시작하며
크고 빠르면서 저렴하기까지 한 저장 장치를 가질 수는 없기에, 많은 트레이드오프(trade-off, 절충안)의 산물이 등장했습니다.
-
CPU 레지스터: 매우 빠르지만, 저렴하지 않고 용량도 작음
-
RAM: 아주 빠르지도 아주 크지도 않지만, 꽤 저렴함
-
하드 디스크: 매우 저렴하고 용량이 크지만, 읽고 쓰기가 느림
그 결과 다음과 같은 계층 구조가 형성되었습니다.

마찬가지로 시스템 설계에서도 많은 트레이드오프에 직면하게 됩니다.
-
성능과 확장성
-
지연 시간과 처리량
-
가용성과 일관성
1. 성능과 확장성
확장 가능(Scalable)하다는 것은 서비스가 자원을 추가하는 방식에 비례하여 성능을 향상시킬 수 있음을 의미합니다.
A service is scalable if it results in increased performance in a manner proportional to resources added.
성능 향상은 더 많은 작업량을 감당할 수 있거나, 더 크고 무거운 작업(예: 데이터량 증가)을 처리할 수 있는 것으로 나타납니다.
P.S. 물론 중복성 도입과 같이 서비스의 신뢰성을 높이기 위해 자원을 추가할 수도 있습니다.
하지만 자원을 추가하면 다양성도 도입됩니다. 일부 노드는 다른 노드보다 처리 능력이 강력할 수 있고, 오래된 노드는 약할 수 있습니다. 시스템은 이러한 이질성(heterogeneity)에 적응해야 하므로, 균일성에 의존하는 알고리즘은 새 노드를 충분히 활용하지 못해 성능에 영향을 미칠 수 있습니다.
2. 지연 시간과 처리량
*지연 시간(Latency)*은 작업을 수행하여 결과를 내는 데 필요한 시간을 말합니다.
Latency is the time required to perform some action or to produce some result.
측정 단위는 시간이며, 초(seconds), 나노초(nanoseconds), 시스템 클럭 주기(clock periods) 등이 있습니다.
*처리량(Throughput)*은 단위 시간당 처리할 수 있는 작업 수 또는 생산할 수 있는 결과 수를 말합니다.
Throughput is the number of such actions executed or results produced per unit of time.
단위 시간당 생산되는 것으로 측정되며, 예를 들어 메모리 대역폭(memory bandwidth)은 메모리 시스템의 처리량을 측정하는 데 사용됩니다. 웹 시스템의 경우 다음과 같은 측정 단위가 있습니다.
-
QPS(Queries Per Second): 정보 검색 시스템(검색 엔진, 데이터베이스 등)의 초당 검색 트래픽을 측정
-
RPS(Requests Per Second): 요청-응답 시스템(웹 서버 등)이 초당 처리할 수 있는 최대 요청 수
-
TPS(Transactions Per Second): 넓은 의미에서는 초당 실행할 수 있는 원자적(atomic) 작업 수, 좁은 의미에서는 DBMS가 초당 실행할 수 있는 트랜잭션 수
P.S. 웹 서비스의 처리량을 측정할 때 QPS를 사용하기도 하지만, 더 정확한 단위는 RPS입니다.
마찬가지로 낮은 지연 시간과 높은 처리량을 모두 갖출 수 없으므로, 절충의 원칙은 다음과 같습니다.
Generally, you should strive for maximal throughput with acceptable latency.
지연 시간이 수용 가능한 수준임을 보장하는 전제하에 최대의 처리량을 추구해야 합니다.
3. 가용성과 일관성
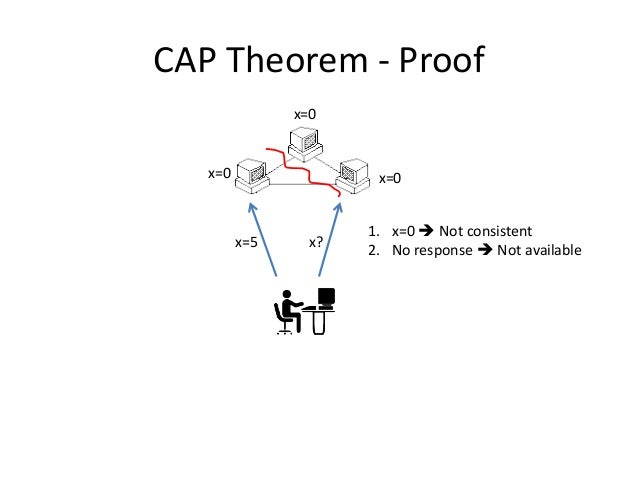
가용성과 일관성과 관련하여 유명한 *CAP 정리(CAP theorem)*가 있습니다.
Of three properties of distributed data systems - consistency, availability, partition tolerance - choose two. —— Eric Brewer, CAP theorem, PODC 2000
분산 컴퓨터 시스템에서는 일관성, 가용성, 분할 내성 세 가지 중 두 가지만 선택할 수 있습니다(게다가 분할 내성은 필수입니다).
-
일관성(Consistency): 모든 읽기 요청은 가장 최근에 쓰인 결과를 받거나 에러를 반환해야 함
-
가용성(Availability): 모든 요청은 정상적인 응답을 받아야 하지만, 가장 최신 정보임을 보장하지는 않음
-
분할 내성(Partition Tolerance): 네트워크 장애로 인해 노드 간 통신이 단절(분할)되더라도 시스템은 계속 작동해야 함
네트워크는 완벽하게 신뢰할 수 없으므로 분할 내성(P)은 반드시 보장해야 합니다(P 필수). 일부 노드에 네트워크 장애가 발생했을 때 선택할 수 있는 옵션은 두 가지입니다.
-
작업 취소: 일관성을 확보할 수 있지만, 가용성은 떨어집니다(사용자는 타임아웃 오류를 받을 수 있음). 즉, CP(Consistency and Partition Tolerance)이며, 원자적 읽기/쓰기가 필요한 상황에 적합합니다.
-
작업 계속: 가용성을 보장하지만, 일관성 위험이 있습니다(반환되는 정보가 예전 것일 수 있음). 즉, AP(Availability and Partition Tolerance)이며, 최종 일관성(Eventual consistency)을 수용할 수 있는 상황에 적합합니다.
즉, P를 반드시 만족해야 하는 전제 조건에서(네트워크 장애는 시스템 외부의 통제 불가능한 요인이므로 선택의 여지가 없음), C와 A 사이에서만 절충할 수 있습니다. 일관성을 보장하거나(가용성 희생), 가용성을 보장해야(일관성 희생) 합니다. 즉:
Possibility of Partitions => Not (C and A)
(10. Why do some people get annoyed when I characterise my system as CA?에서 발췌)
P.S. 물론 중앙 집중식 시스템(예: RDBMS)에서는 네트워크 신뢰성 문제가 없으므로 C와 A를 모두 달성할 수 있습니다.
4. 일관성 패턴
동일한 데이터의 복사본이 여러 개 존재한다면 일관성을 보장할 방법을 고려해야 합니다. 엄격한 일관성이란 최신 데이터를 읽거나 아니면 오류가 발생해야 함을 의미합니다.
하지만 모든 상황에서 이러한 수준의 일관성이 요구되는 것은 아니므로, 약한 일관성 및 최종 일관성과 같은 절충안이 등장했습니다.
약한 일관성(Weak consistency)
데이터를 쓴 후, 그 데이터가 바로 읽힌다는 보장이 없습니다.
*약한 일관성 패턴(Weak consistency)*은 VoIP 통화, 영상 채팅, 실시간 멀티플레이어 게임 등 실시간 상황에 적합합니다. VoIP 통화 중 연결이 끊겼다 다시 연결된 후에는 단절된 시간 동안의 통화 내용을 다시 받을 수 없습니다.
최종 일관성(Eventual consistency)
데이터를 쓴 후, 데이터를 비동기적으로 복제하여 결국에는 데이터를 읽을 수 있게 보장합니다.
*최종 일관성 패턴(Eventual consistency)*은 DNS, 이메일 등 고가용성 시스템에 적합합니다.
강한 일관성(Strong consistency)
데이터를 쓴 후, 데이터를 동기적으로 복제하여 즉시 읽을 수 있습니다.
*강한 일관성 패턴(Strong consistency)*은 파일 시스템, RDBMS 등 트랜잭션 메커니즘이 필요한 상황에 적합합니다.
5. 가용성 패턴
가용성 보장 측면에서는 페일오버(Fail-over)와 복제(Replication) 두 가지 주요 방식이 있습니다.
페일오버(Fail-over)
한 노드가 다운되면 신속하게 다른 노드로 대체하여 다운타임을 줄입니다. 구체적으로 두 가지 페일오버 패턴이 있습니다.
-
Active-Passive(액티브-패시브, 주-종 페일오버): Active 서버만 트래픽을 처리하며, 작동 중인 Active 서버와 대기 중인 Passive 서버 간에 하트비트를 주고받습니다. 하트비트가 끊어지면 Passive 서버가 Active 서버의 IP 주소를 넘겨받아 서비스를 복구합니다. 다운타임의 길이는 Passive 서버가 웜 부팅(Hot Standby)인지 콜드 부팅(Cold Standby)인지에 따라 달라집니다.
-
Active-Active(액티브-액티브, 주-주 페일오버): 두 대의 서버가 모두 트래픽을 처리하며 부하를 분담합니다.
Active-Passive 모드에서는 (전환 시) 데이터 손실 위험이 있으며, 어떤 방식을 사용하든 페일오버는 하드웨어 리소스와 복잡성을 증가시킵니다.
복제(Replication)
마스터-슬레이브(주-종) 복제와 마스터-마스터(주-주) 복제로 나뉘며, 주로 데이터베이스에서 사용되므로 여기서는 자세히 다루지 않겠습니다.
가용성 지표
가용성은 일반적으로 '9의 개수'로 측정되며, 운영 시간 대비 서비스 사용 가능 시간의 백분율을 나타냅니다.
3개의 9는 가용성이 99.9%임을 의미합니다.
| 기간 | 허용 다운타임 |
|---|---|
| 연간 다운타임 | 8시간 45분 57초 |
| 월간 다운타임 | 43분 49.7초 |
| 주간 다운타임 | 10분 4.8초 |
| 일간 다운타임 | 1분 26.4초 |
4개의 9는 99.99% 가용성입니다.
| 기간 | 허용 다운타임 |
|---|---|
| 연간 다운타임 | 52분 35.7초 |
| 월간 다운타임 | 4분 23초 |
| 주간 다운타임 | 1분 5초 |
| 일간 다운타임 | 8.6초 |
특이하게도 여러 구성 요소로 이루어진 서비스의 경우, 전체 가용성은 이러한 구성 요소가 직렬로 연결되어 있는지 병렬로 연결되어 있는지에 따라 달라집니다.
// 직렬
Availability (Total) = Availability (Foo) * Availability (Bar)
// 병렬
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
가용성이 100%에 도달하지 못하는 두 서비스를 결합할 때, 직렬인 경우 전체 가용성은 낮아지고(99.9% * 99.9% = 99.8%), 병렬인 경우 전체 가용성은 높아집니다(1 - 0.1% * 0.1% = 99.9999%).
아직 댓글이 없습니다