一.Scalability 란 무엇인가?
Scalability is the property of a system to handle a growing amount of work by adding resources to the system.
(Scalability 에서 인용)
즉, 시스템에 리소스를 추가함으로써 증가하는 워크로드에 대응하는 것입니다
그렇다면, 어떻게 리소스를 추가할까요?
二.하드웨어 리소스 확장
리소스 추가 방법에는 두 가지가 있습니다. 수직 확장과 수평 확장입니다
수직 확장
수직 확장 (Vertical scaling) 은 단일 머신의 구성을 향상시키고, 단일 머신에 메모리, 프로세서, 하드디스크 등의 하드웨어 리소스를 추가하는 것입니다. 충분한 예산을 투입하면, 호화로운 구성의 서버를 구축할 수 있습니다
그러나, 이러한 단일 점 강화형 확장을 무한히 계속할 수는 없습니다. 곧바로 최고 구성에 도달하거나 (또는 예산을 모두 소진하거나) 하므로, 완전한 솔루션이라고 할 수는 없습니다
수평 확장
또 다른 리소스 추가 방법은 수평 확장 (Horizontal scaling) 으로, 즉 머신을 추가하고, 수를 1 대에서 여러 대로 확장하며, 여러 서버로 토폴로지 구조를 형성합니다. 충분한 예산을 투입하면, 데이터센터를 가질 수 있으며, 더 나아가 전 세계에 분산시킬 수도 있습니다
이론상, 수평 확장에는 상한이 없습니다. 무한히 많은 서버를 사용하여 무한히 많은 사용자 요청을 지원할 수 있습니다. 게다가, 수평 확장은 중복성 (Replication) 을 도입하는 것이 되어, 단일 머신보다 더 신뢰할 수 있습니다
그러나, 머신이 1 대에서 여러 대로 된 후, 직면하는 최대의 문제는리소스 배분입니다. 이러한 머신들을 어떻게 충분히 활용할까? 즉, 어떻게 부하를 균형있게 할까?
三.로드 밸런싱
로드 밸런서 (Load Balancer) 는 사용자 요청을 여러 서버에 배포하는 역할을 합니다. 구체적으로, 퍼블릭 네트워크 Load Balancer 가 라우팅 규칙에 따라 인바운드 HTTP 요청을 배포하고, 데이터 패킷을 실제로 어느 인트라넷 서버에 전송할지 결정합니다
일반적인 배포 전략에는 다음과 같습니다:
-
부하 상황에 따른 배포
-
순차 균등 배분
-
리소스 의존 상황에 따른 배포
물론, 가장 이상적인 배분 전략은 서버의 현재 부하 상황에 따른 배포입니다. 예를 들어, 새로운 요청을 그다지 바쁘지 않은 서버에 맡기는 것이지만, 문제는 부하 상황이 그렇게 쉽게 정확하게 파악되지 않는다는 것입니다
가장 간단한 배분 전략은 라운드 로빈 (Round robin) 입니다. 예를 들어, 1 번째 URL 요청 시 Server1 의 IP 주소를 반환하고, 2 번째에 Server2 의 IP 주소를 반환합니다……그러나, 라운드 로빈 작업은 평등하게 대우하는 것을 의미하며, 각 요청의 워크로드가 같고, 각 Server 의 처리 능력도 같다고 가정하지만, 실제 시나리오에서는 대부분의 경우 이러한 조건을 만족하지 않습니다
P.S.DNS 를 로드 밸런서로 사용하는 것은 권장되지 않습니다 (일련의 A 레코드를 추가). 운영체제 및 애플리케이션 계층의 DNS 캐시가 이 순차 균등 배분 메커니즘을 파괴하기 때문입니다
한편, 다른 유형의 서비스는 리소스에 대한 의존 상황 (대역폭, 스토리지, 계산 능력 등) 이 다를 수 있으므로, 전용 서버를 채택하고, 리소스 의존 상황에 따라 배포할 수도 있습니다. 예를 들어, gif, jpg, image, video 등에 다른 전용 서버를 사용하고, 서브도메인 등의 방법으로 구분합니다
세션 유지
Load Balancer 를 1 층 추가함으로써 리소스 배분의 문제가 해결되었지만, 또 새로운 문제를 가져왔습니다: 전후의 2 개 요청이 로드 밸런서에 의해 다른 서버로 전달될 가능성이 있습니다. 이 2 개 요청에 연관이 있는 경우 (예를 들어 로그인과 주문), 전置의 상태가 손실됩니다 (사용자가 로그인한 직후 주문을 클릭하면, 다시 로그인을 요구할 수 있습니다)
하나의 해결 방법은 스티키 세션 (Sticky sessions) 으로, 연관된 요청을 같은 서버로 전달합니다:
Send all requests in a user session consistently to the same backend server.
(Load balancing (computing) 에서 인용)
예를 들어 Cookie 에 서버의 식별 정보를 실어, 이후 일련의 요청을 그 서버로 전달합니다
P.S.그러나 Cookie 는 무효화될 수 있으므로, 일반적으로는 여러 방법을 종합적으로 사용하여 세션을 유지합니다
또 다른 방안은 Session 을 "아웃소싱"하여, 공공 장소에 보관하고, 다른 서버가 공유 액세스할 수 있도록 하는 것입니다:
Every server contains exactly the same codebase and does not store any user-related data, like sessions or profile pictures, on local disc or memory. Sessions need to be stored in a centralized data store which is accessible to all your application servers.
지금까지, 우리는 몇 대의 머신을 추가하고, 로드 밸런서를 통해 여러 머신이 공동으로 분담하여 작동하게 했습니다. 모든 것이 완벽해 보입니다……그런데, 이 로드 밸런서가 다운되면 어떻게 될까요?
四.중복성 도입
로드 밸런서를 도입한 후, 모든 요청은 먼저 로드 밸런서를 거쳐야 하며, 로드 밸런서는 네트워크 토폴로지 구조에서취약한 단일 점이 됩니다.一旦发生故障, 身後의 모든 서버에 액세스할 수 없게 됩니다
중복 로드 밸런서
단일 점 장애 (Single Point of Failure) 를 회피하기 위해, 로드 밸런서에도 중복성을 도입할 필요가 있습니다 (예를 들어 한 쌍의 로드 밸런서를 사용). 일반적으로 두 가지 페일오버 (Fail-over) 모드가 있습니다:
-
액티브 - 패시브 (Active-passive): 액티브가 작업하고, 패시브가 대기. 액티브가 다운된 후 패시브가 인수
-
액티브 - 액티브 (Active-active): 동시에 작업. 하나가 다운되어도 영향 없음
어떤 작업 모드를 채택해도, 중복성을 도입함으로써 다운타임을 단축하고, 시스템의 신뢰성과 가용성을 향상시킬 수 있습니다
五.데이터베이스 확장
이론상, 신뢰할 수 있는 로드 밸런싱 메커니즘이 있으면, 1 대의 서버를 쉽게 n 대로 확장할 수 있습니다. 그러나, 이 n 대의 머신이 여전히 동일 데이터베이스를 사용하는 경우, 곧 데이터베이스가 시스템의 성능 병목과 신뢰성 병목이 됩니다
동일한 방법으로, 데이터베이스의 처리 능력을 확장하고, 몇 개의 庫를 추가할 수 있습니다. 즉 중복성을 도입합니다. 일반적으로 두 가지 모드가 있습니다:
-
마스터 - 슬레이브 복제: 마스터 庫가 직접 읽기 쓰기를 하고, 슬레이브 庫는 마스터 庫가 쿼리를 수신할 때, 같은 쿼리를 실행합니다. 마스터 庫가 다운된 경우, 슬레이브 庫 중에서 하나를 마스터 庫로 승격시킵니다
-
마스터 - 마스터 복제: 모두 쓰기 가능하며, 쓰기 작업도 다른 한 庫에 복제됩니다
데이터베이스에 중복성을 도입한 후, 여러 슬레이브 庫에 대해 로드 밸런싱을 수행할 수도 있습니다 (특히 읽기 집중의 시나리오에 적합합니다):

및 콘텐츠 특성에 따른 파티션 스토리지 (Partitioning):
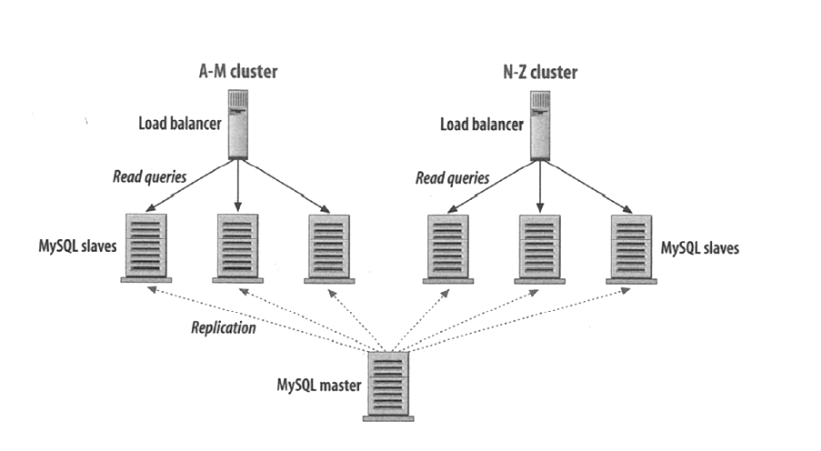
姓名이 A-M 시작으로 시작하는 데이터를 왼쪽의 몇 개 데이터베이스에 저장하고, N-Z 시작으로 시작하는 것을 오른쪽에 저장합니다
동시에, 분庫分表 (Sharding), 비정규화 (Denormalization), SQL 튜닝 (SQL tuning) 등의 방법으로 쿼리를 최적화할 수도 있습니다
여기까지, 데이터베이스 계층에서 가능한 확장 최적화는 한계에 도달한 것 같습니다. 그렇다면, 데이터베이스의 압력을 경감하는 다른 방법이 있을까요?
六.캐시
또 다른 사고방식은 데이터베이스 조작을 가능한 한 줄이는 것입니다. 예를 들어 Web 서비스와 데이터 사이에 메모리 캐시를 한 층 추가하고, 쿼리 시 우선적으로 캐시를 통하고, 캐시에 없는 경우에만 데이터베이스에서 가져옵니다
일반적으로 두 가지 캐시 모드가 있습니다:
-
쿼리 결과 캐시
-
객체 캐시
모든 쿼리 결과를 캐시하는 최대의 문제는, 데이터가 변화한 후, 캐시가 만료되었는지 여부를 판정하기 어렵다는 것입니다:
It is hard to delete a cached result when you cache a complex query (who has not?). When one piece of data changes (for example a table cell) you need to delete all cached queries who may include that table cell.
한편, 객체 캐시는 원시 데이터에 따라 조립된 데이터 모델 (예를 들어 Java 클래스 인스턴스) 을 캐시하는 것을 가리킵니다. 장점은 데이터 변화를 파악한 후, 그것과 논리적으로 연관된 데이터 객체를 폐기할 수 있어, 캐시 만료의 난제를 해결할 수 있다는 것입니다
지금까지, 우리는 바텀업으로 하드웨어 리소스, 데이터베이스, 캐시를 포함한 확장성 문제에 대해 논의했습니다. 그렇다면, Web 서비스 자체는 어떻게 확장해야 할까요?
七.비동기 처리
Web 서비스에 있어, 확장성을 향상시키는 주요 경로는시간이 걸리는 동기 작업을 비동기 처리로 변경하는 것입니다. 이를 통해, 이러한 작업을 여러 Worker 에 "아웃소싱"하거나, 예측 가능한 부분을 사전에 완료할 수 있습니다
아직 댓글이 없습니다