일.불변 데이터 구조
데이터 구조가 불변이므로, 증, 삭, 개 등의 조작 결과는 새로운 데이터 구조를 재작성하는 것뿐입니다. 예를 들어:
reverse' xs
| length xs <= 1 = xs
| otherwise = last xs : (reverse' (init xs))
List 를 반전하는 것은 트럼프 산을 역순으로 하는 것과 같아, 가장 아래 카드를 뽑아 새로운 산 위에 놓고, 다음으로 아래에서 2 번째를 그 아래에 놓습니다……따라서, 산의 반전 조작 결과는 실제로는 새로운 산을 만들어내는 것입니다. 새로운 산은 이전 카드로 구성되어 있지만, 원래 산과는 아무 관계도 없으며, 상태의 파기 에 유사합니다. 원래 산을 직접 버리고, 유지수정하는 것이 아니라, 예를 들어 (배열 반전의 일반적 방법, JS 로 기술):
function swap(arr, from, to) {
let t = arr[from];
arr[from] = arr[to];
arr[to] = t;
}
function reverse(arr) {
for (let i = 0; i < arr.length / 2; i++) {
swap(arr, i, arr.length - 1 - i);
}
return arr;
}
데이터 구조가 가변인 경우, 배열 반전은 n/2 회의 요소 교환으로 실현할 수 있습니다. 양자의 차이는, 가변 데이터 구조에서는 데이터 구조를 확장 가능한 재이용 컨테이너로 간주하고, 데이터 구조에 대한 조작은 컨테이너 내의 값에 대한 증, 삭, 개입니다. 불변 데이터 구조에서는 데이터 구조를 데이터 정수로 간주하고, 확장도 재이용도 할 수 없으므로, 데이터 구조에 대한 조작은 잘 비슷하지만 조금 다른 데이터를 재작성하는 것에 상당합니다. 예를 들어 swap:
swap _ _ [] = []
swap i j xs
| i == j = xs
| i > j = swap j i xs
| otherwise = (take i xs) ++ [xs !! j] ++ (sublist (i + 1) (j - 1) xs) ++ [xs !! i] ++ (drop (j + 1) xs)
where sublist _ _ [] = []
sublist a b xs
| a > b = []
| a == b = [xs !! a]
| otherwise = (drop a . take (b + 1)) xs
1 개의 선이 2 개의 점으로 3 개의 구간으로 나뉘어지고, List 중의 2 개의 요소를 교환한 결과는 첫 번째 구간에 2 번째 점을 합치고, 중간 구간을 합치고, 더욱 1 번째 점과 마지막 구간을 합치는 것입니다
([일장 함수형 사고 모드의 세례](/articles/일장 함수형 사고 모드의 세례/) 에서 발췌)
대응하는 JS 기술은 다음과 같습니다 (중요한 부분만):
function swap(i, j, xs) {
return xs.slice(0, i).concat([xs[j]]).concat(xs.slice(i + 1, j)).concat([xs[i]]).concat(xs.slice(j + 1));
}
매우 번거롭고, 효율도 높지 않습니다. 예를 들어 나무 구조의 시나리오에서는, 1 개의 노드를 수정하려면 새로운 나무를 1 개 작성할 필요가 있고, 그 옆의 노드를 수정하려면 다시 새로운 나무를 1 개 작성할 필요가 있습니다……단순히 모든 노드 값에 +1 하는 것만으로 n 개의 완전한 나무를 작성할 필요가 있습니다. 실제, 국소적인 수정에는 나무 전체를 재작성할 필요는 없고, 완전한 나무가 필요해질 때까지 기다렸다가 작성하는 것이 더 합리적입니다. 데이터 구조가 불변인 경우, 이것은 실현할 수 있을까요?
이.데이터 구조 중을 천삭하는
나무
먼저 이분 탐색 나무를 작성:
> let tree = fromList [7, 3, 1, 2, 6, 9, 8, 5]
> tree
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
(fromList 및 이분 탐색 나무의 실장은 [Monoid_Haskell 노트 9](/articles/monoid-haskell 노트 9/#articleHeader12) 에서)
나무 구조는 다음과 같습니다:
5
2
1
3
8
6
空
7
9
지정 노드를 수정하고 싶은 경우, 2 개의 것이 필요합니다: 위치 인덱스와 새로운 값. 위치 인덱스는 액세스 패스로 나타낼 수 있습니다. 예를 들어:
data Direction = L | R
type Path = [Direction]
따라서 modify 함수의 타입은 다음과 같아야 합니다:
modify :: Tree a -> Path -> Tree a -> Tree a
위치 인덱스로 목표 노드를 찾아, 새로운 값으로 교체할 뿐입니다. 이렇게 실장:
modify EmptyTree _ n = n
modify t [] n = n
modify (Node x l r) (d:ds) n
| d == L = Node x (modify l ds n) r
| d == R = Node x l (modify r ds n)
시유해 봅시다. 3 을 4 로 변경, 액세스 패스는 [L, R]:
> modify tree [L, R] (singleton 4)
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
예상대로입니다. 3 을 수정한 후 1 도 수정하고 싶은 경우는?
3 을 수정한 후의 완전한 나무를 입력으로, 근 노드로부터 1 을 찾아 0 으로 변경할 수 있습니다:
> modify (modify tree [L, R] (singleton 4)) [L, L] (singleton 0)
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
사용할 수 있지만, 2 개의 문제가 있습니다:
-
3을 수정한 후에 생성되는 완전한 나무는 여분 -
1은3의 왼쪽 형제로, 근으로부터 다시 찾을 필요는 없음
실제, 우리가 바라고 있는 것은:
-
중간의 여분인 완전한 나무를 생성하지 않고, 필요한 때 (예를 들어 일련의 수정 조작 후) 에만 완전한 나무를 생성
-
완전한 나무에 주목하지 않고, 국소적인 수정 (좌우 형제, 친급 자급) 을 편리하게 수행
1 개의 부분 나무에 대해 여러 번 수정을 수행하고, 수정 완료 후에 완전한 나무를 생성할 수 있게 하려면, 어떻게 하면 될까요?
국소적인 수정과 동시에 그 구조 컨텍스트 정보를 보유할 필요가 있습니다. 예를 들어 오른쪽 부분 나무를 수정하는 경우, 주목점은:
8
6
空
7
9
이분 나무의 경우, 구조 컨텍스트 정보는 2 개의 부분으로 구성됩니다. 친 노드와 형제 노드:
-- 친 노드
5
-- 왼쪽 형제
2
1
3
오른쪽 부분 나무에 이들 2 개의 정보를 더하면, 친 노드를 근으로 하는 완전한 부분 나무를 얻을 수 있습니다. 마찬가지로, 친 노드에도 그 친 노드와 형제 노드의 정보가 있으면, 더욱 위에 부분 나무를 회복할 수 있고, 근에 도달했을 때 완전한 나무를 얻을 수 있습니다. 실제, 충분한 구조 컨텍스트 정보를 가지고 있으면, 나무 중에서상하좌우 임의로 천삭 할 수 있고, 언제든지 멈춰서 완전한 나무를 재구축할 수 있습니다
먼저 구조 컨텍스트 정보를 정의:
data DirectionWithContext a = LeftSibling a (Tree a) | RightSibling a (Tree a) deriving (Show, Eq)
type PathWithContext a = [DirectionWithContext a]
type TreeWithContext a = (Tree a, PathWithContext a)
LeftSibling a (Tree a) 로 구조 컨텍스트 정보를 기록합니다. 그 중에서 a 는 친 노드의 값을 나타내고, Tree a 는 오른쪽 형제를 나타냅니다. 이것은 위에 부분 나무를 회복하기 위해 필요한 최소 정보로, 조금도 여분이 아닙니다. PathWithContext 는 이전의 Path 와 유사하고, 마찬가지로 액세스 패스를 나타내는 데 사용되지만, 패스의 각 스텝은 방향을 기록할 뿐만 아니라, 대응하는 컨텍스트 정보 (친 노드와 형제 노드를 포함) 도 기록합니다
다음으로「임의 천삭」을 실장:
goLeft ((Node x l r), ps) = (l, ((LeftSibling x r) : ps))
goRight ((Node x l r), ps) = (r, ((RightSibling x l) : ps))
goUp (l, ((LeftSibling x r):ps)) = (Node x l r, ps)
goUp (r, ((RightSibling x l):ps)) = (Node x l r, ps)
2 보 걸어 시유해 봅시다. 아직 이전의 시나리오로, 먼저 3 을 찾고, 다음으로 1 을 찾습니다. 즉 먼저 왼쪽으로 오른쪽으로, 다음으로 위로, 마지막으로 왼쪽으로:
> let cTree = (tree, [])
> let focus = goLeft (goUp (goRight (goLeft cTree)))
> fst focus
Node 1 EmptyTree EmptyTree
> snd focus
[LeftSibling 2 (Node 3 EmptyTree EmptyTree),LeftSibling 5 (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))]
1 이 소재하는 부분 나무를 찾고, 완전한 액세스 패스 (5 의 왼쪽 형제 2 의 왼쪽 형제) 를 보유하고 있습니다
완전한 나무�� 재구축하고 싶은 경우, 원래 길을 통해 나무의 근까지 돌아갈 뿐입니다. 이렇게:
backToRoot (t, []) = (t, [])
backToRoot t = backToRoot $ goUp t
검증:
> fst $ backToRoot focus
Node 5 (Node 2 (Node 1 EmptyTree EmptyTree) (Node 3 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
자유롭게 천삭할 수 있고, 언제든지 완전한 나무를 재구축할 수 있게 된 후, modify 는 매우 심플해집니다:
modifyTreeWithContext (EmptyTree, ps) _ = (EmptyTree, ps)
modifyTreeWithContext ((Node x l r), ps) v = ((Node v l r), ps)
다시 한번, 먼저 3 을 4 로 변경하고, 다음으로 1 을 0 으로 변경:
> let modified = modifyTreeWithContext (goLeft (goUp (modifyTreeWithContext (goRight (goLeft cTree)) 4))) 0
> fst modified
Node 0 EmptyTree EmptyTree
> fst $ backToRoot modified
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
이전의 결과와 일치합니다.あまりはっきり하지 않으므로, 툴 함수를 이용:
x +> f = f x
m = flip modifyTreeWithContext
간단하게 변환하여, 보다 자연스러운 방법으로 기술:
> fst $ backToRoot $ cTree +> goLeft +> goRight +> m 4 +> goUp +> goLeft +> m 0
Node 5 (Node 2 (Node 0 EmptyTree EmptyTree) (Node 4 EmptyTree EmptyTree)) (Node 8 (Node 6 EmptyTree (Node 7 EmptyTree EmptyTree)) (Node 9 EmptyTree EmptyTree))
나무의 근으로부터 시작하여, 왼쪽으로 걷고, 오른쪽으로 걷고, 4 로 변경하고, 더욱 위로 걷고, 왼쪽으로 걷고, 0 으로 변경합니다. 일련의조작은 매우 자연스럽고, 데이터 구조가 불변인 제한을 느끼지 않습니다
List
실제, List 도 이 보다 자연스러운 방법으로 조작할 수 있습니다. 구조 컨텍스트 정보를 가지고 있으면 될 뿐입니다
List 에게 있어, 좌우 2 개의 방향만으로, 나무의 시나리오보다 훨씬 심플합니다:
type ListWithContext a = ([a], [a])
좌우 천삭, 완전한 List 의 재구축, 요소의 수정은 모두 간단하게 실장:
goListRight (x:xs, ps) = (xs, x:ps)
goListLeft (xs, p:ps) = (p:xs, ps)
backToHead (xs, []) = (xs, [])
backToHead ls = backToHead $ goListLeft ls
modifyListWithContext ([], ps) _ = ([], ps)
modifyListWithContext (x:xs, ps) v = (v:xs, ps)
시유:
> let list = [1, 3, 5, 7, 8, 10, 12]
> let cList = (list, [])
> m = flip modifyListWithContext
> let modified = cList +> goListRight +> goListRight +> goListRight +> m 4 +> goListLeft +> goListLeft +> m 2
> modified
([2,5,4,8,10,12],[1])
> fst $ backToHead modified
[1,2,5,4,8,10,12]
제 4 의 요소를 4 로 변경하고, 제 2 의 요소를 2 로 변경했습니다. 이전의做法와 비교:
modifyList xs i x = take i xs ++ [x] ++ drop (i + 1) xs
> modifyList (modifyList list 1 2) 3 4
[1,2,5,4,8,10,12]
양자의 차이는, 전자는직관적인 방법으로 요소를遍历, 수정하는 것을 서포트 하고, 불변의 제한을 감지하지 않는 것입니다
삼.Zipper 란 무엇인가
위에서 정의한 TreeWithContext, ListWithContext 는 모두 Zipper 입니다. 정식 기술은 다음과 같습니다:
The Zipper is an idiom that uses the idea of "context" to the means of manipulating locations in a data structure.
「컨텍스트」의 사상을 사용하여 데이터 구조 중의 위치를 처리합니다. 습관적인 부르는 방법은 Zipper(지퍼) 입니다. 왜「지퍼」라고 부를까요?
ListWithContext 는 지퍼로, 매우 형상적입니다. List 를 지퍼로 간주하고, 자물쇠는 1 개의 커서 (cursor, 또는 포인터로 이해) 로, 커서가 가리키는 위치의 요소가 현재 요소로, 나머지 요소는 그 컨텍스트입니다. 자물쇠를 오른쪽으로 열어, 왼쪽으로 당깁니다 (파일 봉투의 봉인을 당기는 동작을 상상). 데이터 구조 조작에 대응 하면, 오른쪽으로 새로운 요소를 액세스하고, 가장 오른쪽 끝까지 당기는 것이遍历, 왼쪽으로 역사 요소를 액세스하고, 가장 왼쪽 끝까지 당기는 것이 완전한 List 의 재구축입니다
마찬가지로, TreeWithContext 도 이렇게 이해할 수 있습니다. 왼쪽으로 오른쪽으로 열어, 새로운 요소를 액세스하고, 위로 당겨, 역사 요소를 액세스하고, 탑까지 당기는 것이 완전한 나무의 재구축입니다
구체적으로는, Zipper 는 그 통용 정도에 근거하여 분류할 수 있습니다:
-
특정 데이터 구조용 Zipper: 예를 들어 ListZipper, TravelTree, TravelBTree
-
통용 Zipper: 예를 들어 Zipper Monad, Generic Zipper
구체 데이터 구조용 Zipper 는 이미 2 개 실장했습니다 (xxxWithContext 를 Zipper 로 바꿀 뿐). 대략적인思路는:
Zipper, the functional cursor into a data structure, is itself a data structure, derived from the original one. The derived data type D' for the recursive data type D is D with exactly one hole. Filling-in the hole -- integrating over all positions of the hole -- gives the data type D back.
주어진 데이터 구조로부터 Zipper 구조를 파생시킵니다. 구체做法는 원래 데이터 구조를 2 개의 부분으로 분할하고, 부분 구조 (값으로서) 와「구멍」붙이 구조 (값의 구조 컨텍스트로서, 「구멍」이 있는 것은 원래 완전 구조로부터 값이 소재하는 부분 구조를 파냈기 때문) 로, 양자를拼치면 마침내 원래 완전 구조가 됩니다. 아래 그림과 같습니다:
[caption id="attachment_1762" align="alignnone" width="620"]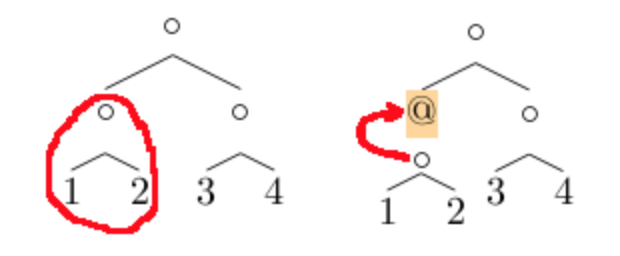 zipper-hole[/caption]
zipper-hole[/caption]
Zipper Monad
The Zipper Monad is a generic monad for navigating around arbitrary data structures. It supports movement, mutation and classification of nodes (is this node the top node or a child node?, etc).
이동, 수정 외에, 노드 타입을 구별할 수도 있습니다. 기본 실장은 다음과 같습니다:
import Control.Monad.State
data Loc c a = Loc { struct :: a,
cxt :: c }
deriving (Show, Eq)
newtype Travel loc a = Travel { unT :: State loc a }
deriving (Functor, Monad, MonadState loc, Eq)
구조 + 컨텍스트 = 위치 로, 몇 개의 monadic 함수를 통해遍历, 수정:
traverse :: Loc c a -- starting location (initial state)
-> Travel (Loc c a) a -- locational computation to use
-> a -- resulting substructure
traverse start tt = evalState (unT tt) start
-- modify the substructure at the current node
modifyStruct :: (a -> a) -> Travel (Loc c a) a
modifyStruct f = modify editStruct >> liftM struct get where
editStruct (Loc s c) = Loc (f s) c
-- put a new substructure at the current node
putStruct :: a -> Travel (Loc c a) a
putStruct t = modifyStruct $ const t
-- get the current substructure
getStruct :: Travel (Loc c a) a
getStruct = modifyStruct id -- works because modifyTree returns the 'new' tree
P.S. 원래 Zipper 용으로 설계된 통용 Monad 였지만, 결���로서 필요하지 않은 것이わかりました:
It's designed for use with The Zipper but in fact there is no requirement to use such an idiom.
현재 어떻게 나무 구조 전용으로 사용되고 있는 것 같습니다:
Zipper monad is a monad which implements the zipper for binary trees.
Generic Zipper
또 하나의 통용 Zipper:
Generic Zipper: the context of a traversal
Zipper 를遍历 조작의 컨텍스트로 간주합니다. 이전의思路와는 다릅니다:
We advocate a different view, emphasizing not the result of navigating through a data structure to a desired item and extracting it, but the process of navigation.
데이터 구조 중의某个위치에 이동하고,想要的것을 액세스하는 것을 강조하지 않고, 이동의 프로세스만을关注 합니다:
Each data structure comes with a method to enumerate its components, representing the data structure as a stream of the nodes visited during the enumeration. To let the user focus on a item and submit an update, the enumeration process should yield control to the user once it reached an item.
遍历의 각도에서 보면, 데이터 구조는枚擧過程中에 액세스된 노드가 형성하는 스트림입니다. 따라서,某个노드를关注하여 업데이트하고 싶은 경우, 枚擧프로세스는 그 노드에 액세스했을 때 제어권을 사용자에게 돌려줘야 합니다. 예를 들어:
Current element: 1
Enter Return, q or the replacement value:
Current element: 2
Enter Return, q or the replacement value:
Current element: 6
Enter Return, q or the replacement value:
42
Current element: 24
Enter Return, q or the replacement value:
q
Done:
fromList [(1,1),(2,2),(3,42),(4,24),(5,120),(6,720),(7,5040),(8,40320),(9,362880),(10,3628800)]
(상세는 ZipperTraversable 참조)
P.S. 이思路는 [JS 중의 제네레이터](/articles/javascript 生成器/#articleHeader8) 와 매우 유사합니다. 매보 걸을 때마다 한숨 쉬고 요소를 수정할 필요가 있는지, 또는遍历를 정지할지 봅니다:
As Chung-chieh Shan aptly put it, 'zipper is a suspended walk.'
아직 댓글이 없습니다