
-
view를 제어하는 React 컴포넌트입니다.
-
기본 역할은 store로부터 정보를 수집하여 자신의 state에 저장하는 것입니다.
-
props나 UI 로직을 포함하지 않습니다.
Redux의 선택
action Flux와 마찬가지로 타입과 데이터(payload)를 가진 이벤트입니다.
역시 수동으로 action을 dispatch합니다.
---
store Flux와 기능은 같지만 전역에 오직 1개만 존재하며, 내부적으로 불변 상태 트리입니다.
action을 전달하고 listener를 등록합니다. 각 action은 여러 reducer를 거쳐 새로운 state를 만듭니다.
---
reducer arr.reduce(callback, [initialValue])와 유사한 역할을 합니다.
reducer는 callback에 해당하며, 현재 state와 action을 입력받아 새로운 state를 출력합니다.
호출 새로운 state
action --> store ------> reducers -----------> view
하나의 불변 상태 트리로 전체 애플리케이션의 상태를 관리합니다. 직접 수정할 수 없으며 변화가 생기면 action과 reducer를 통해 새로운 객체를 생성합니다.
reducer 개념은 node 미들웨어나 gulp 플러그인과 유사합니다. 각 reducer는 상태 트리의 일부분을 담당하며, 여러 reducer를 직렬로 연결하여(이전 reducer의 출력을 현재 reducer의 입력으로 사용) 최종 state를 얻습니다.
Flux와의 비교
-
store의 개수를 1개로 제한합니다.
-
dispatcher를 없애고 action을 모든 최상위 reducer에 전달하여 해당 하위 트리로 흐르게 합니다.
-
action에 따라 내부 state를 업데이트하는 부분을 독립시켜 각 reducer로 분해했습니다.
dispatcher를 없앨 수 있는 이유는 순수 함수인 reducer를 자유롭게 조합할 수 있어 별도의 순서 관리가 필요 없기 때문입니다.
react-redux
Redux는 React와 아무런 관계가 없습니다. Redux는 상태 관리 계층으로서 backbone, angular, React 등 어떤 UI 솔루션과도 함께 사용할 수 있습니다.
react-redux는 새로운 state -> view 부분을 처리합니다. 즉, 새로운 state가 생겼을 때 어떻게 뷰를 동기화할 것인가를 담당합니다.
container
container는 뷰 로직을 포함하지 않고 store와 밀접하��� 연결된 특수한 컴포넌트입니다. 논리적으로는 store.subscribe()를 통해 상태 트리의 일부를 읽어와서 하위의 일반 컴포넌트(view)에 props로 전달하는 역할을 합니다.
connect()
마법처럼 보이는 API로, 주로 세 가지 일을 합니다:
-
container를 생성합니다.
-
dispatch와 state 데이터를 하위 컴포넌트에 props로 주입합니다.
-
불필요한 업데이트를 방지하는 성능 최적화가 내장되어 있습니다 (shouldComponentUpdate 내장).
Provider는 무엇인가요?
목적: store를 수동으로 계층마다 전달하는 것을 피하기 위함입니다.
구현: 최상위에서 context를 통해 store를 주입하여 하위의 모든 컴포넌트가 store를 공유할 수 있게 합니다.
생태계
-
디버깅 도구: DevTools
-
플랫폼: React Native
-
컴포넌트 라이브러리: antd, Material-UI
-
발전형: Rax
-
상태 관리 계층: Redux Saga, Dva
아직 댓글이 없습니다