앞에 쓰는 말
UC Berkeley 는 2019 년 2 월 10 일에 Serverless 에 관한 논문을 발표했으며, 업계에서 이 몇 달 동안 Serverless 에 대한 뜨거운 논의를 일으켰습니다
버클리 연구자들은 Serverless 가 거의 모든 시스템 관리 작업을 처리할 수 있어, 개발자가 더 쉽게 클라우드를 사용할 수 있게 한다고 생각합니다. 클라우드 프로그래밍을 크게 단순화함과 동시에, 어셈블리 언어에서 고급 프로그래밍 언어로의 진화와 유사한 변천을 나타냅니다:
Serverless cloud computing handles virtually all the system administration operations needed to make it easier for programmers to use the cloud. It provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages.
더 나아가Serverless 가 클라우드 컴퓨팅의 미래를 주도할 것이라고 생각합니다:
Just as the 2009 paper identified challenges for the cloud and predicted they would be addressed and that cloud use would accelerate, we predict these issues are solvable and that serverless computing will grow to dominate the future of cloud computing.
一.10 년 전의 6 개 예언
10 년 전 (2009 년 2 월 10 일), UC Berkeley 는 Cloud Computing 에 관한 논문에서 클라우드 컴퓨팅의 6 대 잠재 우위성을 지적했습니다:
-
필요에 따라 무한한 계산 리소스를 제공 가능
-
클라우드 사용자는 리소스를 예측할 필요 없음
-
즉시 사용 즉시 지불의 단기 계산 리소스를 제공
-
초대규모 데이터 센터가 형성하는 규모의 경제가 비용을 대폭 절감
-
리소스 가상화를 통해 작업을 단순화하고 이용률 향상
-
멀티플렉싱을 통해 하드웨어 이용률 향상
P.S.��러한 예언에 대한 상세 정보는, [버클리 연구자들眼中的 Cloud Computing](/articles/伯克利研究员们眼中的 cloud-computing/) 참조
현재에 이르기까지, 이러한 우위성은 기본적으로 모두 실현되었습니다. 그러나작업의 복잡성은 여전히 클라우드 사용자를 괴롭히고 있으며, 멀티플렉싱의 우위성도 완전히 발휘되지 못하고 있습니다:
-
클라우드 컴퓨팅은 물리 인프라 관리 부담을 경감했지만, 마찬가지로 관리가 필요한 대량의 가상 리소스를 만들어냈습니다
-
멀티플렉싱은 배치 처리의 장면 (예를 들어 MapReduce 나 고성능 계산) 에서 위력을 발휘할 수 있지만, 스테이트풀한 서비스 (예를 들어 데이터 관리 시스템 등의 기업 애플리케이션) 에서는 효과를 발휘하기 어렵습니다
P.S.멀티플렉싱 은 통신 분야에서 널리 사용되는 리소스 공유 기술로, 시분할 다중 (Time-division multiplexing), 주파수 분할 다중 (Frequency-division multiplexing) 등을 포함합니다
그 이유는 시장이 더 낮은 수준의 리소스 추상화 방식을 선택하여, 클라우드 사용자는 물리 하드웨어를 사용하는 것처럼 리소스 스택 전체를 제어하며, 여전히 다음을 고려해야 합니다:
-
가용성 중복 (단일 장애점 회피)
-
원격지 재해 대책
-
로드 밸런싱
-
탄력적 스케일링
-
모니터링
-
로그 (디버그 또는 성능 진단용)
-
시스템 업그레이드 (보안 패치 등)
-
이식성 (새 인스턴스로 이전)
二.Serverless Computing 등장
개념 정의
사용 용이성方面的인 니즈를 인식한 후, Amazon 은 2015 년에 AWS Lambda 서비스, 즉*클라우드 함수 (cloud functions)를 출시했으며, 이어서버리스 컴퓨팅 (serverless computing)*의 이념에 대한 광범위한 주목을 일으켰습니다:
Serverless suggests that the cloud user simply writes the code and leaves all the server provisioning and administration tasks to the cloud provider.
서버 관련 설정 관리 작업을 모두 클라우드 프로바이더에게 맡겨, 사용자의 클라우드 리소스 관리 부담을 경감합니다
따라서, Serverless Computing 은 computing 하기 위해 server 가 필요 없다는 것이 아니라, 사용자에게 있어 server 를 관리하기 위해 큰 정력을 들일 필요가 없다는 것 입니다. 마찬가지로, Serverless 서비스는 (자동으로) 탄력적으로 스케일링할 수 있으며, 명시적으로 리소스를 프로비저닝할 필요가 없고, 사용 상황에 따라 과금됩니다
另一方面,Serverless 는 더욱 일종의 패러다임 시프트를 가져왔습니다——프로바이더에게 완전히 작업을 위임하는 것을 허용하며, 이로 인해 세밀한 멀티테넌트 멀티플렉싱을 가능하게 했습니다:
Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplex- ing.
Serverless 의 핵심은 FaaS(Function as a Service) 이지만, 클라우드 플랫폼은 일반적으로 BaaS(Backend as a Service) 등의 특정 애플리케이션 요구를 충족시키기 위해 Serverless 프레임워크도 제공합니다. 따라서, 간단히 이해할 수 있습니다:
Serverless computing = FaaS + BaaS
기본 아키텍처
Serverless 레이어는 애플리케이션 레이어와 기초 클라우드 플랫폼 레이어 사이에 위치하며, 클라우드 프로그래밍을 단순화하는 데 사용됩니다:
[caption id="attachment_2050" align="alignnone" width="625"]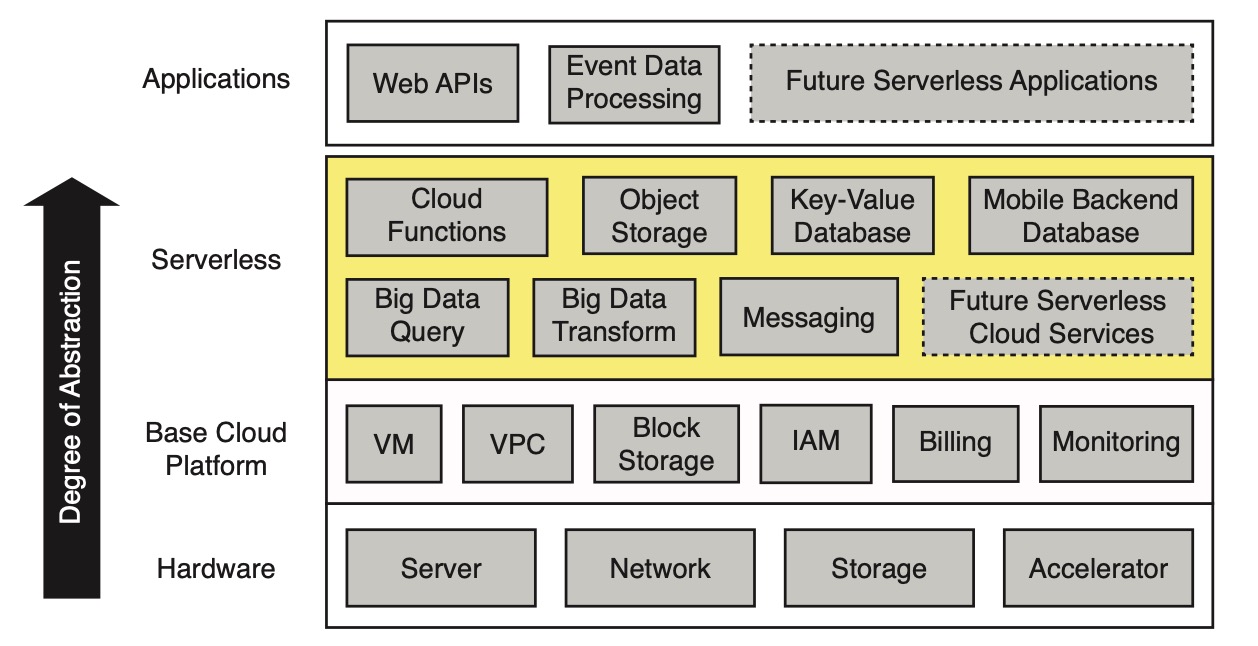 Architecture of the serverless cloud[/caption]
Architecture of the serverless cloud[/caption]
그 중에서, 클라우드 함수 (Cloud functions, 예를 들어 FaaS) 는 일반 계산을 제공하며, 특정 BaaS 제품 생태계 (예를 들어 오브젝트 스토리지, 데이터베이스, 메시지 메커니즘 등) 로 보완됩니다. 기초 플랫폼에는 가상 머신 (VM), 전용 네트워크 (VPC), 가상화 데이터 블록 스토리지, ID 및 액세스 관리 (IAM), 및 과금과 모니터링이 포함됩니다
Serverless 와 Serverful
사용자는 Serverless 플랫폼에서 고급 언어로 몇 가지 클라우드 함수를 쓰기만 하면, 해당 함수의 실행을 트리거하는 이벤트를 선택하기만 하면 됩니다. 그後の 일은 Serverless 시스템이 처리하며, 인스턴스 선택, 스케일링, 배포, 폴트톨러런스, 모니터링, 로그, 보안 패치 등 모두 신경 쓸 필요가 없이, 클라우드 리소스의 사용 용이성을 향상시킴으로써 애플리케이션 개발을 단순화합니다
클라우드 배경 하에서, 클라우드 개발자에게 있어, 전통적인 방식 (Serverful Computing) 은 저급의 어셈블리 언어를 사용하는 것과 같으며, c = a + b 와 같은 간단한 계산조차도 일련의 작업을 거쳐야 합니다:
-
1 개 또는 2 개의 레지스터를 선택 (리소스를 프로비저닝하거나 사용 가능한 리소스를 찾음)
-
값을 레지스터에 로드 (코드와 데이터를 로드)
-
산술 연산 실행 (계산 실행)
-
계산 결과 저장 (결과를 반환 또는 저장하고, 마지막으로 리소스 해제)
一方 Serverless 방식은 Python등의 고급 언어로 프로그래밍하는 것과 같아, 이러한 번거로운 작업을 면제받습니다
따라서, Serverless가 가장 잠재력 있는 곳은 클라우드 개발자에게 고급 언어로의 전진과 유사한 이러한 혜택을 가져다줄 수 있다는 것 입니다:
The aim and opportunity in serverless computing is to give cloud programmers benefits similar to those in the transition to high-level programming languages.
고급 프로그래밍 환경의 몇 가지 특성은 Serverless에 자연스러운 유사점이 있습니다. 예를 들어, 자동적인 메모리 관리는 개발자를 메모리 리소스 관리 작업에서 해방시키지만, Serverless는 개발자를 서버 리소스 관리 작업에서 해방시켜야 합니다
정확히 말하면, Serverless와 Serverful의 가장 중요한 차이점은:
-
계산과 스토리지를 분리: 스토리지와 계산을 별도로 스케일링하고, 독립적으로 프로비저닝하며, 독립적으로 가격 책정. 일반적으로 스토리지는 별도의 클라우드 서비스에 의해 제공되며, 계산은 스테이트리스
-
리소스 할당을 관리하지 않고 코드 실행 가능: 사용자는 코드를 제공하고, 클라우드는 자동으로 리소스를 프로비저닝하여 실행
-
사용에 따라 과금하고, 할당된 리소스에 따라 과금하지 않음: 코드 실행의 관련 차원 (예를 들어 실행 시간) 에 따라 과금하고, 클라우드 플랫폼의 관련 차원 (예를 들어 할당된 VM의 크기와 수량) 에 따라 과금하지 않음
三.핵심 특징
듣기에 앞서의 몇 가지 패턴과 그다지 큰 차이가 없는 것 같습니다:
-
기존의 몇 가지 PaaS 제품, 예를 들어 Firebase, Heroku, Parse 등은 Serverless인 것 같다
-
80년대의 Web호스팅 환경도 Serverless가 주장하는 혜택을 제공할 수 있지 않았을까?
-
10년 전의 Google AppEngine처럼 들리지만, 이는 Serverless 이념이 나타나기 전에 이미 시장에 거절되었呀
그렇다면, 앞서의 이러한 패턴들과 비교하여, Serverless의 핵심 특징은 무엇일까요?
스케일링
스케일링方面에서는, AWS Lambda는 부하 상황을 정확하게 추적할 수 있으며, 필요에 따라 신속하게 확장하고, 한가할 때는 제로 리소스, 제로 비용까지 축소할 수 있습니다. 더욱 세밀한 입자로 과금 (100ms) 할 수 있으며, 전통적인 탄력적 스케일링 서비스는 일반적으로 시간 단위로 과금합니다
가장 중요한 것은, Serverless의 출발점은 코드가 실제로 실행된 시간에 따라 과금하는 것으로, 프로그램 실행을 위해 예약된 리소스가 아니다 는 것입니다:
In a critical departure, it charged the customer for the time their code was actually executing, not for the resources reserved to execute their program.
이 차이는 클라우드 프로바이더가 탄력적 스케일링이라는 점에서 클라우드 사용자와 위험을 공유하고 이익을 공유할 수 있음을 보장합니다 (skin in the game), 이어 효율적인 리소스 할당을 촉진합니다
강력한 격리성
Serverless는 강력한 성능과 보안 격리성에 의존하여 멀티테넌트가 하드웨어를 공유하는 것을 실현합니다
클라우드 함수에 대해, VM 격리는 현재의 표준 방안이지만, VM을 프로비저닝하는 데 몇 초가 걸릴 수 있으므로, 클라우드 프로바이더는 함수 실행 환경 생성을 가속화하기 위해 몇 가지 세밀한 기술을 사용합니다. 예를 들어 AWS Lambda는 즉시 테넌트에 할당 가능한 VM을 관리하는 핫 VM 풀 (a "warm pool" of VM) 과, 이미 함수를 실행 중이거나 실행 준비가 된 인스턴스를 관리하는 액티브 인스턴스 풀 (an "active pool" of instances) 을 유지하고 있습니다
리소스 라이프사이클 관리와 멀티테넌트装箱 전략 (multi-tenant bin packing) 은 높은 이용률을 실현하는 열쇠 로, Serverless에게 극히 중요합니다. 대부분은 컨테이너, 단일 코어, 라이브러리 OS(library OS) 또는 언어 VM 등의 기술을 이용하여 멀티테넌트 격리의 오버헤드를 줄입니다. 예를 들어 Google App Engine이 사용하는 gVisor, AWS Lambda중의 Firecracker VM, 및 CloudFlare Workers 플랫폼이 Web브라우저 샌드박스 기술을 채택하여 JavaScript 클라우드 함수 간의 멀티테넌트 격리를 실현합니다
플랫폼 유연성
PaaS 서비스는 일반적으로 특정 유스케이스와 밀접하게 관련되어 있지만, Serverless는 사용자가 자신의 라이브러리를 사용하는 것을 허용하며, 지원할 수 있는 애플리케이션은 PaaS보다 더 광범위합니다
게다가, Serverless는 현대화된 대규모 데이터 센터에서 실행되며, 지원할 수 있는 실행 규모는 오래된 공유 web호스팅 환경보다 훨씬 큽니다
서비스 생태계 지원
클라우드 함수 (예를 들어 FaaS) 는 Serverless 모드를 성공적으로 보급했으며, 그 일부는 공유 클라우드 이후 존재하는 몇 가지 BaaS 서비스 (예를 들어 AWS S3) 에 귀속됩니다. 이러한 BaaS 서비스는 모두 특정 분야 지향, 고도로 최적화된 Serverless 구현으로 간주할 수 있으며, 클라우드 함수는 더 범용적인 Serverless 표현 형식입니다:
| Service | Programming Interface | Cost Model |
|---|---|---|
| Cloud Functions | Arbitrary code | Function execution time |
| BigQuery/Athena | SQL-like query | The amount of data scanned by the query |
| DynamoDB | puts() and gets() | Per put() or get() request + storage |
| SQS | enqueue/dequeue events | per-API call |
四.핵심 우위성
클라우드 프로바이더에게 있어, Serverless는 비즈니스 성장을 촉진하고, 클라우드 프로그래밍을 단순화하며, 신규 사용자를 유치하고, 기존 사용자가 클라우드 리소스를 충분히 활용하는 것을 돕습니다. 게다가, 실행 시간이 짧고, 메모리 점유가 낮으며, 스테이트리스한 특성은 통계적复用에 유리 합니다. 이러한 작업을 실행할 때, 클라우드 프로바이더는 사용되지 않는 리소스를 더 쉽게 찾을 수 있습니다. 게다가那些인기가 많지 않은 머신 (예를 들어 오래된 머신) 을 더 잘 이용할 수도 있습니다. 인스턴스 타입은 클라우드 프로바이더에 의해 결정되므로, 이 2가지 점은 기존 리소스的基础上에서 즉시 수익을 증가시킬 수 있습니다
클라우드 사용자에게 있어, 프로그래밍 생산성을 향상시키는之外, 대부분의 장면에서는 비용도 절감할 수 있습니다. 저변 서버의 이용률이 향상되었기 때문입니다. 어떠한 클라우드 인프라스트럭처도 없는 상황에서도 직접 함수를 배포할 수 있으며, 배포 시간을 절약할 뿐만 아니라, 클라우드 사용자에게 애플리케이션 자신의 문제에 집중하게 하고, 자금도 절약할 수 있습니다. 함수는 이벤트가 발생할 때에만 실행되며, 세밀한 입자의 과금 방식 (현재는 100ms) 은 실제로 사용한 분에 따라 과금하는 것을 의미하며, 예약된 리소스에 따라 과금하는 것이 아닙니다
연구 각도에서 보면, Serverless는 일종의 새로운 범용 계산 추상으로, 클라우드 컴퓨팅의 미래가 될 것으로 기대됩니다. Serverless는 클라우드 배포 레벨을 x86 머신 코드에서 고급 프로그래밍 언어로 끌어올려, 아키텍처 혁신을 실현합니다. 만약 ARM 또는 RISC-V가 x86보다 비용 성능이 더 높다면, Serverless도 쉽게 명령어 세트를 변경할 수 있습니다. 게다가 클라우드 프로바이더는 (프로그래밍) 언어 지향의 최적화 및 특정 분야의 특수 아키텍처를 연구함으로써 Python등의 언어로 작성된 프로그램을 가속할 수 있습니다
P.S.99% 의 클라우드 컴퓨터는 x86 아키텍처 (x86 마이크로프로세서 + x86 명령어 세트) 를 사용합니다
五.기존 Serverless 플랫폼의 한계성
현재, 클라우드 함수는 API 서비스, 이벤트 스트림 처리 및 제한된 ETL(Extract-Transform-Load, 데이터 처리) 을 포함한多种의 작업에 성공적으로 적용되고 있습니다. 그렇다면, 왜 더 많은 범용 서비스를 담당할 수 없는 것일까요?
그 이유는:
-
세밀한 작업의 스토리지 지원 부족: 현재의 클라우드 스토리지 서비스는 클라우드 함수의 요구를 충족시킬 수 없음
-
세밀한 조정 부족: 멀티태스크 조정 메커니즘이 없음
-
표준 통신 모드 하에서 성능이 매우 나쁨: 멀티태스크 간에 데이터를 공유, 집계할 수 없음
-
성능이 예측 불가능: 전통적인 VM기반의 인스턴스 시작 지연보다 낮지만,某些애플리케이션에게 있어 새로운 인스턴스를 시작하는 지연은 여전히 너무 높음
세밀한 작업의 스토리지 부족
Serverless 플랫폼의스테이트리스성은 공유 세밀한 상태를 필요로 하는 애플리케이션을 지원하는 것을 어렵게 실현하며, 현재 주로 클라우드 스토리지 서비스에 제한되어 있습니다
오브젝트 스토리지 서비스 (예를 들어 AWS S3, Azure Blob Storage, Google Cloud Storage) 는 신속하게 확장할 수 있고, 저렴한 장기 오브젝트 스토리지를 제공하지만, 매우 높은 액세스 비용과 지연이 존재합니다.近期 테스트表明 읽기/쓰기 작은 오브젝트는 적어도 10ms가 필요하며, 10 만 IOPS(매초 읽기 쓰기 횟수, Input/Output Operations Per Second) 를 유지하는 비용은 30달러/분으로, AWS ElastiCache 인스턴스보다 3에서 4자리 높으며, ElastiCache 인스턴스는 서브밀리초급 읽기 쓰기 지연しか 없으며, 그 IOPS는甚至 100K를 초과할 수 있습니다
KV 데이터베이스 (예를 들어 AWS DynamoDB, Google Cloud Datastore, Azure Cosmos DB) 는 모두 높은 IOPS 지원을 제공하지만, 모두 매우 비싸며, 신속하게 확장할 수 없습니다. 클라우드 프로바이더는 인기 있는 오픈소스 프로젝트 (예를 들어 Memcached 또는 Redis) 에 기반한 메모리 스토리지 인스턴스도 제공하지만, 폴트톨러런스 지원이 부족하며, Serverless 플랫폼처럼 자동으로 스케일링할 수 없습니다
Serverless 인프라스트럭처上に 구축된 애플리케이션은 프로비저닝 투명한 스토리지 서비스를 필요로 하며, 즉 계산과 함께 자동으로 스케일링하는 스토리지 서비스입니다. 다른 애플리케이션은 영속성, 가용성, 지연, 성능 등에 대해 다른 요구를 가질 수 있으므로, 임시와 영속화 2가지 종류의 Serverless 스토리지 옵션이 필요할 수 있습니다
세밀한 조정 부족
스테이트풀한 애플리케이션을 지원하기 위해, Serverless 프레임워크는 멀티태스크를 조정하는 방식을 제공해야 합니다. 예를 들어, A태스크가 B태스크의 출력을 사용하는 경우, A는 입력 준비가 된 때를 알 수 있는 방법이 필요합니다. A와 B가 다른 노드上に 있는 경우에도. 많은 데이터 일관성을 보장하는 프로토콜도 유사한 조정 메커니즘을 필요로 합니다
기존의 클라우드 스토리지 서비스는 모두 알림 능력이 없으며, 클라우드 프로바이더는 독립적인 알림 서비스 (예를 들어 SNS, SQS) 를 제공하지만, 매우 높은 지연 (때때로 수백 ms) 이 존재하며, 세밀한 조정의 사용 비용도 매우 높습니다. 몇 가지 관련 개선 연구 (예를 들어 Pocket) 가 있지만, 아직 클라우드 프로바이더에 채택되지 않았습니다
따라서, 애플리케이션은 알림 능력을 가진 VM기반의 시스템 (예를 들어 ElastiCache, SAND) 을 관리하거나, 또는 자신의 알림 메커니즘을 구현해야 합니다. 예를 들어 클라우드 함수 간이 장기 실행되고 있는 VM기반의 랑데부 서버 (rendezvous server) 를 통해 통신하도록. 이 제한은 몇 가지 새로운 Serverless 변체의 탐색을 일으켰습니다. 예를 들어 이름 붙인 함수 인스턴스는 직접 어드레싱을 통해 그 내부 상태에 액세스하는 것을 허용합니다 (예를 들어 Actors as a Service)
표준 통신 모드 하에서 성능이 매우 나쁨
브로드캐스트 (broadcast), 집계 (aggregation), shuffle 메커니즘 등의 분산 시스템 중의일반적인 통신 모드는 클라우드 함수 환경에서 복잡도가 급증합니다:
[caption id="attachment_2051" align="alignnone" width="1004"]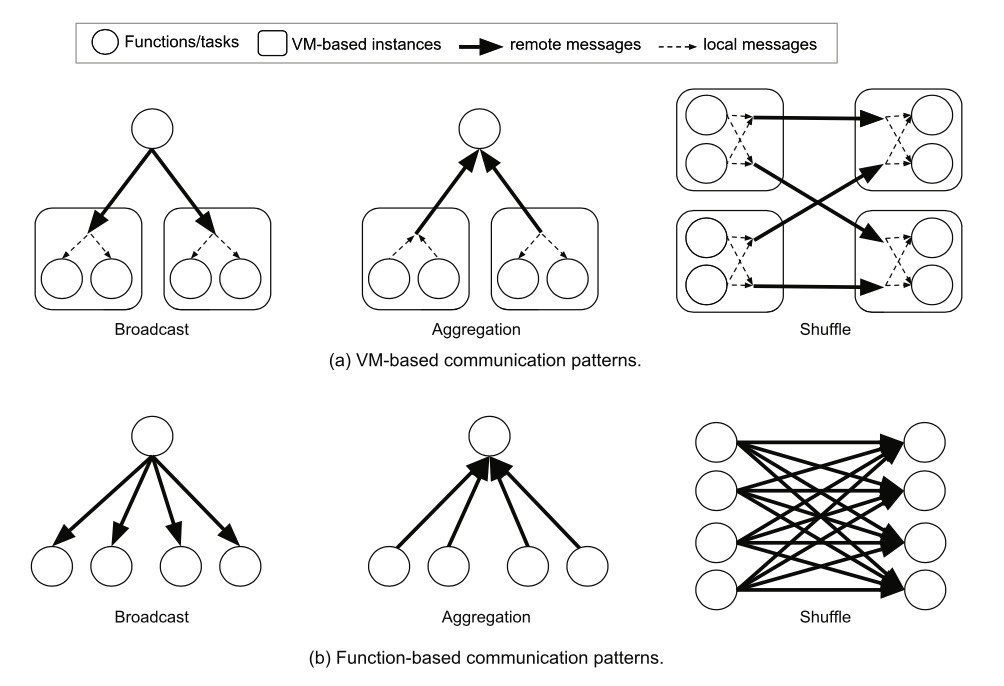 communication patterns for distributed applications[/caption]
communication patterns for distributed applications[/caption]
그 이유는 VM 인스턴스는 데이터를 전송하기 전과 데이터를 수신한 후에태스크 간에 데이터를 공유, 집계 또는 병합할 기회가 있는반면, Serverless 하에서는 없기 때문입니다
구체적으로, VM기반의 방안에서는, 동일 인스턴스上で 실행되고 있는 모든 태스크는 브로드캐스트를 통해 전송된 데이터를 공유할 수 있거나, 또는其它의 인스턴스에 부분 결과를 전송하기 전에 로컬 집계를 수행할 수 있습니다. 따라서, 브로드캐스트와 집계의 통신 복잡도는 O(N) 이며, N은 시스템 중의 VM 인스턴스의 수량입니다.一方 클라우드 함수 환경에서는, 통신 복잡도는 O(N × K) 이며, K는 각 VM上の 함수 수량입니다
shuffle 메커니즘 하에서는 이 차이가 더욱 크며, VM기반의 방안에서는 모든 로컬 태스크는 데이터를 함께 병합할 수 있으므로, 2 개의 VM 간에는 1 개의 메시지만을 전송하면 됩니다. 송신측과 수신측 수량이 같다고 가정하면, N^2조의 메시지를 전송해야 하지만, 클라우드 함수 방안 하에서는 (N × K)^2조의 메시지를 전송해야 합니다. 클라우드 함수가 가진 CPU 코어 수량은 VM보다 훨씬 적으므로, K는 일반적으로 10에서 100이며, 게다가 애플리케이션은 클라우드 함수의 위치를 제어할 수 없으므로, 실제로는 동등의 VM 방안보다 2에서 4자리 많은 데이터를 전송할 수 있습니다
P.S.이러한 통신 모드는 많게 기계 학습과 대데이터 분석 애플리케이션 중에서 사용됩니다
성능이 예측 불가능
콜드 스타트 지연에 영향을 미치는 요인은 3가지가 있습니다:
-
클라우드 함수를 시작하는 데 필요한 시간
-
해당 함수에 필요한 소프트웨어 환경을 초기화하는 시간, 예를 들어 Python라이브러리를 로드
-
사용자 코드 중의 특정 애플리케이션 초기화의 시간
後者 2개의 오버헤드와 비교하여, 전자는 그다지 문제가 아닙니다. 예를 들어 클라우드 함수를 시작하는 데는 1 초しか 걸리지 않지만, 모든 애플리케이션 라이브러리를 로드하는 데는 수십 초가 걸릴 수 있습니다
또 하나의 저해 요인은 하드웨어 리소스의 변동성입니다. 클라우드 프로바이더는 저변 서버를 유연하게 선택할 수 있는 (甚至 다른 시대의 CPU에遭遇할 수 있는) 때문입니다. 이 문제에 대해, 클라우드 프로바이더는 리소스를 최대한 이용하는 것과 성능 예측 가능성 사이에서 균형을 잡아야 합니다
六.이상적인 Serverless Computing
더 많은 애플리케이션이 Serverless의 혜택을 받기 위해서는, 주로 추상, 시스템, 네트워크, 보안, 아키텍처 등의方面的인 도전에 직면하고 있습니다
추상
리소스 니즈
개발자는 클라우드 함수의 메모리 크기와 실행 시간만을 제한할 수 있으며, CPU, GPU 또는其它의 타입의 액셀러레이터 등의其它의 리소스 니즈를 제어할 수 없습니다
하나의 방식은 개발자에게 이러한 리소스 니즈를 명시적으로 지정하게 하는 것이지만, 클라우드 프로바이더가 통계적复用를 통해 높은 이용률을 실현하는 것을 더 어렵게 합니다. 클라우드 함수 스케줄링에 더 많은 제약을 부과하기 때문입니다. 게다가 Serverless 정신에 반합니다. 클라우드 애플리케이션 개발자의 리소스 관리 부담을 증가시키기 때문입니다
또 하나의 더 나은 선택은추상 레벨을 향상시키는것으로, 클라우드 프로바이더가 리소스 니즈를 추론하고 개발자가 지정하지 않도록 합니다. 예를 들어 클라우드 프로바이더는 정적 코드 분석,上一次 실행 상황의 분석 또는 소스 코드의 동적 컴파일을 통해 실현할 수 있습니다. 적절한 메모리를 자동으로 프로비저닝하는 것은 매력적으로 들리지만, 도전에 차 있습니다. 특히 고급 언어가 자동 가비지 컬렉션 메커니즘을 가질 경우, 몇 가지 연구는 이러한 언어 런타임은 Serverless 플랫폼과 통합되어야 한다고 제안합니다
데이터 의존
현재의 클라우드 함수 플랫폼은 2 개의 클라우드 함수 간의 데이터 의존 관계를 알지 못합니다. 이러한 함수 간에 대량의 데이터를 교환할 필요가 있을 수 있습니다. 게다가 이상적이지 않은 노드 분포를 일으켜, 더 비효율적인 통신 모드를 일으킬 수 있습니다
하나의 해결책은 클라우드 프로바이더가 애플리케이션에 그 계산 그래프를 지정할 수 있는 API 를 공개하여, 더 좋은 노드 분포 결정을 지원하고, 통신을 최소한으로 억제하며,进而 성능을 향상시키는 것입니다. 실제로, 많은 범용 분산 프레임워크 (예를 들어 MapReduce, Apache Spark, Apache Beam/Cloud Dataflow), 병렬 SQL 엔진 (예를 들어 BigQuery, Azure Cosmos DB) 및 오케스트레이션 프레임워크 (예를 들어 Apache Airflow) 는 이미 내부에서 이러한 계산 그래프를 생성하고 있습니다. 원칙적으로, 이러한 시스템은 개조를 통해 클라우드 함수 환경에서 실행할 수 있으며, 계산 그래프를 클라우드 프로바이더에게 공개할 수 있습니다
P.S.AWS Step Functions 는 이미 이를 수행하고 있으며, 스테이트 머신 언어와 API 를 제공하고 있습니다
시스템
고성능, 프로비저닝 투명且경제적인 스토리지
임시와 영속화 2가지 종류의 스토리지 니즈에 대해, 임시 스토리지는 주로 클라우드 함수 간에 상태를 전달할 때의 속도와 지연 문제를 해결하는 데 사용됩니다
임시 스토리지를 제공하는 하나의 방안은 최적화된 네트워크 스택을 가진 분산 메모리 서비스를 구축하여, 마이크로초급 지연을 보장하는 것입니다. 오퍼레이팅 시스템이 프로세스에 투명한 메모리 프로비저닝을 제공하는 것처럼, 자동으로 스케일링하고, 애플리케이션 라이프사이클과 함께 생성/해제하며, 보안 격리도 제공해야 합니다. 하지만目前 RAMCloud, FaRM 은 낮은 지연과 높은 IOPS 를 보장할 수 있지만, 멀티테넌트 격리를 제공하지 않으며, Pocket 은 자동으로 스케일링할 수 없고, 스토리지를 사전에 할당해야 합니다
게다가, 통계적复用를 통해, 임시 스토리지는 현재의 Serverful 모드 메모리 효율보다 높으며, VM 인스턴스 중 애플리케이션이 다 쓰지 못하는 그 부분의 메모리도 이용할 수 있습니다
OLTP(On-Line Transaction Processing) 등의 데이터베이스 기능은 점점 더 BaaS 형식으로 제공될 가능성이 있지만, Serverless 애플리케이션보다 긴 영속화 스토리지를 필요로 하는 애플리케이션에 대해, 고성능의 Serverless 영속 스토리지도 구현해야 합니다
영속화 스토리지에 대해, SSD기반의 분산 스토리지를 이용하여 분산 메모리 캐시로 보완할 수 있습니다. 예를 들어 Anna KV 데이터베이스는, 여러 개의 기존 클라우드 스토리지 서비스를 결합함으로써 높은 비용 성능과 고성능을 실현하지만, 이 설계의 핵심 점은如何에 대량尾部 액세스 분포의 상황 하에서 낮은尾部 지연 (tail latency) 을 실현하는가입니다.此时 메모리 캐시 능력은 SSD 능력보다 훨씬 낮을 수 있습니다. 게다가, 마이크로초급 액세스 시간을 실현하는 것이 기대되는 새로운 스토리지 기술을 이용하는 것도 가능한 해결책입니다
Serverless 임시 스토리지와 마찬가지로, 영속화 스토리지 서비스도 프로비저닝 투명, 보안 격리여야 합니다. 다른 점은, Serverless 영속화 스토리지는 명시적으로 리소스를 해제할 뿐이며, 전통적 스토리지 시스템과 같습니다. 물론, 영속성을 보장해야 하며, 쓰여진 어떠한 데이터도 장애 중에서 보존될 수 있어야 합니다
조정/시그널 서비스
클라우드 함수 간은 일반적으로 생산자 - 소비자 모드를 사용하여 상태를 공유하며, 소비자는 생산자의 데이터가 이용 가능해진 것을 즉시 알아야 합니다
마찬가지로, 어떤 함수는某种의 조건을 만족할 때 다른 함수에 시그널을 전송해야 하거나, 또는 여러 개의 함수도 협력하여 작업하고 싶을 수 있습니다. 예를 들어 데이터 일관성 메커니즘을 구현합니다.此类 시그널 시스템은 마이크로초급 지연, 신뢰할 수 있는 전송 및 브로드캐스트 또는 그룹 통신에서 혜택을 받습니다. 게다가클라우드 함수 인스턴스는 개별적으로 어드레싱할 수 없으므로, 교과서적인 분산 시스템 알고리즘 (예를 들어 consensus 또는 leader election) 을 구현하는 데 사용할 수 없습니다
시작 시간 최소화
시작 시간은 3 부분으로 나뉩니다:
-
클라우드 함수 관련 리소스를 스케줄링 및 시작하여 실행
-
클라우드 함수 코드를 실행하는 데 필요한 애플리케이션 소프트웨어 환경 (예를 들어 오퍼레이팅 시스템, 라이브러리) 을 다운로드
-
애플리케이션의 특정 시작 태스크를 실행, 예를 들어 데이터 구조 및 라이브러리를 로드 및 초기화
리소스 스케줄링과 초기화 및 VPC 와 IAM 정책의 구성은 큰 지연과 오버헤드를 일으킵니다. 클라우드 프로바이더는近期 경량급 격리 메커니즘을 개발함으로써 시작 시간을 단축하는 데 초점을 맞추고 있습니다
하나의辦法은단일 코어를 이용하여 오버헤드를 절약하는 것입니다:
-
전통적 오퍼레이팅 시스템처럼 하드웨어를 동적으로 검출, 사용자 구성을 적용, 데이터 구조를 할당하는 것이 아니라, 하드웨어를 사전 구성하고, 데이터 구조를 정적으로 할당함으로써 이러한 비용을 압축
-
게다가, 단일 코어는 애플리케이션에 필요한 드라이브와 시스템 라이브러리만을 포함하며, 전통적 오퍼레이팅 시스템 공간 점유보다 훨씬 낮음
하지만 단일 코어는 특정 애플리케이션向け로 커스터마이즈되어 있으며, 여러 개의 표준 커널을 실시간으로 실행할 때, 더욱 효율적인 향상을 실현하지 못할 수 있습니다. 예를 들어 동일 VM 중의 다른 클라우드 함수 시 커널 코드 페이지링을 공유할 수 없거나, 또는 프리캐시를 통해 시작 시간을 단축할 수 없습니다
또 하나의 방법은 애플리케이션실제로 호출할 때 동적으로 증분적으로 라이브러리를 로드하는 것입니다. 예를 들어 Azure Functions중의 공유 파일 시스템
특정 애플리케이션 초기화는 개발자가 책임을 지지만, 클라우드 프로바이더는 그 API 중에서 준비 완료 시그널을 제공하여, 클라우드 함수를过早에 호출하는 것을 회피할 수 있습니다. 게다가, 클라우드 프로바이더는 시작 태스크를 사전에 실행할 수 있습니다. 특히 고객 무관심의 태스크 (예를 들어 VM 과 인기 오퍼레이팅 시스템 및 관련 라이브러리를 시작) 에 적용됩니다. 멀티테넌트 간에 핫 인스턴스 풀 (warm pool) 을 공유할 수 있기 때문입니다
네트워크
앞에서 언급한 바와 같이, 브로드캐스트, 조정, shuffle 등의 인기 통신 메커니즘은 클라우드 함수 환경에서 심각한 오버헤드를 가져옵니다. 예를 들어 K개의 클라우드 함수를 1 개의 VM 인스턴스에 패키징하면, 클라우드 함수 버전은 VM 버전보다 K회 (甚至更多) 많은 메시지를 전송하며, shuffle 장면에서는甚至 K^2회의 메시지 통신이 필요합니다
이 문제를 해결하는 3가지 방식이 있습니다:
-
클라우드 함수에 멀티코어를 제공하며, VM 인스턴스와 유사하며, 이렇게 하면 여러 개의 태스크는 데이터를 전송하기 전 또는 데이터를 수신한 후에 병합/공유 데이터를 할 수 있습니다
-
개발자에게 일부 클라우드 함수를 동일 VM 인스턴스上に 명시적으로 배치하는 것을 허용하며, 애플리케이션에 상자에서 꺼내 바로 사용할 수 있는 분산 통신 메커니즘을 제공하며, 클라우드 프로바이더가 클라우드 함수를 동일 VM 인스턴스에 할당하는 것을 가능하게
-
애플리케이션에 계산 그래프를 제공하게 하며, 클라우드 프로바이더가 관련 클라우드 함수를 동일 VM 인스턴스에 할당 (co-locate) 하여, 통신 오버헤드를 최소한으로 억제하는 것을 가능하게
하지만 앞 2가지 방식은 클라우드 프로바이더가 클라우드 함수를 할당하는 유연성을 저하시키며, 데이터 센터의 이용률을 저하시킵니다. 게다가 Serverless Computing 정신에 반합니다. 클라우드 개발자에게 시스템 관리를 고려하게 강제하기 때문입니다
보안
Serverless는 이전의安全责任划分을 어지럽히며, 많은 책임을 클라우드 사용자에서 클라우드 프로바이더로 이전했지만, 그것들을 근본적으로 변경한 것은 아닙니다. 그러나, Serverless는 애플리케이션 간 멀티테넌트 리소스 공유의 고유 리스크에도 대처해야 합니다
랜덤 스케줄링과 물리 격리
물리적 공동 주재 (co-residency) 는 클라우드 환경 하에서 하드웨어 레벨의 사이드 채널과 Rowhammer공격의 열쇠로,此类 공격은 먼저 피해자와 동일 물리 호스트上に 있어야 합니다
클라우드 함수의 단명 성능은 어떤 정도 공격자가 병행 실행되고 있는 피해자를 식별하는 능력을 제한할 수 있습니다. 랜덤 또는 적대자 감지 (adversary-aware) 스케줄링 알고리즘은 공격자와 피해자가 동일 호스트에 있는 리스크를 저하시키며, 물리적 공동 주재 공격을 더 어렵게 합니다. 하지만 이러한안전 조치는 할당 (VM) 방식의 시작 시간, 리소스 이용과 통신 최적화와 충돌할 수 있습니다
세밀한 안전 환경
클라우드 함수는 세밀한 구성을 필요로 하며, 비밀 키, 스토리지 오브젝트 및 로컬 임시 리소스에 대한 액세스를 포함합니다. 기존의 Serverful 애플리케이션에서 보안 정책을 변환하고, 클라우드 함수 중의 동적 사용을 위해 (이러한 정책을) 충분히 표현할 수 있는 보안 API 를 제공해야 합니다. 예를 들어, 클라우드 함수는 몇 가지 보안 특권을 다른 클라우드 함수 또는 클라우드 서비스에 위임할 필요가 있을 수 있습니다
암호화 보호된 안전 환경 중, 기능 기반의 액세스 제어 메커니즘은此类 분산 보안 모델의 자연스러운 선택일 수 있습니다. 다방 설정 중에서 정보 플로우 제어를 사용하여 크로스 함수 액세스 제어를 수행하는 것을 제안합니다. 예를 들어 클라우드 함수를 위해 단기 키와 인증서를 동적으로 생성하지만, 보안 메커니즘 분산 관리상의其它 문제 (예를 들어不对等과 인증서 실효) 는 악화됩니다
시스템 레벨에서 보면, 사용자는 함수 레벨의 세밀한 보안 격리를 필요로 하며, 적어도 옵션으로. 함수 레벨 샌드박스를 제공하는 난점은较短은 시작 시간을 보장하는 것으로, 중복 함수 호출에 대해 실행 환경을 공유 상태 방식으로 캐시하지 않는 것입니다. 로컬 인스턴스 스냅샷을 통해, 각 함수가 깨끗한 상태에서 시작할 수 있도록 하거나, 또는 경량급 가상화 기술 (예를 들어 라이브러리 오퍼레이팅 시스템, 단일 코어, 마이크로 VM 등) 을 채택하여, 시작 시간을 수십 밀리초까지 단축할 수 있지만, 그 안전성이 전통적 VM 의 정도에 도달할 수 있는지는 불명확합니다. 긍정적인 면은, Serverless중의 프로바이더 관리와 단기 인스턴스는 더 신속하게 취약점을 수정할 수 있다는 것입니다
물리적 공동 주재 공격을 방호하고 싶은 사용자에게, 하나의 해결책은 물리 격리를 요구하는 것입니다. 클라우드 프로바이더는 고객에게 고급 옵션을 제공하며, 전용 물리 호스트上で 클라우드 함수를 시작할 수 있습니다
모호한 Serverless
클라우드 함수는 통신 중에서 액세스 패턴 (access patterns) 과 타이밍 정보 (timing information) 를 누설할 수 있습니다
serverful 애플리케이션에 대해, 일반적으로 데이터를 배치로 취득하여, 로컬에 캐시합니다. 클라우드 함수는 단명이며, 클라우드 환경 중에서 널리 분포되어 있으므로, 네트워크 전송 모드는 기밀 정보 (예를 들어 자사 직원) 를 누설할 수 있습니다. 데이터가 엔드 투 엔드로 암호화되어いても, Serverless 애플리케이션을 많은 작은 함수로 분해하는 경향은 이러한 안전隐患을 악화시킵니다. 주요한 보안 문제는 외부 공격자에서 오지만, 직원으로부터의 공격도 모호 알고리즘을 통해 방호할 수 있습니다. 하지만, 이렇게 하는 오버헤드는 일반적으로 매우 높습니다
아키텍처
하드웨어 이질성, 가격 책정 및 관리의 용이성
클라우드 컴퓨팅 중에서 지배적인 x86 마이크로프로세서는 성능上에서 거의 향상이 없습니다 (2017 년 단일 프로그램 성능 향상은 단지 3%). 이 추세가 계속된다면, 20년 이내에 성능은 배가될 수 없습니다. 마찬가지로, 칩 당 DRAM 용량도 이미 한계에 가까워지고 있으며, 현재 판매 중인 16Gbit DRAM 이 있지만, 32G DRAM 의 칩을 제조할 수 없는 것 같습니다. 유일하게 위로할 수 있는 것은, 이 거북이 걸음 같은 변화는 서플라이어에게 오래된 머신이 손모될 때 여유 있게 교체할 수 있게 하며, Serverless 시장에는 거의 영향이 없다는 것입니다
범용 마이크로프로세서의 성능 문제는 더 빠른 계산에 대한 니즈를 감소시키지 않습니다. 2가지 방향이 있습니다. 고급 스크립트 언어 (예를 들어 JavaScript 또는 Python) 로 작성된 함수에 대해, 하드웨어와 소프트웨어의 공동 설계를 통해 언어 특정의 커스텀 프로세서를 생성할 수 있으며, 그 실행 속도는 1에서 3자리 빠릅니다. 또 하나의 방향은*특정 분야 아키텍처 (DSA, Domain Specific Architectures)*입니다. DSA 는 특정 문제 분야向け로 커스터마이즈할 수 있으며, 해당 분야에 대해 현저한 성능과 효율 향상이 있지만,其它 분야에서는 성능이 좋지 않습니다. 그래픽 처리 유닛 (GPU, Graphical Processing Units) 은 오랫동안 그래픽 처리를 가속하는 데 사용되어 왔습니다. 기계 학습 분야의 DSA 도 보기 시작했습니다. 예를 들어 텐서 처리 유닛 (TPU, Tensor Processing Units) 으로, TPU 는 CPU 보다 30 배 빠릅니다. 이는 많은实例 중의一例로, DSA 를 사용하여 ��독 분야向けの 범용 프로세서를 강화하는 것이 상태가 될 것입니다
하드웨어 이질성에 대해, 마찬가지로 2가지 방향이 있습니다:
-
Serverless 클라우드는多种의 인스턴스 타입을 포함하며, 가격 책정은 사용된 구체적인 하드웨어에 의존
-
클라우드 프로바이더는 언어 기반의 액셀러레이터와 DSA 를 자동으로 선택 가능. 이 자동화는 클라우드 함수가 사용하는 소프트웨어 라이브러리 또는 언어에 기반하여 암묵적으로 완료할 수 있습니다. 예를 들어 CUDA 코드는 GPU 를 사용하고, TensorFlow 코드는 TPU 를 사용. 또는, 클라우드 프로바이더는 클라우드 함수의 성능을 모니터링하고,次回 실행 시에 그것들을 더 적절한 하드웨어로 이전할 수 있습니다
x86 의 SIMD 명령어에 대해, Serverless 는 이질성에 직면하고 있습니다. AMD 와 Intel 은 각 클럭 사이클에서 실행되는 조작 수를 증가하고, 신규 명령어를 추가함으로써, x86 명령어 집합 중의 이 부분을 신속하게 개선하고 있습니다. SIMD 명령어를 사용하는 애플리케이션에 대해, 최근의 Intel Skylake 마이크로프로세서 (512비트 폭 SIMD 명령어) 上에서 실행하는 것은 오래된 Intel Broadwell 마이크로프로세서 (128비트 폭 SIMD 명령어) 上에서 실행하는 것보다 훨씬 빠릅니다. 현재 AWS Lambda중 이 2가지 종류의 마이크로프로세서는 같은 가격으로 공급되고 있지만, Serverless 사용자는 더 빠른 SIMD 하드웨어를 사용하고 싶다는 것을 표명할 방법이 없습니다. 우리看来, 컴파일러는哪种의 하드웨어가 가장 적절한지建議을 제공해야 합니다
액셀러레이터가 클라우드 환경 중에서 점점 더 보급됨에 따라, Serverless 클라우드 프로바이더는 이질성의 곤경을 무시할 수 없게 됩니다. 특히 합리적인 구제 조치가 존재하기 때문입니다
七.Serverless 에 대한 6 가지 오해
클라우드 함수는 매분의 가격이 더 비싸므로, Serverless 는 Serverful보다 비싸다
Serverless 의 가격 책정은 단순히 리소스 인스턴스가 아니라, 가용성 중복, 모니터링, 로그 기록 및 스케일링 등의 모든 시스템 관리 기능을 포함하기 때문입니다. 게다가, Serverless 스케일링 입자는 더 세밀하므로, 실제로 사용되는 계산량은 더 효율적일 수 있습니다. 더 중요한 것은, Serverless 는 클라우드 함수를 호출하지 않을 때 지불 불필요하므로, Serverful보다 훨씬 쌀 수 있습니다
Serverless 는 예측 불가능한 비용을 생성할 수 있다
某些의 사용자에게 있어, 즉시 사용 즉시支払이는 비용이 예측 불가능함을 의미하며, 이는 많은 조직의 예산 관리 방식과 모순됩니다. 예를 들어 예산 승인 시에 미래 1 년간의 Serverless 서비스 비용을 알고 싶음. 클라우드 프로바이더는 패키지 가격 책정 (bucket-based pricing) 을 제공함으로써 이 니즈를 완화할 수 있습니다. 전화 회사가 특정 사용량에 대해 고정 요금 패키지를 제공하는 것처럼,甚至 Serverless 보급 후, 역사 상황에 기반하여 Serverless 서비스 비용을 예측할 수 있습니다
Serverless 는 Python등의 고급 언어를 사용하여 프로그래밍하므로, 다른 Serverless 플랫폼에 쉽게 이식 가능하다
다른 플랫폼 하에서는, 함수 호출, 패키징 방식이 다를 뿐만 아니라, 많은 Serverless 애플리케이션은 표준화되지 않은 BaaS 제품/서비스 생태계 (예를 들어 오브젝트 스토리지, KV 데이터베이스, 로그와 모니터링 등, 이식성을 실현하기 위해) 에 의존하고 있습니다. 표준화 API 를 형성해야 합니다. 예를 들어 Google 의 Knative 프로젝트는 이 방향으로 탐색하고 있습니다
Serverless 하에서는, 서플라이어绑定 (vendor lock-in) 정도가 더 강하다
애플리케이션 이식이 어려우면 서플라이어와의 강绑定이 존재하지만, 프레임워크가 제공하는 크로스 클라우드 지원은 이 강绑定을 완화할 수 있습니다
클라우드 함수는 극히 낮은 지연 성능 요구를 가진 애플리케이션에 대처할 수 없다
Serverful 인스턴스는此类 장면に対処할 수 있는 것은 그것들이 항상 실행되고 있기 때문이며, 리クエスト을 수신한 후에 신속하게 응답할 수 있습니다. 하지만 클라우드 함수의 시작 지연이 애플리케이션에게 있어 만족할 수 없는 경우, 몇 가지 전략을 채택하여 완화할 수 있습니다. 예를 들어 정기적으로 클라우드 함수를 실행하여 웜업
소위 탄력적 서비스는 Serverless 의 실제 유연성 요구를 충족시킬 수 있는 것은 적다
「탄력적」(elastic) 은 Serverless중에서는 용량을 신속하게 변경할 수 있고, 사용자 개입越少越好이며, 사용하지 않을 때는 0 까지 축소할 수 있는 것을 가리킵니다. 클라우드 프로바이더가 제공하는 것은 일반적으로 유한 탄력성 (예를 들어 Redis 인스턴스를 정수 개만 인스턴스화 가능, 용량을 명시적으로 구성할 필요 있음,甚至 몇 분간 수요 변화에 응답할 필요 있음) 만이며, 이러한 요구에 도달하지 않았으므로, 따라서 많은 Serverless 우위성을 잃고 있습니다
명확한 기술 정의와 지표가 없으므로, 「탄력적」이라는 말은 모호不清합니다
八.정리와 예측
단순화된 프로그래밍 환경을 제공함으로써, Serverless 는 클라우드를 더 사용하기 쉽게 하여, 더 많은 사용자를 유치합니다. Serverless 는 FaaS 와 BaaS 제품을 포함하며, 클라우드 프로그래밍의 중요한 성숙을 나타냅니다. 현재 Serverful 이 애플리케이션 개발자에게 가져오는 수동 관리와 리소스 최적화의 부담을 생략합니다. 이 성숙은 40년 전에 어셈블리 언어에서 고급 언어로 향했던 것과 같습니다
Serverless 의 애플리케이션은 폭증할 것으로 예측되며, 하이브리드 클라우드 로컬 애플리케이션은 점점 더 적어질 것입니다.某些의 배포는 법규 제약과 데이터 관제 규칙으로 인해 현상을 유지할 수 있습니다
이미 일정의 성공을 거두었지만, 아직 많은 도전이 존재합니다. 이러한 문제를 극복할 수 있다면, Serverless 를 더 광범위한 애플리케이션 중에서 유행하게 할 수 있습니다. 첫걸음은 Serverless 임시 스토리지로, 합리적인 비용으로 낮은 지연, 높은 IOPS(의 임시 스토리지 서비스) 를 제공해야 하지만, 경제적인 장기 스토리지를 제공할 필요는 없습니다.第二类 애플리케이션은 Serverless 영속 스토리지에서 혜택을 받습니다. 그것들은 확실히 장기 스토리지를 필요로 하기 때문입니다. 새로운 비휘발성 메모리 technology 는此类 스토리지 시스템에 도움이 될 수 있습니다.其它 애플리케이션은 낮은 지연의 시그널 서비스 및 인기 통신 메커니즘의 지원에서 혜택을 받습니다
Serverless 미래의 2 가지 중대한 도전은 보안을 향상시키고, 전용 프로세서에서 올 수 있는 비용 성능 개선에 적응하는 것입니다. Serverless 가 이미 가지고 있는 몇 가지 특성은 이러한 도전에 대처하는 데 도움이 됩니다. 예를 들어:
-
물리적 공동 주재는 사이드 채널 공격의 필요 조건으로, Serverless중에서는 (동일 물리 머신上に 있는지 여부를) 확인하기 어렵고, 방호 조치를 취하는 것도 쉽습니���. 예를 들어 클라우드 함수를 랜덤하게 분포
-
고급 언어 (예를 들어 JavaScript, Python 또는 TensorFlow) 로 프로그래밍하는 클라우드 함수는, 프로그래밍 추상 레벨을 향상시켜, 저변 하드웨어 혁신에 더 유리합니다
마지막으로, Serverless Computing 이 다음 10 년 중에서:
-
새로운 BaaS 스토리지 서비스가 나타나, 더 많은 타입의 애플리케이션이 Serverless 하에서 실행될 수 있게 됩니다.此类 스토리지는 로컬 데이터 블록 스토리지의 성능에 도달하며, 임시적과 영속화적의 2가지 종류로 나뉩니다. 전통적 x86 마이크로프로세서와 비교하여, serverless 하 컴퓨터 하드웨어의 이질성은 훨씬 큽니다
-
serverful 보다 보안 프로그래밍이 쉬워집니다. 고급 프로그래밍 추상, 및 클라우드 함수의 세밀한 격리 덕분에
-
Serverless 의 과금 모델은 개선될 것입니다. 그 비용이 serverful 보다 높을 이유가 없기 때문입니다. 따라서 绝大多数의 어떠한 규모로 실행되는 애플리케이션도 Serverless 하에서 비용은 높지 않으며,甚至 낮아집니다
-
Serverful 은 BaaS 서비스를 촉진하는 데 사용됩니다. Serverless上에서 구현하기 어려운 애플리케이션 (예를 들어 OLTP 데이터베이스 또는 큐 등의 통신 메커니즘 등) 은, 클라우드 프로바이더 서비스 세트의 일부로 제공될 수 있습니다
-
serverful 은 소실되지 않지만, 그 중요성은 Serverless 가 현재의 한계를 돌파함에 따라 점차 저하됩니다
-
Serverless 는 클라우드 시대의 디폴트 계산 모드가 되며,很大程度上에서 serverful 을取代하며, Client-Server 시대를 종료시킵니다
아직 댓글이 없습니다