一.네트워크의 신뢰성에서부터 말하다
머신 간은 물리 연결 (케이블, 전화선, 전파, 위성, 적외선 빔 등) 을 통해 신호를 전달하고, 정보 교환을 수행할 수 있습니다:
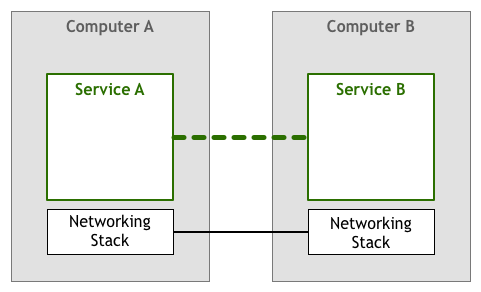
그러나, 데이터 전송 중에는 몇 가지 이상 상황이 발생할 수 있습니다. 예를 들어:
-
데이터 손실: 데이터 패킷은 버퍼가 이미 가득 찬 라우터에 도달하여, 버려질 수 있습니다
-
순서 오류: 한 묶음의 데이터 패킷은 한가함/바쁨 정도가 다른 여러 라우터를 경유하여,不同程度的인 지연이 발생하고, 마지막으로 도달하는 순서는 발송 시의 순서와 일치하지 않을 수 있습니다
따라서 적어도 패킷 손실 재전송, 순서 재구성 등의 제어 메커니즘이 필요합니다. 초기에는 이 부분의 작업은 네트워크 서비스/애플리케이션에 의해 완료되었습니다 (애플리케이션 층에서 비즈니스 로직과 공존):
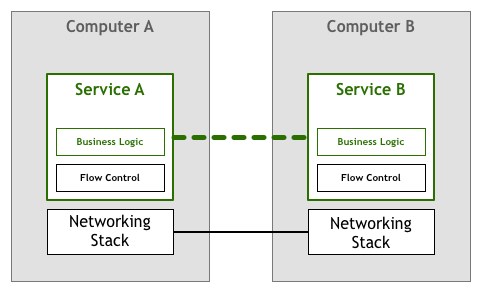
나중에, 이 부분의 작업은 네트워크 스택 (오퍼레이팅 시스템의 네트워크 층) 으로下沉하고, TCP/IP 등의 표준 네트워크 프로토콜에 의해 데이터 전송의 신뢰성이 보증되었습니다 (아래 그림의 굵은 선):
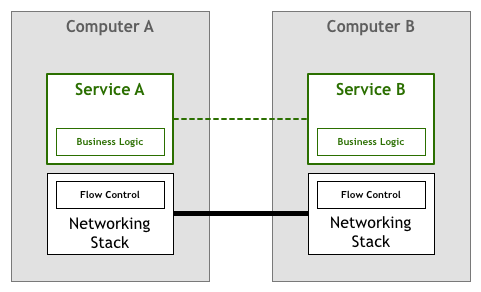
二.마이크로서비스 아키텍처 하의 신뢰성 과제
네트워크 프로토콜이 제공하는 신뢰성 보증은 소형의 다 머신 상호 연결 장면에는 충분하지만, 대규모 분산형 장면 (예: 마이크로서비스 아키텍처) 에서는, 전체의 신뢰성을 보증하기 위해 더 많은 메커니즘을 도입할 필요가 있습니다. 예를 들어:
-
Service Discovery 메커니즘: 서비스 등록 조회 메커니즘을 통해, 하나의 마이크로서비스가 다른 하나를 찾는 것을 가능하게 하여, 그에 의해 동적 스케일링, 및 장애 전환을 허용
-
차단 메커니즘 (Circuit Breaker pattern): 차단 보호를 제공 (전기 계전기의 브레이커 떨어짐과 같이), 어떤 서비스가 사용 불가로 인해 연쇄 장애를 일으키는 것을 방지. 예를 들어 조작이 성공하지 못해 미친 듯이 재시도하고, 리퀘스트가 퇴적하며, 심지어 관련 리소스를 소진하고, 시스템 중의 무관계한 부분도 이로 인해 고장 발생
마찬가지로, 이 부분의 작업도 초기에는 마이크로서비스에 의해 완료되었습니다 (마이크로서비스 내에서 비즈니스 로직과 공존):
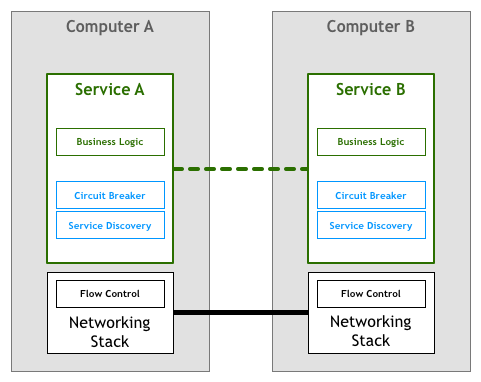
이어서 Finagle, Proxygen 등의 오픈 소스 라이브러리가 나타나, 전문 라이브러리에 의해 이러한 작업을 완료하고, 각 서비스에서 같은 제어 로직을 반복할 필요가 없어졌습니다:
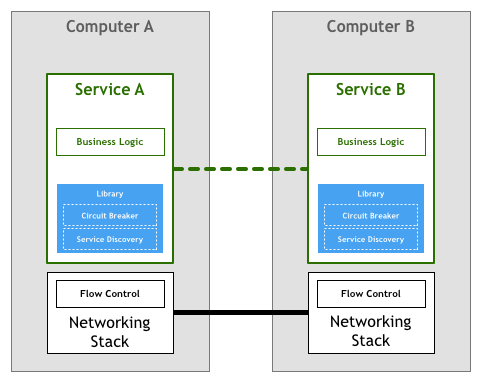
그러나, 시스템 중의 서비스 수의 증가에 따라, 이 방식도 몇 가지 문제를 노출했습니다:
-
풀 부분의 리소스 투입: 서드파티 라이브러리를 시스템의 나머지 부분과 연결하기 위해 리소스를 투입할 필요가 있음
-
라이브러리가 마이크로서비스의 기술 선택을 제한: 이러한 라이브러리는 일반적으로 플랫폼 고유의 것으로, 특정 런타임 또는 프로그래밍 언어만 지원하며, 마이크로서비스의 기술 선택에 제한을 가져옴.毕竟, 마이크로서비스의 큰 특징 중 하나는 다른 프로그래밍 언어를 사용하여 다른 서비스를 작성하는 것을 허용 하는 것
-
라이브러리의 유지 비용: 라이브러리 자체도 지속적인 유지 업그레이드가 필요하며, 업데이트할 때마다 모든 서비스를 재배포할 필요가 있음. 서비스에 아무런 변경이 없는 경우에도
이렇게 보면, 라이브러리는 이상적인 해결책이 아닌ようだ
三.마이크로서비스 제어를 네트워크 스택으로下沉?
애플리케이션 층에서 해결하는 것이 적절하지 않다면, 같은 방식으로 네트워크 스택으로下沉할 수 있을까?
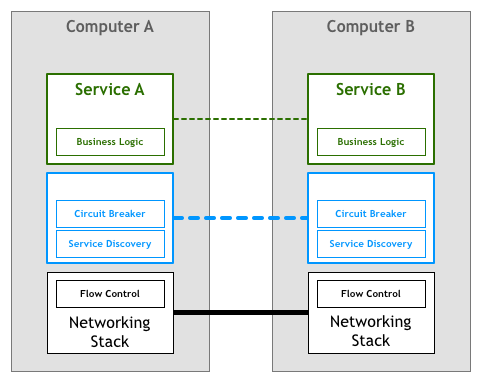
일반적인 기초 통신 메커니즘과는 달리, 이러한 애플리케이션 서비스 관련 제어 메커니즘을 하층 네트워크 스택에 구현시키는 것은 매우 어렵고, 그대로下沉하는 것은 통하지 않음
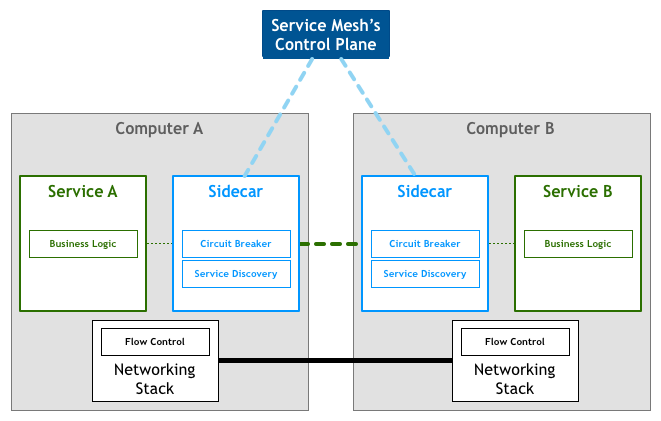
Sidecar
(서비스) 내부에서도, 아래도 아니어서, 마지막에 옆에 놓인:
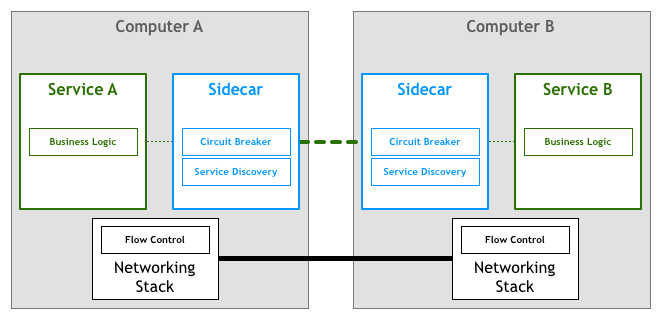
즉, 프록시를 통해 이러한 네트워크 제어를 실현하고, 모든 출입 트래픽이 프록시를 경유함. 이를 Sidecar 라고 함:

Sidecar 는 보조 프로세스로서, 애플리케이션과 함께 실행되고, 추가 기능을 제공
문제는 네트워크 프록시를 통해 완벽하게 해결된 것처럼 보였고, 업계에도 몇 가지 오픈 소스 방안이 나타났습니다:
그러나, 이러한 방안은 모두 특정 기초 컴포넌트 위에 구축되어 있으며, 예를 들어 Nerve 와 Synapse 는 Zookeeper 에 기반하고, Prana 는 Eureka 에 기반하며, 다른 기초 컴포넌트에 적응할 수 없음
그렇다면, 충분히 유연하고, 기초 컴포넌트에 의존하지 않는 해결책이 있을까?
있음. Service Mesh 라고 함
四.Sidecar 에서 Service Mesh 로
각 서비스에 프록시 Sidecar 를 1 개配套하고, 서비스 간은 프록시를 통해서만 상호 통신하면, 최종적으로 이러한 배포 모델을 얻게 됨:
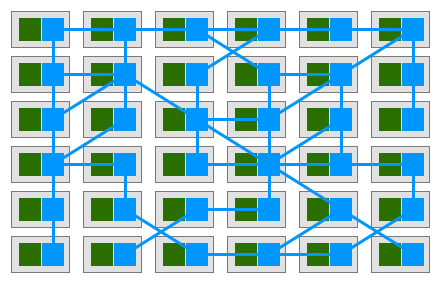
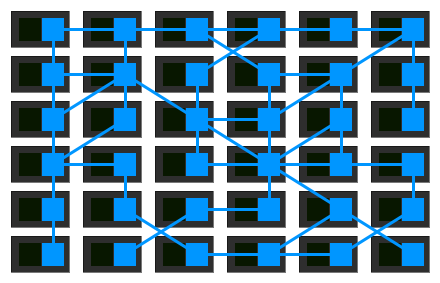
즉, 프록시 간이 상호 연결하여 망상의 그리드를 형성하고, 이를 Service Mesh(서비스 그리드) 라고 함:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It's responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application.
서비스 간 통신을 처리하기 위한 전용 인프라스트럭처 층. 현대의 클라우드 네이티브 애플리케이션을 구성하는 복잡한 서비스 토폴로지를 통해 리퀘스트의 신뢰성 있는 배달을 담당
구체적으로는, Service Mesh 는 Service Discovery, 부하 분산, 암호화, 관측/추적, 인증 및 인가, 및 차단 메커니즘 등의 지원을 제공할 수 있음:
The mesh provides critical capabilities including service discovery, load balancing, encryption, observability, traceability, authentication and authorization, and support for the circuit breaker pattern.
Sidecar 에서 Service Mesh 로, 핵심은 더 높은 시점으로 이러한 프록시를捉어, 그것들이 형성하는 네트워크가 가지는 가치를 발견하는 것:
五.Service Mesh + 배포 플랫폼
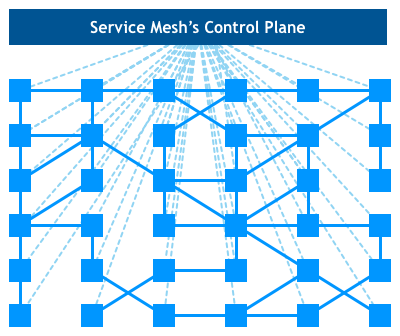
이어서, Service Mesh 는 자연스럽게 (Service 를 장악하는) 배포 플랫폼과 불꽃을 튀겼음 (예: Istio + Kubernetes), 더욱이 제어 층 (Control Plane) 을 파생하여, 이 인프라스트럭처 층을 설정 가능하게 함:
최종적으로 제어 층 + 데이터 층의 상하 구조를 형성:

그 중에서, 인스턴스 간의 네트워크 트래픽을 관리하는 부분을 데이터 층 (Data Plane) 이라고 하고, 데이터 층의 동작은 제어 층 (Control Plane) 이 생성하는 설정 항목에 의해 제어되며, 제어 층은 일반적으로 API, CLI 및 GUI 등의 여러 방식으로 애플리케이션을 관리
즉:
아직 댓글이 없습니다